Background
我们都知道,事务的四大特性里面有一个是持久性(durability) ,具体来说就是
- 只要事务提交成功,那么对数据库做的修改就会被永久保存下来了,不可能因为任何原因再回到原来的状态 。
那么 MySQL 是如何保证一致性的呢?最简单的做法是在每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。但是这么做会有严重的性能问题,主要体现在两个方面:
- 因为 InnoDB 是以**页(page)**为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!
- 一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,因而是随机 I/O(random I/IO) ,随机 I/O写入性能相对很差
因此 MySQL设计了 Redo Log, 具体来说就是只记录事务对数据页做了哪些修改,这样就能在尽可能的提高性能的同时,保证持久性(durability)。注意到,写入 Redo Log 写入位于磁盘中的 Redo Log file 是顺序 I/O(即通过append-only的方式把修改追加到 Redo Log file 中) ,而真正去磁盘更新存储的数据库数据是随机I/O。
InnoDB修改数据的流程
In order to make the database resilient to crashes, it is common for B-tree implementations to include an additional data structure on disk: a write-ahead log (WAL, also known as a Redo Log). This is an append-only file to which every B-tree modification must be written before it can be applied to the pages of the tree itself. When the database comes back up after a crash, this log is used to restore the B-tree back to a consistent state
首先我们先明确一下InnoDB的对于事务中修改数据的流程。
当我们想要修改DB上某一行数据的时候(执行一条 DML 语句),InnoDB是对位于从磁盘读取到内存的 Buffer Pool的数据进行修改(我们这里假设这个数据已经存在于 Buffer Pool,在一般情况中,当然可能出现cache miss,因而不在 Buffer Pool 中),即这个时候数据的更新只在内存中被存储,因而和磁盘中数据就存在了差异,我们称这种有差异的数据为脏页(dirty page)。
后续在某个时机(后面会详细介绍)再一次性将多个数据修改操作记录追加写到磁盘中的 Redo Log file 的尾部。这种 先写日志,再写磁盘 的技术就是 MySQL 里经常说到的 WAL (Write-Ahead Logging) 技术。
在计算机操作系统中,位于 user space 中的缓冲区数据一般情况下是无法直接写入磁盘的,中间必须经过操作系统 kernel space 的 OS Buffer 。因此, Log Buffer 写入 Redo Log file 实际上是先写入 内存中的 Log Buffer,kernel将其copy到 OS Buffer ,然后再通过系统调用 fsync() 将其刷到磁盘中的 Redo Log file 中,过程如下:
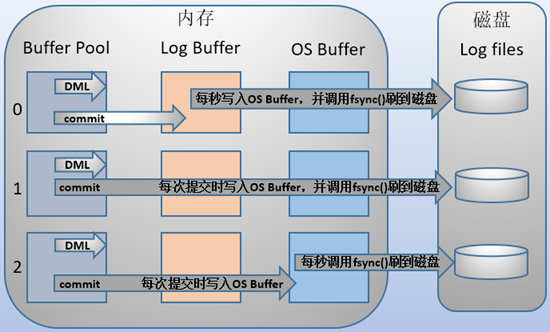
LSN (Log Sequence Number)
LSN实际上就是InnoDB使用的一个版本标记的计数,它是一个单调递增的值。数据页和Redo Log都有各自的LSN。我们可以根据数据页中的LSN值和Redo Log中LSN的值判断需要恢复的Redo Log的位置和大小。
宕机恢复
DB宕机后重启,InnoDB会首先去查看数据页中的LSN的数值。这个值代表数据页被刷新回磁盘的LSN的大小。然后再去查看Redo Log的LSN的大小。如果数据页中的LSN值大说明数据页领先于Redo Log刷新回磁盘,不需要进行恢复。反之需要从Redo Log中恢复数据。
master thread
这里我想简单介绍一下master thread,这是InnoDB一个在后台运行的主线程,从名字就能看出这个线程相当的重要。它做的主要工作包括但不限于:刷新日志缓冲,合并插入缓冲,刷新脏页等。master thread大致分为每秒运行一次的操作和每10秒运行一次的操作。master thread中刷新数据,属于checkpoint的一种。所以如果在master thread在刷新日志的间隙,DB出现故障那么将丢失掉这部分数据。
Redo Logs
The redo log is a disk-based data structure used during crash recovery to correct data written by incomplete transact I/O ns. During normal operat I/O ns, the Redo Log encodes requests to change table data that result from SQL statements or low-level API calls. Modificat I/O ns that did not finish updating the data files before an unexpected shutdown are replayed automatically during initializat I/O n, and before connect I/O ns are accepted.
Refer to https://dev.MySQL.com/doc/refman/8.0/en/innodb-redo-log.html
Redo Log 工作原理
Redo Log就是存储了在事务中数据被修改后的值。当我们提交一个事务时,InnoDB会先去把要修改数据的记录存入 Redo Log block 中,而 Redo Log block 位于 Log buffer 中(处于内存中),然后再去修改 Buffer Pool 里真正存储数据的页(处于内存中)。
Redo Log 的刷盘机制
我们着重看看Redo Log的内容怎么从 Log buffer 被最终追加(append)同步到磁盘的。
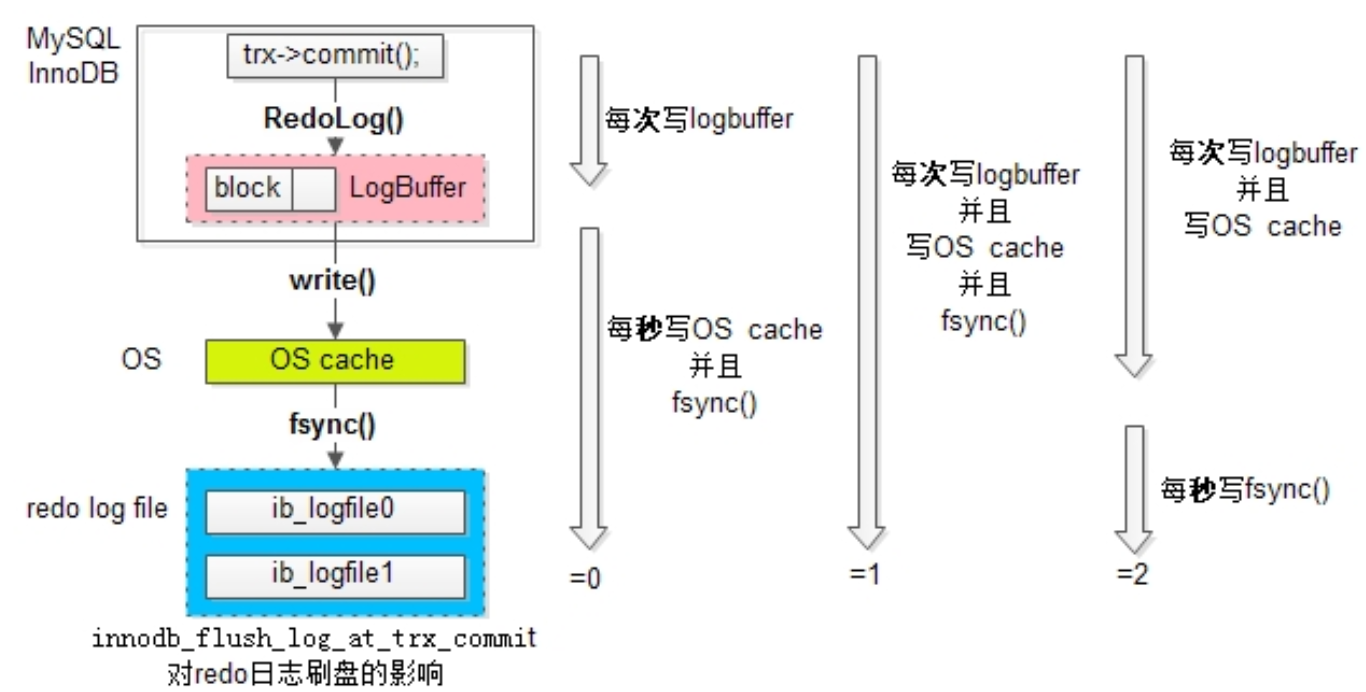
InnoDB写入磁盘的策略可以通过 innodb_flush_log_at_trx_commit 这个参数来控制:
- 0
- With a setting of 0, logs are written and flushed to disk once per second. Transactions for which logs have not been flushed can be lost in a crash.
- 性能较好,但可能会丢失掉master thread还没刷新进磁盘部分的数据。
- 如果数据库崩溃,有一秒的数据丢失。
- 1
- The default setting of 1 is required for full ACID compliance. Logs are written and flushed to disk at each transaction commit.
- 当然是最安全的,但是数据库性能会受一定影响。
- 2
- With a setting of 2, logs are written after each transaction commit and flushed to disk once per second. Transactions for which logs have not been flushed can be lost in a crash.
- 如果操作系统崩溃,最多有一秒的数据丢失
For settings 0 and 2, once-per-second flushing is not 100% guaranteed. Flushing may occur more frequently due to DDL changes and other internal InnoDB activities that cause logs to be flushed independently of the innodb_flush_log_at_trx_commit setting, and sometimes less frequently due to scheduling issues. If logs are flushed once per second, up to one second of transact I/O ns can be lost in a crash. If logs are flushed more or less frequently than once per second, the amount of transact I/O ns that can be lost varies accordingly.
Refer to https://dev.MySQL.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
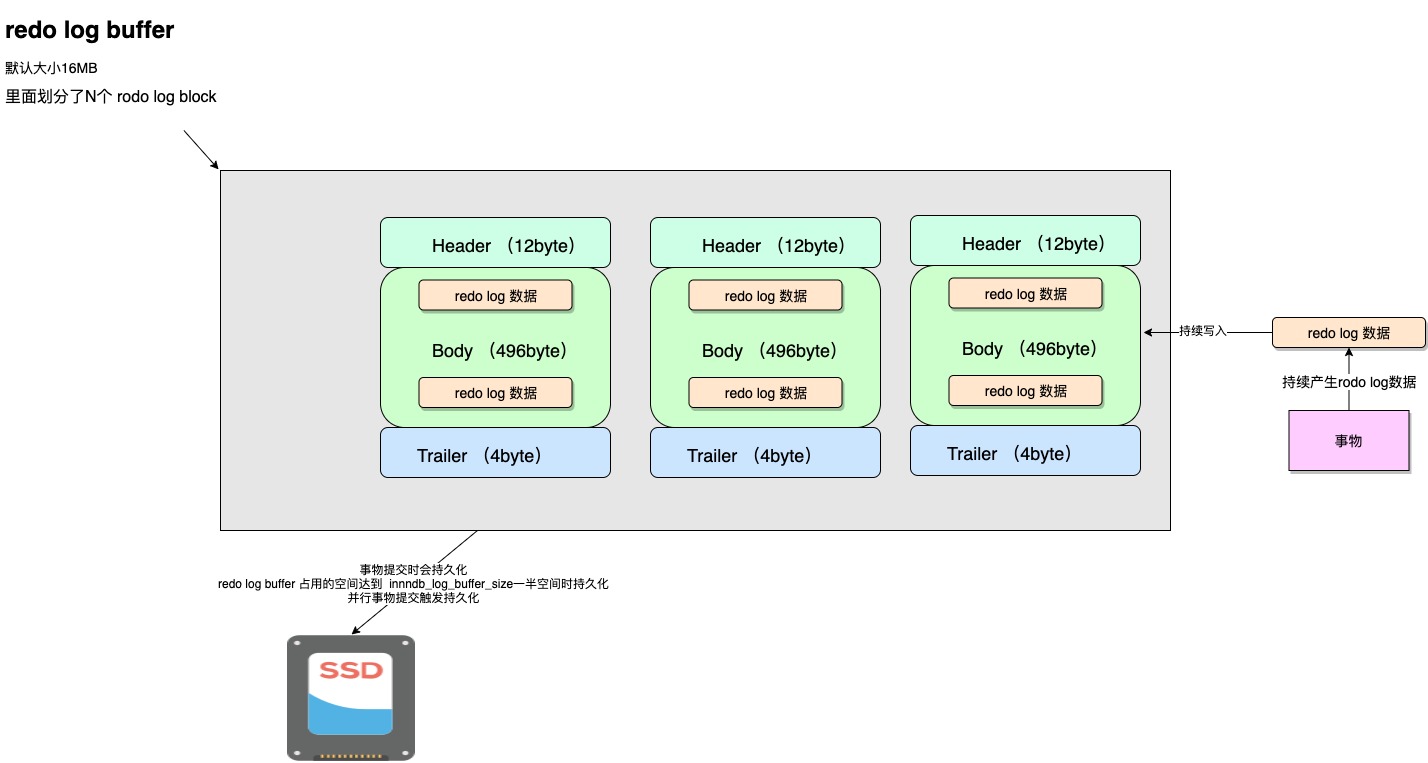
Redo Log block
首先你得知道,Redo Log 并不是一条条直接写入磁盘中去的!
在MySQL的设定中,Redo Log 是按块(block),一块一块的写入到磁盘中去的。
你可以类比一下数据是按页为单位来组织的,就更容易理解为啥 Redo Log 要按照block来组织redo。
本质上就是两个字:优化
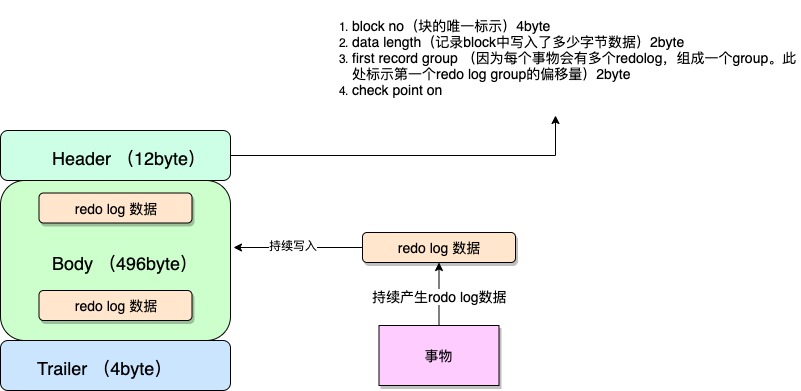
log block长成下面这这样:分成Header、Body、Trailer三部分 总共512字节。而且是覆盖写入。
Redo Log 的 buffer - Log Buffer
这个 Log Buffer 中会划分出多个Redo Log block。Log Buffer 占用一块连续的内存空间。
Log buffer size is defined by the innodb_log_buffer_size variable. The default size is 16MB.
The contents of the log buffer are per I/O dically flushed to disk. A large log buffer enables large transact I/O ns to run without the need to write Redo Log data to disk before the transact I/O ns commit. Thus, if you have transact I/O ns that update, insert, or delete many rows, increasing the size of the log buffer saves disk I/O.
The innodb_flush_log_at_trx_commit variable controls how the contents of the log buffer are written and flushed to disk. The innodb_flush_log_at_timeout variable controls log flushing frequency.
Redo Log Files
The size and number of Redo Log files are configured using the innodb_log_file_size and innodb_log_files_in_group configuration options. For information about modifying an existing Redo Log file configuration, see Changing the Number or Size of Redo Log Files.
By default, the Redo Log is physically represented on disk by two files named ib_logfile0 and ib_logfile1. MySQL writes to the Redo Log files in a circular fashion. Data in the Redo Log is encoded in terms of records affected; this data is collectively referred to as redo. The passage of data through the Redo Log is represented by an ever-increasing LSN value.
Size of Redo Log Files
To change the number or the size of Redo Log files, perform the following steps:
- Stop the MySQL server and make sure that it shuts down without errors.
- Edit
my.cnfto change the log file configuration. To change the log file size, configureinnodb_log_file_size. To increase the number of log files, configureinnodb_log_files_in_group. - Start the MySQL server again.
If InnoDB detects that the innodb_log_file_size differs from the Redo Log file size, it writes a log checkpoint, closes and removes the old log files, creates new log files at the requested size, and opens the new log files.
Reference
- https://dev.MySQL.com/doc/refman/8.0/en/innodb-redo-log.html
- https://dev.MySQL.com/doc/refman/8.0/en/innodb-recovery.html
- https://dev.MySQL.com/doc/refman/8.0/en/innodb-redo-log-buffer.html
- https://dev.mysql.com/doc/refman/8.0/en/optimizing-innodb-logging.html
- https://dev.mysql.com/doc/refman/8.0/en/innodb-redo-log.html
- Designing Data Intensive Applications
- https://zhuanlan.zhihu.com/p/35355751
- https://www.cnblogs.com/ZhuChangwu/p/14096575.html
- https://en.wikipedia.org/wiki/Redo_log