C10K 问题
C10K是服务器应用领域很古老很出名的一个问题,大意是说单台服务器要同时支持并发 10K 量级的连接。
即「在同时连接到服务器的客户端数量超过 10000 个的环境中,即便硬件性能足够, 依然无法正常提供服务」,简而言之,就是如何让单机具备处理1万个并发连接,且这些连接可能是保持存活状态。这个概念最早由 Dan Kegel 在1999年提出并发布于其个人站点( http://www.kegel.com/c10k.html )。
C10K问题的解决方案探讨
要解决这一问题,从纯网络编程技术角度看,主要思路有两个:
- 思路一:对于每个连接处理分配一个独立的进程/线程;
- 思路二:用同一进程/线程来同时处理若干连接。
思路一:每个进程/线程处理一个连接
这一思路最为直接,即每一个新连接到来,都为其创建一个对应的线程来处理。
由于申请和销毁进程/线程都会消耗相当可观的系统资源(CPU和内存),而且大量地进行线程上下文切换会导致CPU效率不高(CPU的计算资源未得到充分利用),因此这种方案不具备良好的可扩展性。当连接数较少时,可以获得很快的响应速度。而当连接量大大增加时,响应速度会呈指数性下降。
传统的Apache,Tomcat均采用这个思路进行实现。它本质上基于传统的同步阻塞I/O模型。
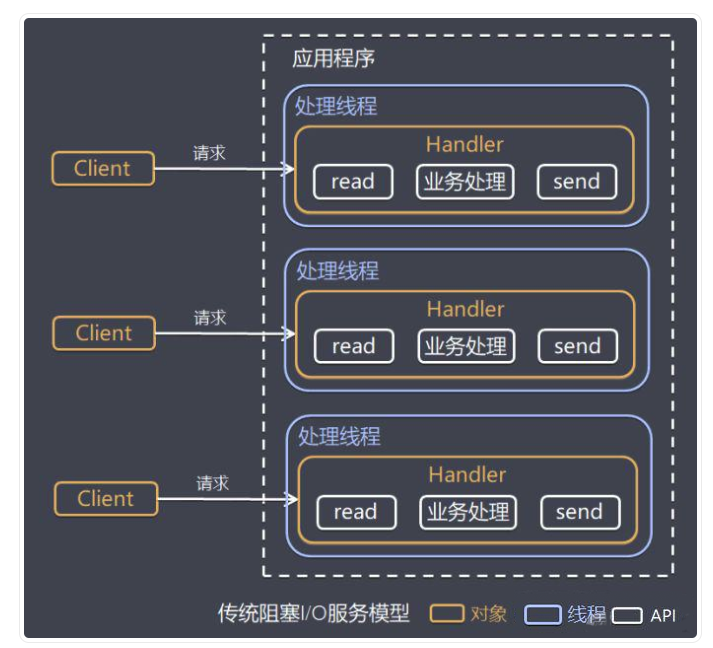
因此,这一思路在服务器资源还没有富裕到足够程度的时候,是不可行的。即便资源足够富裕,效率也不够高。总之,此思路技术实现会使得资源占用过多,可扩展性差。
思路二:每个进程/线程同时处理多个连接
同步非阻塞I/O模型
在思路一中,本质上是由于线程不断被阻塞导致的效率低下。因此,很自然的联想到,是否存在一种非阻塞的调用方式呢。
Linux的read()系统调用就为我们提供了非阻塞的调用,如下图所示:
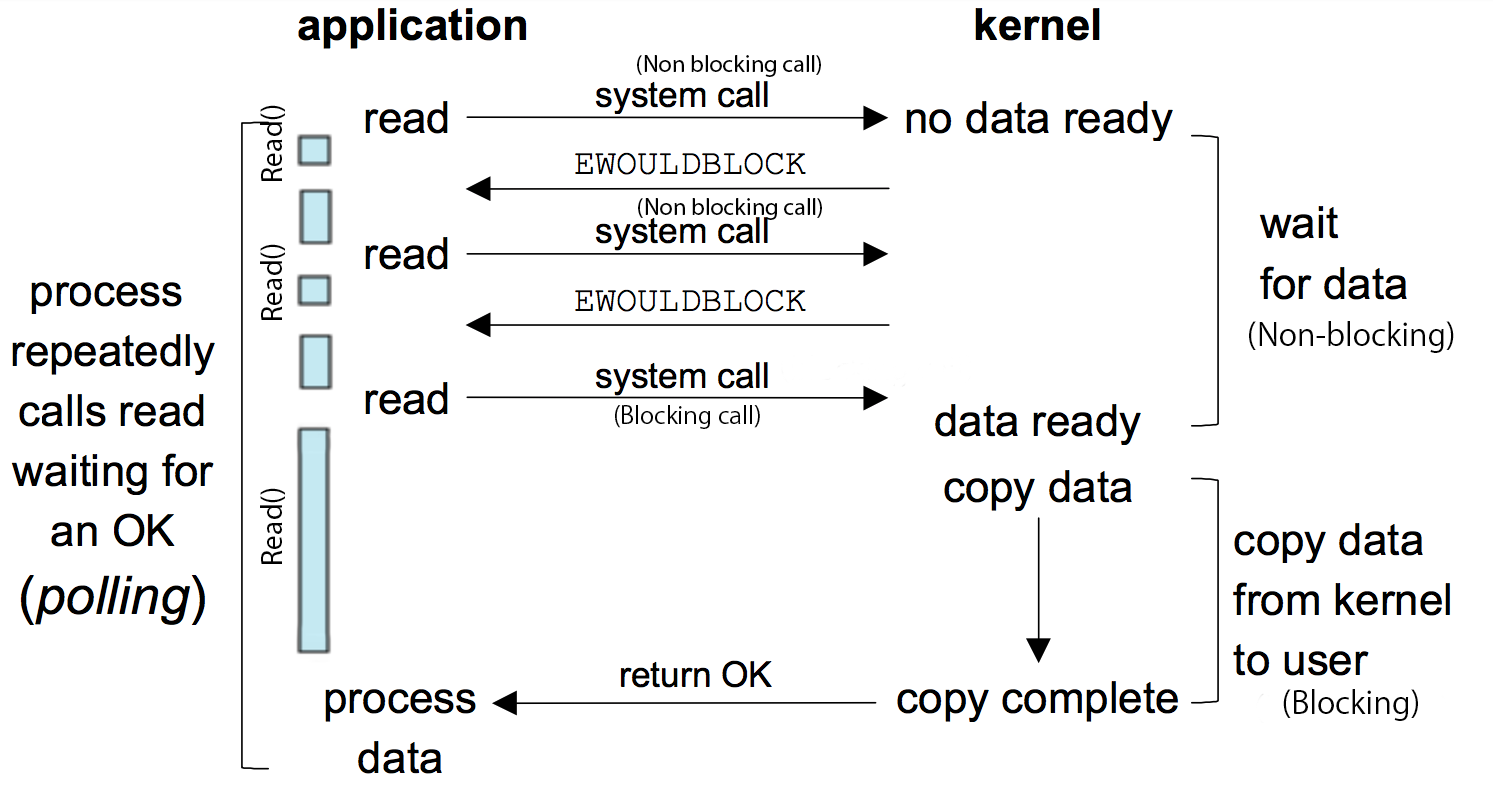
可以看到,用户线程需要不停地发送系统调用以获取这个I/O操作的最新状态,这个过程称为轮询(poll)。
虽然用户线程不再被阻塞了,但用户线程需要不断地进行轮询,轮询过程会消耗额外的CPU资源。因此CPU的有效利用率同样不高。
I/O多路复用(I/O Multiplexing)
我们希望,用户线程不需要进行不停的轮询,以避免消耗额外的CPU资源。同时,用户线程处于休眠状态(sleep),而当一个或多个文件描述符对应的I/O操作数据准备完成时,用户线程被唤醒,以去处理这些I/O操作。
I/O多路复用(I/O Multiplexing)技术正是为了满足上面的需求而诞生的。I/O多路复用基于同步非阻塞模型(Synchronous non-blocking model)+ 轮询技术(poll)。
I/O多路复用使得用户线程可以并发的阻塞在多个文件描述符上,当其中任何一个文件描述符对应的I/O操作准备就绪时,控制流被返回给用户线程,用户线程从休眠状态切换成活跃状态。
I/O多路复用从技术实现上又分很多种,在Linux中,包括select、poll和epoll,我们逐一来看看IO多路复用各种实现方式的优劣。
I/O多路复用 - select
I/O多路复用技术的出现,使得用户线程可以监控多个socket(本质上是多个文件描述符),当其中任何一个文件描述符的状态发生指定变化(例如,由不可用变为可用)或超时时,则select()调用返回。
select的效率已经比上面几种模型高太多了,然而,它也有一些不足。
由于存储文件描述符的集合fd_set是数组类型,且其可存储的元素的数量(FD_SETSIZE)有一个上限值。
而且,select()对应处理文件描述符的索引值较大的情况时,效率不高。在select()中,如果仅仅检测一个值为900的文件描述符时,内核需要从0开始扫描各个文件描述符,直到第900个(因为在调用select()时,需要传入值最大的文件描述符的数字)。
另外,select()调用的初始化较为繁琐。在select()中,文件描述符集合会在select()调用返回时重新构造,因此在下一次调用select()时,必须重新构造文件描述符集合。
更主要的是,select()在每一次检查监听的文件描述符状态变化时,都需要遍历一次用户传入的文件描述符集合,因而如果当文件描述符的数量很多时,一次集合遍历将会非常耗时。
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
- 思路:有连接请求抵达了再检查处理。
- 问题:文件描述符数量有上限+重复初始化+逐个检查文件描述符的变化状态效率不高。
I/O多路复用 - poll
poll 主要解决 select 的前两个问题:动态地确定文件描述符数量以消除文件描述符数量上限问题,同时使用不同字段分别标注关注事件和发生事件,来避免重复初始化。
然而poll仍然会每隔一定的时间,逐个扫描用户传入的所有文件描述符的变化状态,直到当其中任何一个文件描述符的状态发生指定变化或超时,因而效率也相对不高。
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
- 思路:设计新的数据结构提供使用效率。
- 问题:逐个检查文件描述符的变化状态效率不高。
I/O多路复用 - epoll
epoll从内核层面解决了select和poll中,需要每隔一定的时间逐个检查关注的文件描述符的变化状态,因而效率不高的问题。
epoll 采用了这种设计,适用于大规模的应用场景。
实验表明,当文件句柄数目超过 10 之后,epoll 性能将优于 select 和 poll;当文件句柄数目达到 10K 的时候,epoll 已经超过 select 和 poll 两个数量级。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
- 思路:只返回状态变化的文件句柄。
- 问题:依赖特定平台(Linux)。
因为Linux是互联网企业中使用率最高的操作系统,Epoll就成为C10K killer、高并发、高性能、异步非阻塞这些技术的代名词了。FreeBSD推出了kqueue,Linux推出了epoll,Windows推出了IOCP,Solaris推出了/dev/poll。这些操作系统提供的功能就是为了解决C10K问题。epoll技术的编程模型就是同步非阻塞回调,也可以叫做Reactor,事件驱动,事件轮循(EventLoop)。
Nginx,libevent,Node.js这些就是epoll时代的产物。
libevent
由于epoll, kqueue, IOCP每个接口都有自己的特点,程序移植非常困难,于是需要对这些接口进行封装,以让它们易于使用和移植,其中libevent库就是其中之一。
libevent提供跨平台,封装底层平台的调用,提供统一的 API,但底层在不同平台上自动选择合适的调用。按照libevent的官方网站,libevent库提供了以下功能:当一个文件描述符的特定事件(如可读,可写或出错)发生了,或一个定时事件发生了,libevent就会自动执行用户指定的回调函数,来处理事件。目前,libevent已支持以下接口/dev/poll, kqueue, event ports, select, poll 和 epoll。Libevent的内部事件机制完全是基于所使用的接口的。因此libevent非常容易移植,也使它的扩展性非常容易。目前,libevent已在以下操作系统中编译通过:Linux,BSD,Mac OS X,Solaris和Windows。使用libevent库进行开发非常简单,也很容易在各种unix平台上移植。解决C10K
Nginx正是解决C10K问题的一个产物。
C10K 到 C10M
随着技术的演进,epoll 已经可以较好的处理 C10K 问题,但是如果要进一步的扩展,例如支持 10M 规模的并发连接,原有的技术就无能为力了。
那么,新的瓶颈在哪里呢?
从前面的演化过程中,我们可以看到,根本的思路是要高效的去阻塞,让 CPU 可以干核心的任务。
当连接很多时,首先需要大量的进程/线程来做事。同时系统中的应用进程/线程们可能大量的都处于 ready 状态,需要系统去不断的进行快速切换,而我们知道系统上下文的切换是有代价的。虽然现在 Linux 系统的调度算法已经设计的很高效了,但对于 10M 这样大规模的场景仍然力有不足。
所以我们面临的瓶颈有两个,一个是进程/线程作为处理单元还是太厚重了;另一个是系统调度的代价太高了。
很自然地,我们会想到,如果有一种更轻量级的进程/线程作为处理单元,而且它们的调度可以做到很快(最好不需要锁),那就完美了。
这样的技术现在在某些语言中已经有了一些实现,它们就是 coroutine**(协程)**,或协作式例程。具体的,Python、Lua 语言中的 coroutine(协程)模型,Go 语言中的 goroutine(Go 程)模型,都是类似的一个概念。实际上,多种语言(甚至 C 语言)都可以实现类似的模型。
它们在实现上都是试图用一组少量的线程来实现多个任务,一旦某个任务阻塞,则可能用同一线程继续运行其他任务,避免大量上下文的切换。每个协程所独占的系统资源往往只有栈部分。而且,各个协程之间的切换,往往是用户通过代码来显式指定的(跟各种 callback 类似),不需要内核参与,可以很方便的实现异步。
Reference
- The C10K problem - http://www.kegel.com/c10k.html
- Wikipedia C10k problem- https://en.wikipedia.org/wiki/C10k_problem
- 《Unix Network Programming, Volume 1: The Sockets Networking API: Sockets Networking API》
- 《Linux System Programming Talking Directly to the Kernel and C Library》
- 高性能网络编程(二):上一个10年,著名的C10K并发连接问题 - http://www.52im.net/thread-566-1-1.html
- C10K 问题引发的技术变革 - https://blog.csdn.net/yeasy/article/details/43152115
- 程序员怎么会不知道 C10K 问题呢 - https://medium.com/@chijianqiang/%E7%A8%8B%E5%BA%8F%E5%91%98%E6%80%8E%E4%B9%88%E4%BC%9A%E4%B8%8D%E7%9F%A5%E9%81%93-c10k-%E9%97%AE%E9%A2%98%E5%91%A2-d024cb7880f3
- 高性能网络编程(六):一文读懂高性能网络编程中的线程模型 - http://www.52im.net/thread-1939-1-1.html
- select / poll / epoll: practical difference for system architects - https://www.ulduzsoft.com/2014/01/select-poll-epoll-practical-difference-for-system-architects/