背景
一直以来,硬件的发展极其迅速,也有一个很著名的"摩尔定律",可能会奇怪明明讨论的是并发编程为什么会扯到了硬件的发展,这其中的关系应该是多核CPU的发展为并发编程提供的硬件基础。摩尔定律并不是一种自然法则或者是物理定律,它只是基于认为观测数据后,对未来的一种预测。按照所预测的速度,我们的计算能力会按照指数级别的速度增长,不久以后会拥有超强的计算能力,正是在畅想未来的时候,2004年,Intel宣布4GHz芯片的计划推迟到2005年,然后在2004年秋季,Intel宣布彻底取消4GHz的计划,也就是说摩尔定律的有效性超过了半个世纪戛然而止。但是,聪明的硬件工程师并没有停止研发的脚步,他们为了进一步提升计算速度,而不是再追求单独的计算单元,而是将多个计算单元整合到了一起,也就是形成了多核CPU。短短十几年的时间,家用型CPU,比如Intel i7就可以达到4核心甚至8核心。而专业服务器则通常可以达到几个独立的CPU,每一个CPU甚至拥有多达8个以上的内核。因此,摩尔定律似乎在CPU核心扩展上继续得到体验。因此,多核的CPU的背景下,催生了并发编程的趋势,通过并发编程的形式可以将多核CPU的计算能力发挥到极致,性能得到提升。
顶级计算机科学家Donald Ervin Knuth如此评价这种情况:在我看来,这种现象(并发)或多或少是由于硬件设计者无计可施了导致的,他们将摩尔定律的责任推给了软件开发者。
另外,在特殊的业务场景下先天的就适合于并发编程。比如在图像处理领域,一张1024X768像素的图片,包含达到78万6千多个像素。即时将所有的像素遍历一边都需要很长的时间,面对如此复杂的计算量就需要充分利用多核的计算的能力。又比如当我们在网上购物时,为了提升响应速度,需要拆分,减库存,生成订单等等这些操作,就可以进行拆分利用多线程的技术完成。面对复杂业务模型,并行程序会比串行程序更适应业务需求,而并发编程更能吻合这种业务拆分 。正是因为这些优点,使得多线程技术能够得到重视,也是一名CS学习者应该掌握的:
- 充分利用多核CPU的计算能力;
- 方便进行业务拆分,提升应用性能。
通过多线程实现多程序的同时(simultaneously)执行具有以下好处:
- 资源利用率(Resource utilization):程序有时候不得不等待外部的操作(比如I/O),因而在等待时不能进行工作。如果在等待时,让出CPU以让去其他程序执行能够提供整体的资源利用率。
- 公平(Fairnesss):让多个程序合理地间断的占用 CPU 时间片,比让一个程序一直执行直到其完成后再让另一个程序执行更公平。
- 方便(Convenience):将一个大任务中多个小任务分配给多个程序去执行,且程序之间进行协作,比使用一个程序去完成这个大任务更合理。
线程(thread)是最简单的充分开启多处理器(multiprocesssor)系统计算能力的方式。
并发编程有哪些缺点
多线程技术有这么多的好处,难道就没有一点缺点么,就在任何场景下就一定适用么?很显然不是。
频繁的上下文切换
时间片是CPU分配给各个线程的时间,因为时间非常短,所以CPU不断通过切换线程,让我们觉得多个线程是同时执行的,时间片一般是几十毫秒。而每次切换时,需要保存当前的状态起来,以便能够进行恢复先前状态,而这个切换时非常损耗性能,过于频繁反而无法发挥出多线程编程的优势。通常减少上下文切换可以采用无锁并发编程,CAS算法,使用最少的线程和使用协程。
- 无锁并发(lock free)编程:可以参照 ConcurrentHashMap 锁分段的思想,不同的线程处理不同段的数据,这样在多线程竞争的条件下,可以减少上下文切换的时间。
- CAS 算法,利用 Atomic 下使用 CAS 算法来更新数据,使用了乐观锁(pessimistic locking),可以有效的减少一部分不必要的锁竞争带来的上下文切换。
- 使用最少线程:避免创建不需要的线程,比如任务很少,但是创建了很多的线程,这样会造成大量的线程都处于等待状态(从本质来说,是就绪状态(Ready),因而不能获得 CPU 时间片)
- 协程(coroutine):在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换
由于上下文切换也是个相对比较耗时的操作,所以在"java并发编程的艺术"一书中有过一个实验,并发累加未必会比串行累加速度要快。 通过Lmbench3 可以测量上下文切换的时长 ,而 vmstat 可以测量上下文切换次数。
并发编程中的三个概念
在并发编程中,我们通常会遇到以下三个问题:原子性问题,可见性问题,有序性问题。我们先看具体看一下这三个概念:
1 原子性(Atomicity)
原子性(Atomicity),即一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
但是很多操作不能通过一条指令就完成。
例子1 - long类型
例如,对 long 类型的运算,很多系统就需要分成多条指令分别对高位和低位进行操作才能完成。
@NotThreadSafe
public class UnsafeCountingFactorizer implements Servlet {
private long count = 0;
public long getCount() { return count; }
public void service(ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
BigInteger[] factors = factor(i);
++count;
encodeIntoResponse(resp, factors);
}
}
在上面的例子中,由于 UnsafeCountingFactorizer 不算是线程安全的,而且这是一个典型的读-更新-写操作(read-modify-write)操作,因此当运行在多线程的环境下,可能会出现丢失更新(lost update)的情况。
从本质来说,发生丢失更新是因为多个线程同时进入了临界区(critical regions),因而发生了竞争条件(race condition)。
解决
一种解决方案,是为整个复合操作(compound action)加锁,以保证原子性。比如通过 Java 内置的锁实现同步,比如 synchronized,他们被称为固有锁/内置锁(intristic locks)或管程锁(monitor locks),Java 中的固有锁(intristic locks)均为互斥锁(mutexes)。
另一种解决,是通过利用 java.util.concurrent.atomic 包中提供的原子变量类。通过将 long 类型替换为 AtomicLong,最终保证计数的原子性。
@ThreadSafe
public class CountingFactorizer implements Servlet {
private final AtomicLong count = new AtomicLong(0);
public long getCount() { return count.get(); }
public void service(ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
BigInteger[] factors = factor(i);
count.incrementAndGet();
encodeIntoResponse(resp, factors);
}
}s
例子2 - i++
还比如,我们经常使用的整数 i++ 的操作,其实需要分成三个步骤:
- 读取整数 i 的值;
- 对 i 进行加一操作;
- 将结果写回内存。
这个过程在多线程下就可能出现如下现象:
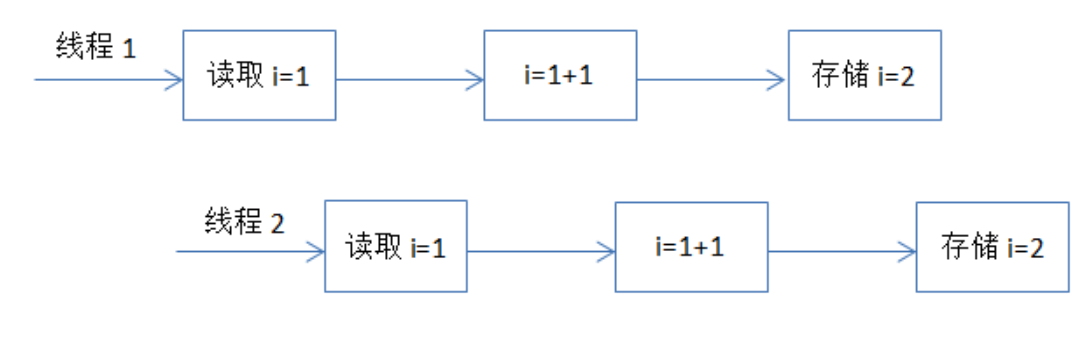
对于这种组合操作,要保证原子性,最常见的方式是加锁,如 Java 中的synchronized 或 Lock 都可以实现,
2 可见性(Visibility)
可见性(Visibility)是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
举一个例子来说明:
//线程1执行的代码
int i = 0;
i = 10;
//线程2执行的代码
j = i;
假若线程 1 在被 CPU1 执行,而线程 2 在被 CPU2 执行。由上面的分析可知,当线程 1 执行 i =10 这句时,会先把 i 的初始值加载到 CPU1 的高速缓存中,然后赋值为 10,那么在 CPU1 的高速缓存当中 i 的值变为 10 了,却没有立即写入到主存当中。
此时,线程 2 执行 j = i,它会先去主存读取 i 的值,并加载到 CPU2 的高速缓存当中。注意,此时内存中 i 的值还是 0,那么就会使得 j 的值也为0,而不是 10.
这就是可见性问题,线程 1 对变量 i 修改了之后,线程 2 没有立即看到线程 1 修改的值。
没有同步机制的读取数据类似于在数据库中使用 READ_UNCOMITTED 隔离级别(isolation level),以获得更优的数据库性能。然而,前者的执行结果更不可预知。
非原子的 64 位操作(Nonatomic 64-bit operations)
当一个线程读取一个变量,同时不使用同步机制时,尽管可能获得一个过期的值,但是仍是其中的某一个线程提供的,而不是一个随机值(random)。
其中有两个例外,类型为 double 或者 long 且没有被声明为 volatile 的变量。这是因为,JVM 会将一个 64 位的读或写操作当做是两个独立的 32 为操作。
因此,只有当可变且类型为 long 或 double 的变量被声明为 volatile时,原子性才能得到保障。
锁与可见性
如下图所示,当线程A 执行 synchronized 块,之后线程B 进入 sychronized 块,且他们都基于同一个锁对象,在线程B 获得锁时,线程A (在未获得锁之前和持有锁的两个过程中)对所有变量的修改,对于线程B 都是可见的。
换句话说,
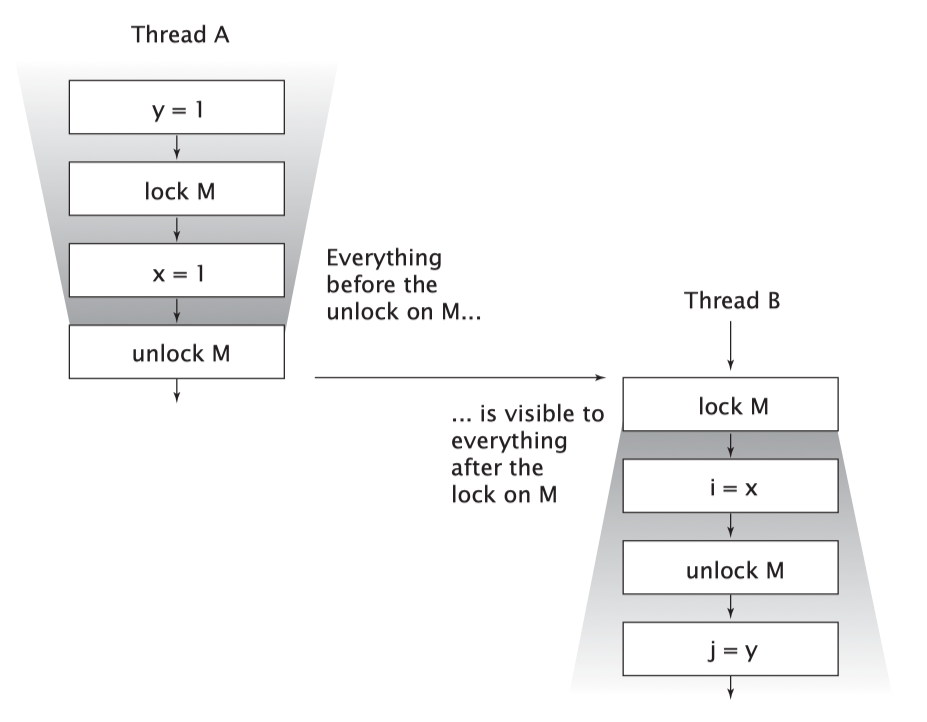
volatile 变量
当一个字段(field)被声明为 volatile 后,对于这个字段的操作均不会被 Java 编译器重排序。
由于 volatile 变量不会被缓存在当前执行 CPU 的寄存器(registers)或者缓存(caches)中,对于 volatile 变量的读取,将会返回最后被任何一个线程重改写的那个值。
值得注意的是,从可见性效果(visibility effects)的角度而言,声明一个 volatile 变量不仅仅只是作用于这个变量本身。事实上,线程A 更新一个 volatile 变量,此后线程B 读取这个变量的值。当线程B 读取这个变量的值后,对于线程A 在更新 volatile 变量之前,对其他的所有变量的修改,线程B 都是可见的。
另外,由于 volatile 变量中并不存在任何锁,因而访问这个变量并不会造成正在执行的线程进入阻塞态。因此,volatile 变量是一种比 synchronized 块更轻量级的同步机制。一句话概括,锁可以保证可见性和原子性,而 volatile 变量只能保证可见性。
3 有序性(Ordering)
有序性(Ordering),即程序执行的顺序按照代码的先后顺序执行。
举个简单的例子,看下面这段代码:
int i = 0;
boolean flag = false;
//语句1
i = 1;
//语句2
flag = true;
上面代码定义了一个 int 型变量,定义了一个 boolean 类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
事实上,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?再看下面一个例子:
//语句1
int a = 10;
//语句2
int r = 2;
//语句3
a = a + 3;
//语句4
r = a * a;
这段代码有4个语句,那么可能的一个执行顺序是:

那么可不可能是这个执行顺序呢: 语句2 语句1 语句4 语句3
不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
//线程1:
//语句1
context = loadContext();
//语句2
inited = true;
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时 context 并没有被初始化,就会导致程序出错。
总结:
- 指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
- 要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
线程安全
当一个可变(mutable)对象会被多个线程访问时,就要考虑这个线程是不是需要被设计成线程安全的。
一个类会被称为**线程安全(thread-safe)**的,当它被从多个线程访问,而且无论这些线程如何被调度(scheduling)和交叉(interleaving)执行,而且在调用代码(calling code)中不需要额外的同步(synchronization)或者其他协调(coordiantion)机制,它的行为仍然正确(若预期执行)。
换句话说,线程安全的类封装(encapsulate)了已经需要的同步机制,因此客户端或者说调用者不再需要关注或者提供这些同步机制。
值得一提的是,无状态(stateless)的对象总是线程安全的。
以一个无状态的 servlet 为例:
@ThreadSafe
public class StatelessFactorizer implements Servlet { public void service(ServletRequest req, ServletResponse resp)
{
BigInteger i = extractFromRequest(req);
BigInteger[] factors = factor(i);
encodeIntoResponse(resp, factors);
}
}
在这个例子中,临时的状态被存储在这个线程对应的栈(stask)中的局部变量(local variables)中,因而只能被这个线程访问。
当多个线程可以同时访问一个可变状态(mutable state)变量,且没有同步机制时,这个程序就会有 bug,我们通过以下任何一种方式解决:
- 不要在线程之间共享状态变量(state variable);
- 使得状态变量的状态不可改变(immutable);
- 增加同步机制。
死锁(Deadlock)
多线程编程中最难以把握的就是临界区线程安全问题,稍微不注意就会出现死锁的情况,一旦产生死锁就会造成系统功能不可用。
public class Main {
private static String resource_a = "A";
private static String resource_b = "B";
public static void main(String[] args) {
deadLock();
}
public static void deadLock() {
Thread threadA = new Thread(new Runnable() {
@Override
public void run() {
synchronized (resource_a) {
System.out.println("get resource a");
try {
Thread.sleep(3000);
synchronized (resource_b) {
System.out.println("get resource b");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
Thread threadB = new Thread(new Runnable() {
@Override
public void run() {
synchronized (resource_b) {
System.out.println("get resource b");
synchronized (resource_a) {
System.out.println("get resource a");
}
}
}
});
threadA.start();
threadB.start();
}
}
在上面的这个 demo 中,开启了两个线程 threadA ,threadB。其中 threadA 占用了 resource_a , 并等待被 threadB 释放的 resource _b 。threadB 占用了 resource _b ,且正在等待被 threadA 释放的 resource _a。因此 threadA 和 threadB出现了线程安全的问题,并形成死锁。
那么,通常可以用如下方式避免死锁的情况:
- 避免一个线程同时获得多个锁;
- 避免一个线程在锁内部占有多个资源,尽量保证每个锁只占用一个资源;
- 尝试使用定时锁,使用lock.tryLock(timeOut),当超时等待时当前线程不会阻塞;
- 对于数据库锁,加锁和解锁必须在一个数据库连接里,否则会出现解锁失败的情况。
Reference
- 《Java Concurrency in Practice》
- 并发编程的优缺点 - https://juejin.im/post/5ae6c3ef6fb9a07ab508ac85
- Java并发编程:volatile关键字解析 - https://www.cnblogs.com/dolphin0520/p/3920373.html