Phantom Rows
The so-called phantom problem occurs within a transaction when the same query produces different sets of rows at different times. For example, if a SELECT is executed twice, but returns a row the second time that was not returned the first time, the row is a “phantom” row.
Suppose that there is an index on the id column of the child table and that you want to read and lock all rows from the table having an identifier value larger than 100, with the intention of updating some column in the selected rows later:
SELECT * FROM child WHERE id > 100 FOR UPDATE;
The query scans the index starting from the first record where id is bigger than 100. Let the table contain rows having id values of 90 and 102. If the locks set on the index records in the scanned range do not lock out inserts made in the gaps (in this case, the gap between 90 and 102), another session can insert a new row into the table with an id of 101. If you were to execute the same SELECT within the same transaction, you would see a new row with an id of 101 (a “phantom”) in the result set returned by the query. If we regard a set of rows as a data item, the new phantom child would violate the isolation principle of transactions that a transaction should be able to run so that the data it has read does not change during the transaction.
To prevent phantoms, InnoDB uses an algorithm called next-key locking that combines index-row locking with gap locking. InnoDB performs row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. In addition, a next-key lock on an index record also affects the “gap” before the index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on record R in an index, another session cannot insert a new index record in the gap immediately before R in the index order.
When InnoDB scans an index, it can also lock the gap after the last record in the index. Just that happens in the preceding example: To prevent any insert into the table where id would be bigger than 100, the locks set by InnoDB include a lock on the gap following id value 102.
You can use next-key locking to implement a uniqueness check in your application: If you read your data in share mode and do not see a duplicate for a row you are going to insert, then you can safely insert your row and know that the next-key lock set on the successor of your row during the read prevents anyone meanwhile inserting a duplicate for your row. Thus, the next-key locking enables you to “lock” the nonexistence of something in your table.
MySQL 是怎么解决幻读的?
MySQL InnoDB 引擎的默认隔离级别虽然是「可重复读」,但是它很大程度上避免幻读现象(并不是完全解决了,下面会聊),解决的方案有两种:
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select … for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select … for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。
快照读时,如何避免幻读的?
可重复读隔离级是由 MVCC(多版本并发控制)实现的,实现的方式是开始事务后(执行 begin 语句后),在执行第一个查询语句后,会创建一个 Read View,后续的查询语句利用这个 Read View,通过这个 Read View 就可以在 undo log 版本链找到事务开始时的数据,所以事务过程中每次查询的数据都是一样的,即使中途有其他事务插入了新纪录,是查询不出来这条数据的,所以就很好了避免幻读问题。
做个实验,数据库表 t_stu 如下,其中 id 为主键。
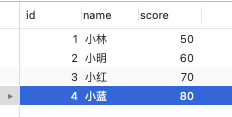
然后在可重复读隔离级别下,有两个事务的执行顺序如下:

从这个实验结果可以看到,即使事务 B 中途插入了一条记录,事务 A 前后两次查询的结果集都是一样的,并没有出现所谓的幻读现象。
当前读时,如何避免幻读的?
MySQL 里除了普通查询是快照读,其他都是当前读,比如 update、insert、delete,这些语句执行前都会查询最新版本的数据,然后再做进一步的操作。
这很好理解,假设你要 update 一个记录,另一个事务已经 delete 这条记录并且提交事务了,这样不是会产生冲突吗,所以 update 的时候肯定要知道最新的数据。
另外,select ... for update 这种查询语句是当前读,每次执行的时候都是读取最新的数据。
接下来,我们假设select ... for update当前读是不会加锁的(实际上是会加锁的),再做一遍实验。
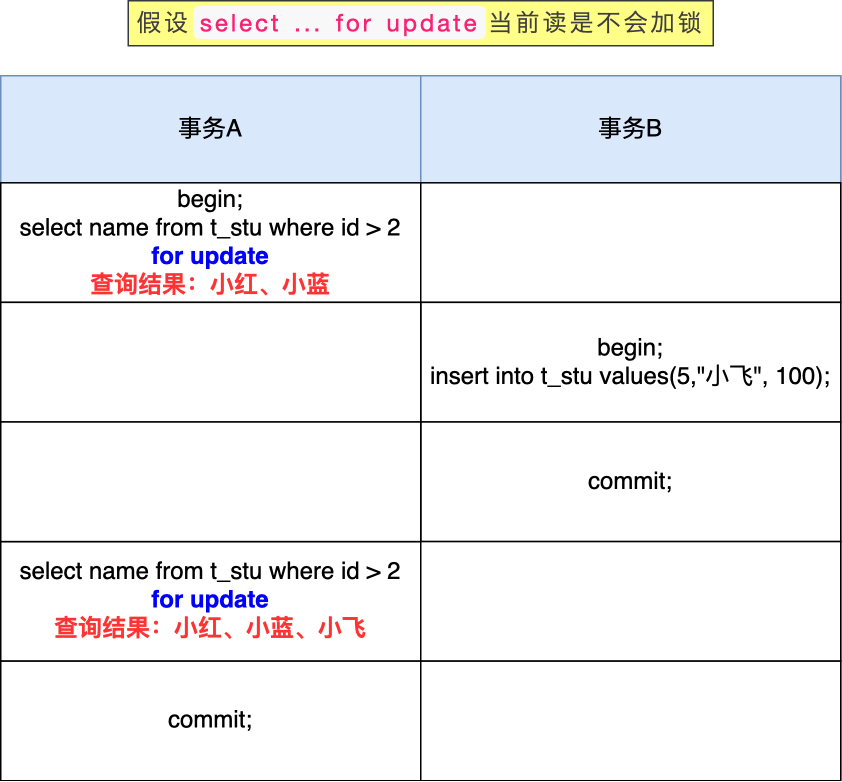
这时候,事务 B 插入的记录,就会被事务 A 的第二条查询语句查询到(因为是当前读),这样就会出现前后两次查询的结果集合不一样,这就出现了幻读。
所以,Innodb 引擎为了解决「可重复读」隔离级别使用「当前读」而造成的幻读问题,就引出了间隙锁。
假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生。
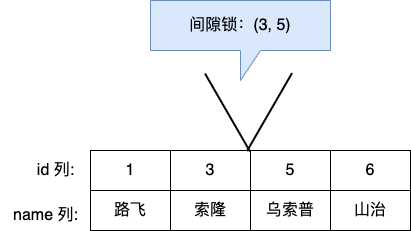
举个具体例子,场景如下:
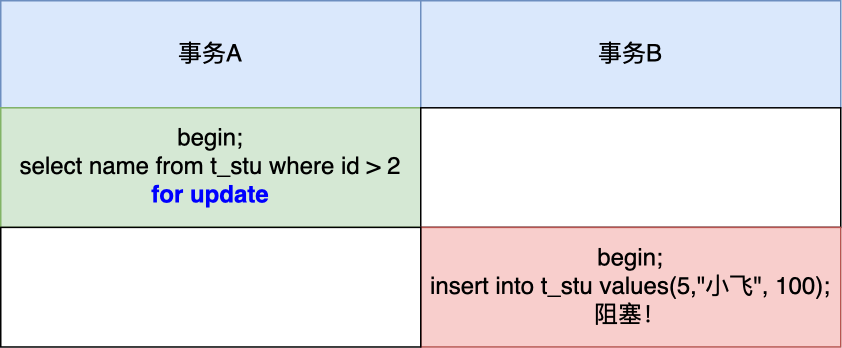
事务 A 执行了这面这条锁定读语句后,就在对表中的记录加上 id 范围为 (2, +∞] 的 next-key lock(next-key lock 是间隙锁+记录锁的组合)。
然后,事务 B 在执行插入语句的时候,判断到插入的位置被事务 A 加了 next-key lock,于是事物 B 会生成一个插入意向锁,同时进入等待状态,直到事务 A 提交了事务。这就避免了由于事务 B 插入新记录而导致事务 A 发生幻读的现象。
幻读被完全解决了吗?
可重复读隔离级别下虽然很大程度上避免了幻读,但是还是没有能完全解决幻读。
我举例一个可重复读隔离级别发生幻读现象的场景。
第一个发生幻读现象的场景
还是以这张表作为例子:
事务 A 执行查询 id = 5 的记录,此时表中是没有该记录的,所以查询不出来。
# 事务 A
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t_stu where id = 5;
Empty set (0.01 sec)
然后事务 B 插入一条 id = 5 的记录,并且提交了事务。
# 事务 B
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t_stu values(5, '小美', 18);
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
此时,事务 A 更新 id = 5 这条记录,对没错,事务 A 看不到 id = 5 这条记录,但是他去更新了这条记录,这场景确实很违和,然后再次查询 id = 5 的记录,事务 A 就能看到事务 B 插入的纪录了,幻读就是发生在这种违和的场景。
# 事务 A
mysql> update t_stu set name = '小林coding' where id = 5;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t_stu where id = 5;
+----+--------------+------+
| id | name | age |
+----+--------------+------+
| 5 | 小林coding | 18 |
+----+--------------+------+
1 row in set (0.00 sec)
整个发生幻读的时序图如下:
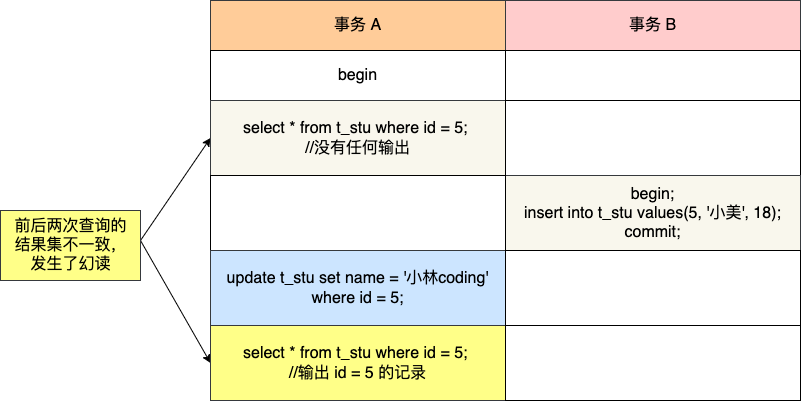
在可重复读隔离级别下,事务 A 第一次执行普通的 select 语句时生成了一个 ReadView,之后事务 B 向表中新插入了一条 id = 5 的记录并提交。接着,事务 A 对 id = 5 这条记录进行了更新操作,在这个时刻,这条新记录的 trx_id 隐藏列的值就变成了事务 A 的事务 id,之后事务 A 再使用普通 select 语句去查询这条记录时就可以看到这条记录了,于是就发生了幻读。
因为这种特殊现象的存在,所以我们认为 MySQL Innodb 中的 MVCC 并不能完全避免幻读现象。
第二个发生幻读现象的场景
除了上面这一种场景会发生幻读现象之外,还有下面这个场景也会发生幻读现象。
- T1 时刻:事务 A 先执行「快照读语句」:select * from t_test where id > 100 得到了 3 条记录。
- T2 时刻:事务 B 往插入一个 id= 200 的记录并提交;
- T3 时刻:事务 A 再执行「当前读语句」 select * from t_test where id > 100 for update 就会得到 4 条记录,此时也发生了幻读现象。
要避免这类特殊场景下发生幻读的现象的话,就是尽量在开启事务之后,马上执行 select … for update 这类当前读的语句,因为它会对记录加 next-key lock,从而避免其他事务插入一条新记录。
Reference
- https://dev.mysql.com/doc/refman/8.0/en/innodb-next-key-locking.html
- https://xiaolincoding.com/mysql/transaction/phantom.html
- https://xiaolincoding.com/mysql/lock/lock_phantom.html
- https://stackoverflow.com/questions/5444915/how-to-produce-phantom-read-in-repeatable-read-mysql