MySQL Replication
Replication enables data from one MySQL database server (known as a source) to be copied to one or more MySQL database servers (known as replicas). Replication is asynchronous by default; replicas do not need to be connected permanently to receive updates from a source. Depending on the configuration, you can replicate all databases, selected databases, or even selected tables within a database.
Why
One of the main purposes of going for a master-slave replication system is to have a standby system with a live backup that can be promoted as the master when the original master server crashes. Apart from this, there are several benefits as outlined below:
Advantages of replication in MySQL include:
- Scalability - spreading the load among multiple replicas to improve performance. In this environment, all writes and updates must take place on the source server. Reads, however, may take place on one or more replicas. This model can improve the performance of writes (since the source is dedicated to updates), while dramatically increasing read speed across an increasing number of replicas.
- Data security - because the replica can pause the replication process, it is possible to run backup services on the replica without corrupting the corresponding source data.
- Analytics - live data can be created on the source, while the analysis of the information can take place on the replica without affecting the performance of the source.
- Long-distance data distribution - you can use replication to create a local copy of data for a remote site to use, without permanent access to the source.
Topology for MySQL Replication
我们基于 binlog 可以复制出一台 MySQL 服务器,也可以复制出多台,取决于我们想实现什么功能。主流的系统架构有如下几种方式:
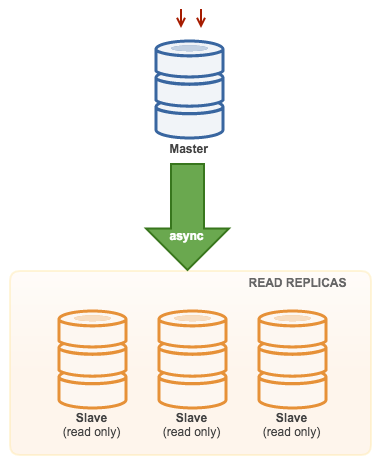
Master with Slaves (Single Replication)
一主一从和一主多从是最常见的主从架构方式,一般实现主从配置或者读写分离都可以采用这种架构。
如果是一主多从的模式,当 Slave 增加到一定数量时,Slave 对 Master 的负载以及网络带宽都会成为一个严重的问题。
Multiple Masters to Single Slave (Multi-Source Replication)
Multi-Source Replication enables a replication slave to receive transactions from multiple sources simultaneously. Multi-source replication can be used to backup multiple servers to a single server, to merge table shards, and consolidate data from multiple servers to a single server.
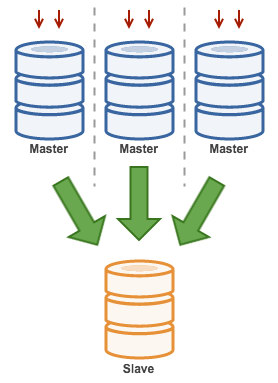
MySQL and MariaDB have different implementations of multi-source replication, where MariaDB must have GTID with gtid-domain-id configured to distinguish the originating transactions while MySQL uses a separate replication channel for each master the slave replicates from. In MySQL, masters in a multi-source replication topology can be configured to use either global transaction identifier (GTID) based replication, or binary log position-based replication.
Master–master or Active/active(Circular Replication)
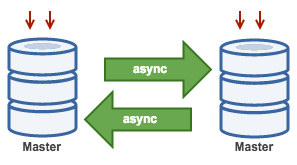
理论上跟主从一样,但是两个MySQL服务器互做对方的从,任何一方有变更,都会复制对方的数据到自己的数据库。
双主适用于写压力比较大的业务场景,或者 DBA 做维护需要主从切换的场景,通过双主架构避免了重复搭建从节点的麻烦。(主从相互授权连接,读取对方binlog日志并更新到本地数据库的过程;只要对方数据改变,自己就跟着改变)
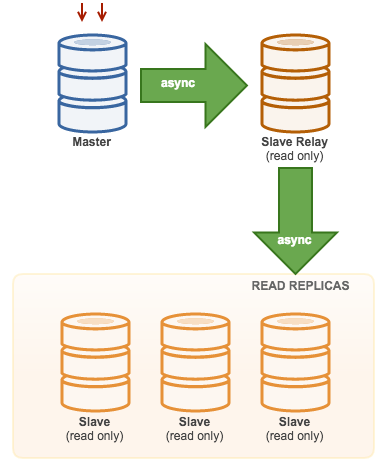
Master with Relay Slaves (Chain Replication)
级联模式下因为涉及到的 slave 节点很多,所以如果都连在 master 上对主节点的压力肯定是不小的。所以部分 slave 节点连接到它上一级的从节点上。这样就缓解了主节点的压力。
级联复制解决了一主多从场景下多个从节点复制对主节点的压力,带来的弊端就是数据同步延迟比较大。
Master with Backup Master (Multiple Replication)
The master pushes changes to a backup master and to one or more slaves. Semi-synchronous replication is used between master and backup master. Master sends update to backup master and waits with transaction commit. Backup master gets update, writes to its relay log and flushes to disk. Backup master then acknowledges receipt of the transaction to the master, and proceeds with transaction commit. Semi-sync replication has a performance impact, but the risk for data loss is minimized.
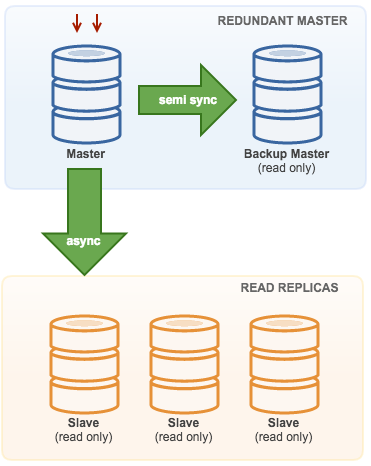
This topology works well when performing master failover in case the master goes down. The backup master acts as a warm-standby server as it has the highest probability of having up-to-date data when compared to other slaves.
Replication Scheme
异步模式(async-mode)
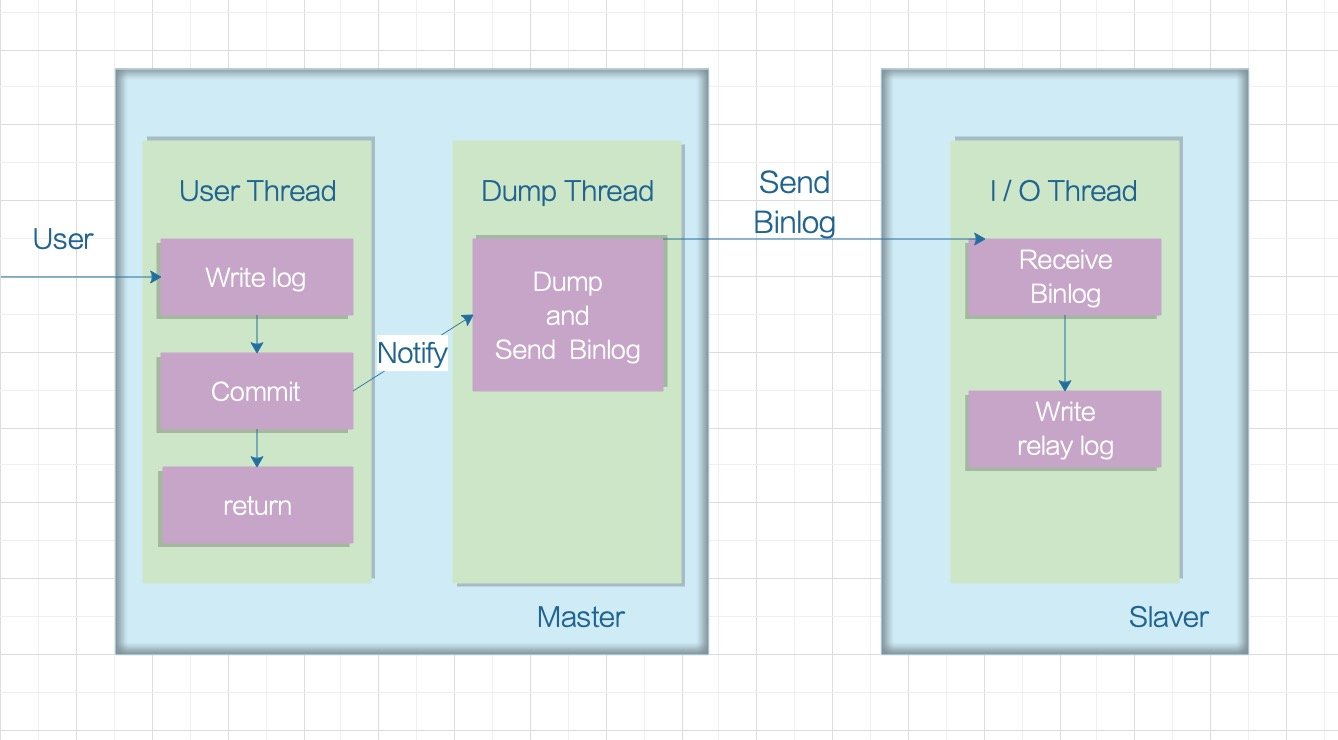
MySQL Replication by default is asynchronous. This is the oldest, most popular and widely deployed replication scheme. With asynchronous replication, the master writes events to its binary log and slaves request them when they are ready. There is no guarantee that any event will ever reach any slave. It’s a loosely coupled master-slave relationship, where:
- Master does not wait for Slave.
- Slave determines how much to read and from which point in the binary log.
- Slave can be arbitrarily behind master in reading or applying changes.
If the master crashes, transactions that it has committed might not have been transmitted to any slave. Consequently, failover from master to slave in this case may result in failover to a server that is missing transactions relative to the master.
Asynchronous replication provides lower write latency, since a write is acknowledged locally by a master before being written to slaves. It is great for read scaling as adding more replicas does not impact replication latency. Good use cases for asynchronous replication include deployment of read replicas for read scaling, live backup copy for disaster recovery and analytics/reporting.
Refer to https://dev.mysql.com/doc/refman/8.0/en/replication-asynchronous-connection-failover.html
半同步模式(semi-sync)
Refer to https://dev.mysql.com/doc/refman/8.0/en/replication-semisync.html
Background
MySQL replication by default is asynchronous. The source writes events to its binary log and replicas request them when they are ready. The source does not know whether or when a replica has retrieved and processed the transactions, and there is no guarantee that any event ever reaches any replica. With asynchronous replication, if the source crashes, transactions that it has committed might not have been transmitted to any replica. Failover from source to replica in this case might result in failover to a server that is missing transactions relative to the source.
semi-sync
Semi-synchronous replication falls between asynchronous and fully synchronous replication. The source waits until at least one replica has received and logged the events (the required number of replicas is configurable), and then commits the transaction. The source does not wait for all replicas to acknowledge receipt, and it requires only an acknowledgement from the replicas, not that the events have been fully executed and committed on the replica side. Semisynchronous replication therefore guarantees that if the source crashes, all the transactions that it has committed have been transmitted to at least one replica.
Compared to asynchronous replication, semisynchronous replication provides improved data integrity, because when a commit returns successfully, it is known that the data exists in at least two places. Until a semisynchronous source receives acknowledgment from the required number of replicas, the transaction is on hold and not committed.
Compared to fully synchronous replication, semi-synchronous replication is faster, because it can be configured to balance your requirements for data integrity (the number of replicas acknowledging receipt of the transaction) with the speed of commits, which are slower due to the need to wait for replicas.
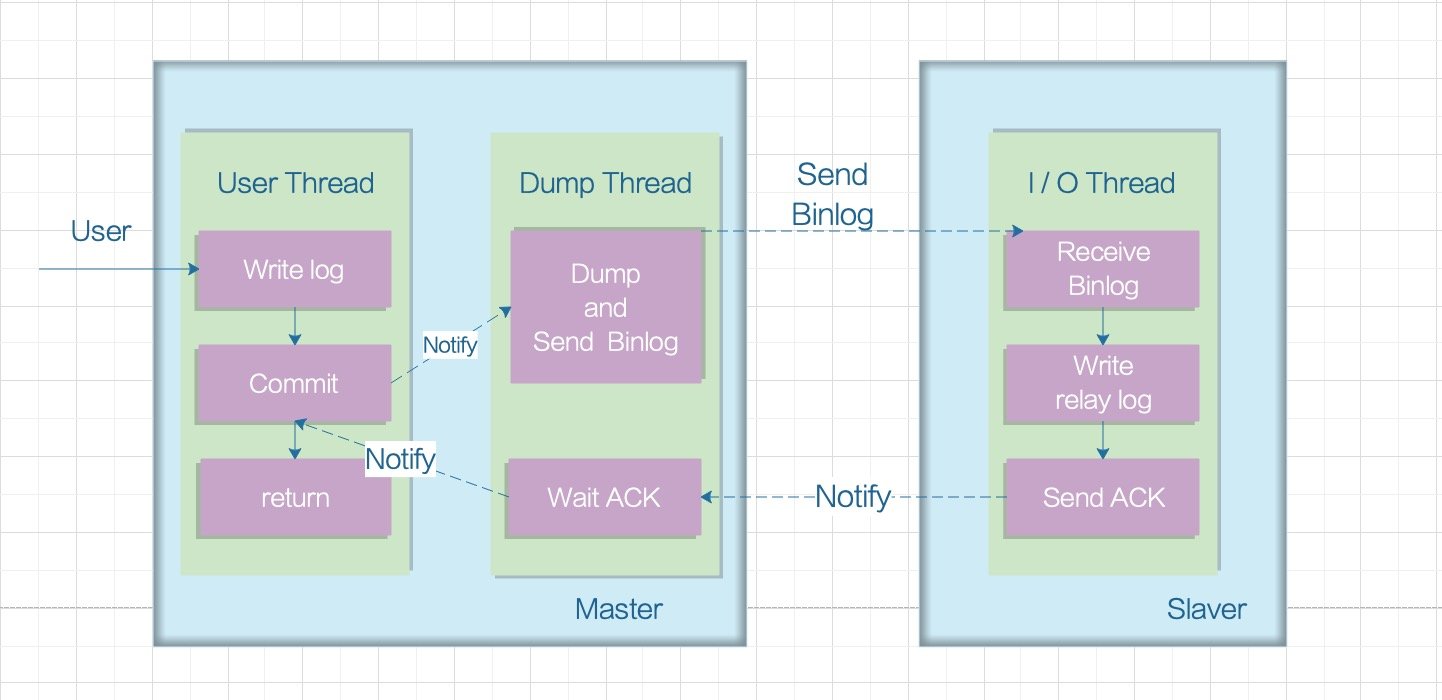
Characteristics
Semisynchronous replication between a source and its replicas operates as follows:
- A replica indicates whether it is semisynchronous-capable when it connects to the source.
- If semisynchronous replication is enabled on the source side and there is at least one semisynchronous replica, a thread that performs a transaction commit on the source blocks and waits until at least one semisynchronous replica acknowledges that it has received all events for the transaction, or until a timeout occurs.
- The replica acknowledges receipt of a transaction’s events only after the events have been written to its relay log and flushed to disk.
- If a timeout occurs without any replica having acknowledged the transaction, the source reverts to asynchronous replication. When at least one semisynchronous replica catches up, the source returns to semisynchronous replication.
- Semisynchronous replication must be enabled on both the source and replica sides. If semisynchronous replication is disabled on the source, or enabled on the sour
Setup and Config
https://dev.mysql.com/doc/refman/8.0/en/replication-semisync-installation.html
全同步模式(sync)
With fully synchronous replication, when a source commits a transaction, all replicas have also committed the transaction before the source returns to the session to the client that performed the transaction. Fully synchronous replication means failover from the source to any replica is possible at any time. The drawback of fully synchronous replication is that there might be a lot of delay to complete a transaction.
How to Achieve Replication
Recent versions of MySQL support two methods for replicating data. The difference between these replication methods has to do with how replicas track which database events from the source they’ve already processed.
The traditional method is based on replicating events from the source’s binary log, and requires the log files and positions in them to be synchronized between source and replica. The newer method based on global transaction identifiers (GTIDs) is transactional and therefore does not require working with log files or positions within these files, which greatly simplifies many common replication tasks. Replication using GTIDs guarantees consistency between source and replica as long as all transactions committed on the source have also been applied on the replica.
Overall
MySQL 主从复制涉及到三个线程:
- 一个在主节点的线程:
binlog dump thread - 从节点中的两个线程:
- 一个 I/O receiver thead
- 一个 SQL thread
对于每一个主从连接,都需要这三个 thread 来完成。当主节点有多个从节点时,主节点会为每一个当前连接的从节点创建一个 binlog dump thread,而每个从节点都有自己的 I/O receiver thead 和 SQL thread。
从节点用两个 thread 将从主节点拉取更新和执行分成独立的任务,这样在执行同步数据任务的时候,不会降低读操作的性能。比如,如果从节点没有运行,此时 I/O thread 可以很快从主节点获取更新,尽管 SQL thread 还没有执行。如果在 SQL thread 执行之前从节点服务停止,至少 I/O thread 已经从主节点拉取到了最新的变更并且保存在本地 relay log 中,当服务再次起来之后就可以完成数据的同步。
因为整个复制过程实际上就是 Slave 从 Master 端获取该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。如下图所示:
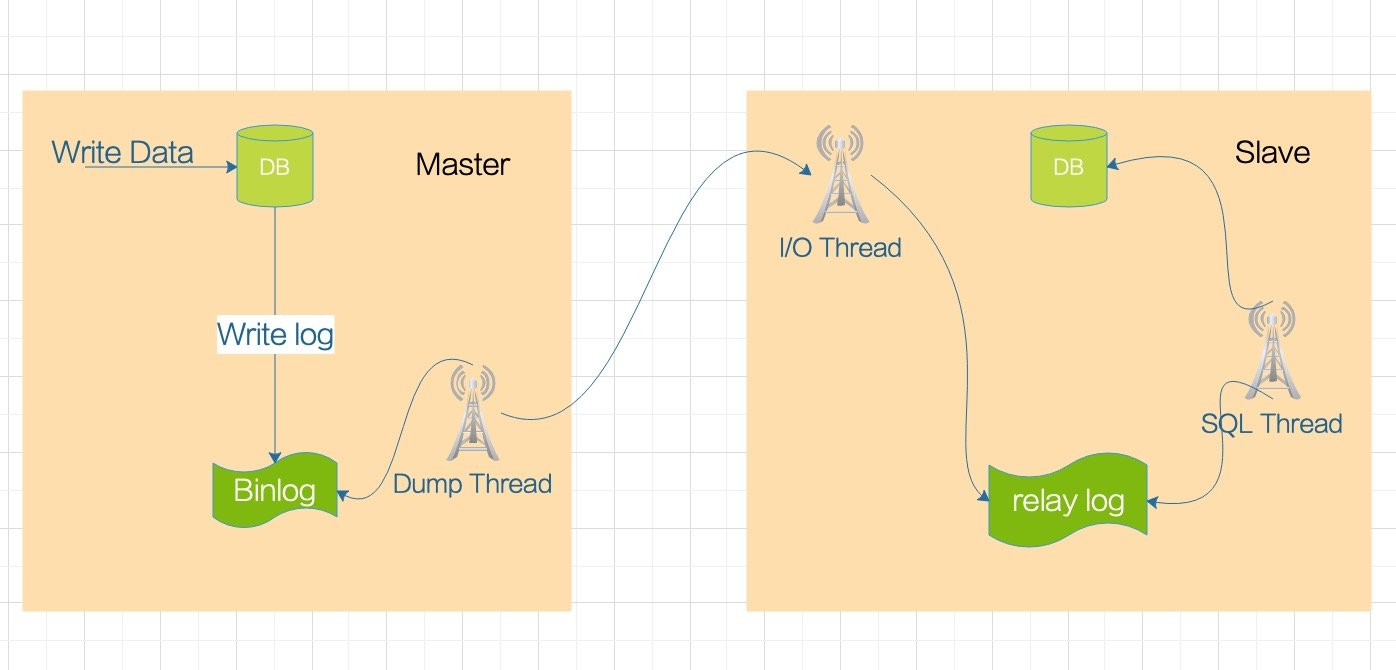
- 在从节点上执行
sart slave命令开启主从复制开关,开始进行主从复制。从节点上的 I/O receiver thead 连接主节点,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容。 - 主节点会创建一个 binlog dump thread,用来给从节点的 I/O receiver thead 传 binlog 数据
- binlog dump thread 根据请求信息读取指定日志指定位置之后的日志信息,返回给从节点。返回信息中除了日志所包含的信息之外,还包括本次返回的信息的 binlog file 以及 binlog position(binlog 下一个数据读取位置)。
- 从节点的 I/O thread接收到主节点发送过来的日志内容、日志文件及位置点后,将接收到的日志内容更新到本机的 relay log 文件(Mysql-relay-bin.xxx)的最末端,并将读取到的 binlog文件名和位置保存到
master-info - Slave 的 SQL 线程检测到relay log 中新增加了内容后,会将 relay log 的内容解析成在能够执行 SQL 语句,然后在本数据库中按照解析出来的顺序执行,并在
relay log.info中记录当前应用relay log的文件名和位置点。
主节点 binlog dump thread
当每一个从节点连接主节点时,主节点会为其创建一个 binlog dump thread,用于发送和读取 binlog 的内容。
在读取 binlog 中的操作时, The binary log dump thread acquires a lock on the source’s binary log for reading each event that is to be sent to the replica. As soon as the event has been read, the lock is released, even before the event is sent to the replica.
主节点会为自己的每一个从节点创建一个 binlog dump thread。
从节点 I/O receiver thread
当从节点上执行start slave命令之后,the replica creates an I/O (receiver) thread, which connects to the source and asks it to send the updates recorded in its binary logs.
The replication receiver thread reads the updates that the source’s Binlog Dump thread sends (see previous item) and copies them to local files that comprise the replica’s relay log.
relay log
这里又引申出一个新的日志概念。MySQL 进行主主复制或主从复制的时候会在要复制的服务器下面产生相应的 relay log。
relay log 是怎么产生的呢?
从节点 I/O receiver thead 将主节点的 binlog 日志读取过来,解析到各类 Events 之后记录到从节点本地文件,这个文件就被称为 relay log。然后 SQL 线程会读取 relay log 日志的内容并应用到从节点,从而使从节点和主节点的数据保持一致。relay log充当缓冲区,这样 master 就不必等待 slave 执行完成才发送下一个事件。
relay log 相关参数查询:
mysql> show variables like '%relay%';
+---------------------------+------------------------------------------------------------+
| Variable_name | Value |
+---------------------------+------------------------------------------------------------+
| max_relay_log_size | 0 |
| relay_log | yangyuedeMacBook-Pro-relay-bin |
| relay_log_basename | /usr/local/mysql/data/yangyuedeMacBook-Pro-relay-bin |
| relay_log_index | /usr/local/mysql/data/yangyuedeMacBook-Pro-relay-bin.index |
| relay_log_info_file | relay-log.info |
| relay_log_info_repository | TABLE |
| relay_log_purge | ON |
| relay_log_recovery | OFF |
| relay_log_space_limit | 0 |
| sync_relay_log | 10000 |
| sync_relay_log_info | 10000 |
+---------------------------+------------------------------------------------------------+
11 rows in set (0.03 sec)
max_relay_log_size
标记 relay log 允许的最大值,如果该值为 0,则默认值为 max_binlog_size(1G);如果不为 0,则max_relay_log_size 则为最大的 relay_log 文件大小。
relay_log_purge
是否自动清空不再需要relay log时。默认值为1(启用)。
relay_log_recovery
当 slave 从节点宕机后,假如 relay log 损坏了,导致一部分relay log没有处理,则自动放弃所有未执行的 relay log,并且重新从 master 上获取日志,这样就保证了 relay log 的完整性。默认情况下该功能是关闭的,将 relay_log_recovery 的值设置为 1 时,可在 slave 从节点上开启该功能,建议开启。
relay_log_space_limit
防止relay log写满磁盘,这里设置relay log最大限额。但此设置存在主节点崩溃,从节点relay log不全的情况,不到万不得已,不推荐使用。
sync_relay_log
这个参数和 binlog 中的 sync_binlog作用相同。当设置为 1 时,slave 的 I/O receiver thead 每次接收到 master 发送过来的 binlog 日志都要写入系统缓冲区,然后刷入 relay log relay log里,这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但会造成磁盘的大量 I/O。
当设置为 0 时,并不是马上就刷入relay log里,而是由操作系统决定何时来写入,虽然安全性降低了,但减少了大量的磁盘 I/O 操作。这个值默认是 0,可动态修改,建议采用默认值。
sync_relay_log_info
当设置为 1 时,slave 的 I/O receiver thead每次接收到 master 发送过来的 binlog 日志都要写入系统缓冲区,然后刷入 relay-log.info 里,这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但会造成磁盘的大量 I/O。当设置为 0 时,并不是马上就刷入 relay-log.info 里,而是由操作系统决定何时来写入,虽然安全性降低了,但减少了大量的磁盘 I/O 操作。这个值默认是0,可动态修改,建议采用默认值。
从节点 SQL thread
SQL thread 负责读取 relay log 中的内容,解析成具体的操作并执行,最终保证主从数据的一致性。
Implementation of Replication Logs
Position/statement-based Replication - Binary Log file
MySQL refers to its traditional replication method as binary log file position-based replication, where the MySQL instance operating as the source (where the database changes take place) writes updates and changes as “events” to the binary log. The information in the binary log is stored in different logging formats according to the database changes being recorded. Replicas are configured to read the binary log from the source and to execute the events in the binary log on the replica’s local database.
Each replica receives a copy of the entire contents of the binary log. It is the responsibility of the replica to decide which statements in the binary log should be executed. Unless you specify otherwise, all events in the source’s binary log are executed on the replica. If required, you can configure the replica to process only events that apply to particular databases or tables.
Each replica keeps a record of the binary log coordinates: the file name and position within the file that it has read and processed from the source. This means that multiple replicas can be connected to the source and executing different parts of the same binary log. Because the replicas control this process, individual replicas can be connected and disconnected from the server without affecting the source’s operation. Also, because each replica records the current position within the binary log, it is possible for replicas to be disconnected, reconnect and then resume processing.
GTIDs (global transaction identifiers) - Transaction-based Replication
Binary log file position-based replication is viable for many use cases, but this method can become clunky in more complex setups. This led to the development of MySQL’s newer native replication method, which is sometimes referred to as transaction-based replication. This method involves creating a global transaction identifier (GTID) for each transaction — or, an isolated piece of work performed by a database — that the source MySQL instance executes.
The mechanics of transaction-based replication are similar to binary log file-based replication: whenever a database transaction occurs on the source, MySQL assigns and records a GTID for the transaction in the binary log file along with the transaction itself. The GTID and the transaction are then transmitted to the source’s replicas for them to process.
Analysis
MySQL’s transaction-based replication has a number of benefits over its traditional replication method. For example, because both a source and its replicas preserve GTIDs, if either the source or a replica encounter a transaction with a GTID that they have processed before they will skip that transaction. This helps to ensure consistency between the source and its replicas. Additionally, with transaction-based replication replicas don’t need to know the binary log coordinates of the next database event to process. This means that starting new replicas or changing the order of replicas in a replication chain is far less complicated.
复制中的数据一致性问题
我们上面讨论了复制的核心步骤,看似很简单的一个流程,主节点的binlog dump去读取binlog,然后从节点的I/O receiver thead去读取、写入Relay Log,进而从节点的SQL线程再读取Relay Log进行重放。
那如果I/O receiver thead复制到一半自己突然挂掉了呢?又或者复制到一半主节点宕机了呢?如果和保证数据一致性的呢?
我们上面提到过,有一个relay-log.info的文件,用于记录当前从节点正在复制的binlog和写入的Relay Log的Pos,只要这个文件还在,那么当从节点意外重启之后,就会重新读取文件,从上次复制的地方开始继续复制。这就跟Redis中的主从复制类似,双方要维护一个offset,通过对比offset,来进行psync增量数据同步。
但是在MySQL 5.5以及之前,都只能将复制的进度记录在relog-log.info文件中。换句话说,参数relay_log_info_repository只支持FILE,可以再回到上面的1.5 Relay Log核心参数看一下。所以只有在sync_relay_log_info次事务之后才会把relay-log.info文件刷入磁盘。
如果在刷入磁盘之前从节点挂了,那么重启之后就会发现SQL线程实际执行到位置和数据库记录的不一致,数据一致性的问题就这么产生了。
所以在MySQL 5.6时,参数relay_log_info_repository支持了TABLE,这样一来我们就可以将复制的进度放在系统的mysql.slave_relay_log_info表里去,并且把更新进度、SQL线程执行用户事务绑定成一个事务执行。即使slave宕机了,我们也可以通过MySQL内建的崩溃恢复机制来使实际执行的位置和数据库保存的进度恢复到一致。
其次还有上面提到的半同步复制,主节点会先提交事务,然后等待从节点的返回,再将结果返回给客户端,但是如果在主节点等待的时候,从节点挂了呢?
此时主节点上由于事务已经提交了,但是从节点上却没有这个数据。所以在MySQL 5.7时引入了无损半同步复制,增加了参数rpl_semi_sync_master_wait_point的值,在MySQL 5.7中值默认为after_sync,在MySQL 5.6中默认值为after_commit。
- after_sync 主节点先不提交事务,等待某一个从节点返回了结果之后,再提交事务。这样一来,如果从节点在没有任何返回的情况下宕机了,master这边也无法提交事务。主从仍然是一致的
- after_commit 与之前讨论的一样,主节点先提交事务,等待从节点返回结果再通知客户端
Reference
- https://dev.mysql.com/doc/refman/8.0/en/replication.html
- https://severalnines.com/resources/database-management-tutorials/mysql-replication-high-availability-tutorial
- https://hevodata.com/learn/mysql-master-slave-replication/
- https://www.digitalocean.com/community/tutorials/how-to-set-up-replication-in-mysql
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems