协程(Coroutine)
协程,又称微线程,纤程。英文名Coroutine,这其实是corporate routine的缩写,直接翻译为协同的例程。
协程的概念很早就提出来了,但直到最近几年才在某些语言(如Lua)中得到广泛应用。
子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。
所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。比如子程序A、B:
def A():
print '1'
print '2'
print '3'
def B():
print 'x'
print 'y'
print 'z'
假设由协程执行,在执行A的过程中,可以随时中断,去执行B,B也可能在执行过程中中断再去执行A,结果可能是:
1
2
x
y
3
z
但是在A中是没有调用B的,所以协程的调用比函数调用理解起来要难一些。
看起来A、B的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
总结来说,协程由于由程序主动控制切换,没有线程切换的开销,所以执行效率极高。对于I/O密集型任务非常适用,如果是CPU密集型,推荐多进程+协程的方式。
进程和协程
下面对比一下进程和协程的相同点和不同点:
相同点: 我们都可以把他们看做是一种执行流,执行流可以挂起,并且后面可以在你挂起的地方恢复执行,这实际上都可以看做是continuation,关于这个我们可以通过在linux上运行一个hello程序来理解:
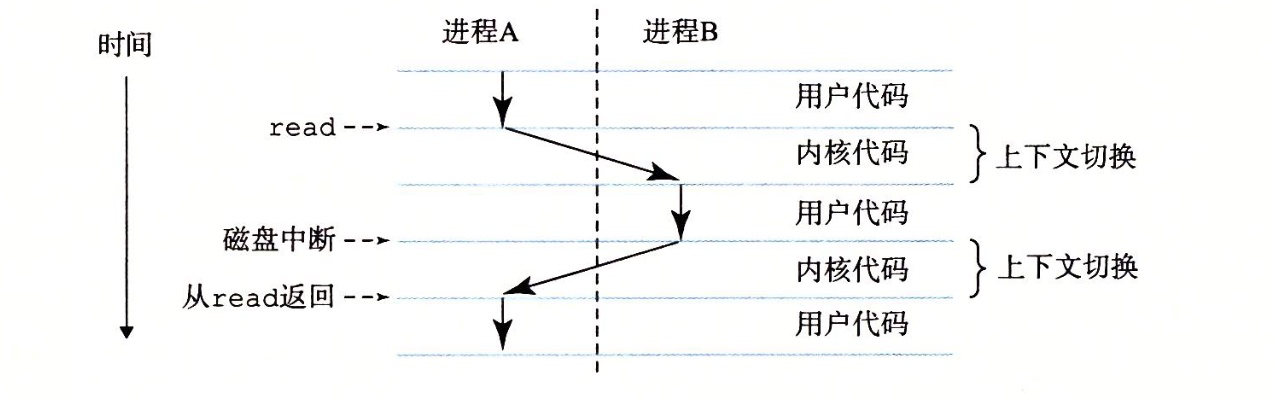
shell进程和hello进程:
- 开始,shell进程在运行,等待命令行的输入
- 执行hello程序,shell通过系统调用来执行我们的请求,这个时候系统调用会讲控制权传递给操作系统。操作系统保存shell进程的上下文,创建一个hello进程以及其上下文并将控制权给新的hello进程。
- hello进程终止后,操作系统恢复shell进程的上下文,并将控制权传回给shell进程
- shell进程继续等待下个命令的输入
当我们挂起一个执行流的时,我们要保存的东西:
- 栈, 其实在你切换前你的局部变量,以及要函数的调用都需要保存,否则都无法恢复
- 寄存器状态,这个其实用于当你的执行流恢复后要做什么
而寄存器和栈的结合就可以理解为上下文,上下文切换的理解:CPU看上去像是在并发的执行多个进程,这是通过处理器在进程之间切换来实现的,操作系统实现这种交错执行的机制称为上下文切换(context switch)。
操作系统保持跟踪进程运行所需的所有状态信息。这种状态,就是上下文。
在任何一个时刻,操作系统都只能执行一个进程代码,当操作系统决定把控制权从当前进程转移到某个新进程时,就会进行上下文切换,即保存当前进程的上下文,恢复新进程的上下文,然后将控制权传递到新进程,新进程就会从它上次停止的地方开始。
不同点:
- 执行流的调度者不同,进程是内核调度,而协程是在用户态调度,也就是说进程的上下文是在内核态保存恢复的,而协程是在用户态保存恢复的,很显然用户态的代价更低
- 进程会被强占,而协程不会,也就是说协程如果不主动让出CPU,那么其他的协程,就没有执行的机会。
- 对内存的占用不同,实际上协程可以只需要4K的栈就足够了,而进程占用的内存要大的多
- 从操作系统的角度讲,多协程的程序是单进程,单协程
线程和协程
既然我们上面也说了,协程也被称为微线程,下面对比一下协程和线程:
- 线程之间需要上下文切换成本相对协程来说是比较高的,尤其在开启线程较多时,但协程的切换成本非常低。
- 同样的线程的切换更多的是靠操作系统来控制,而协程的执行由我们自己控制
我们通过下面的图更容易理解:
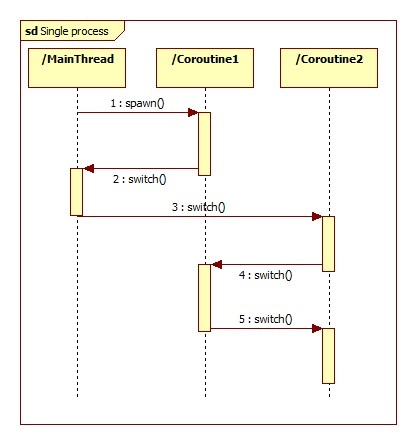
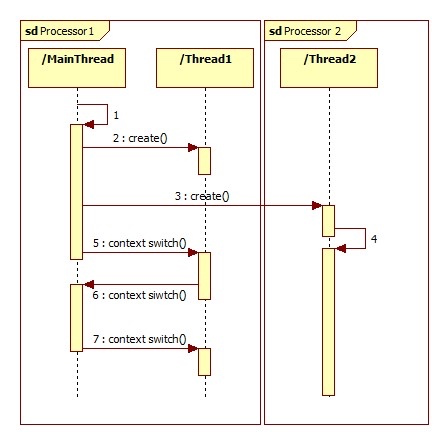
从上图可以看出,协程只是在单一的线程里不同的协程之间切换,其实和线程很像,线程是在一个进程下,不同的线程之间做切换,这也可能是协程称为微线程的原因吧
继续分析协程:
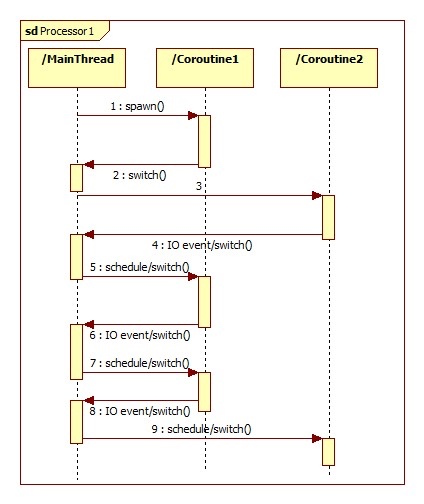
协程的支持
在Python3.4之前,官方没有对协程的支持,存在一些三方库的实现,比如gevent和Tornado。3.4之后就内置了asyncio标准库,官方真正实现了协程这一特性。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
Python对协程的支持是通过generator实现的。
在generator中,我们不但可以通过for循环来迭代,还可以不断调用next()函数获取由yield语句返回的下一个值。
但是Python的yield不但可以返回一个值,它还可以接收调用者发出的参数。
生产者和消费者模型
传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)
执行结果:
[PRODUCER] Producing 1...
[CONSUMER] Consuming 1...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 2...
[CONSUMER] Consuming 2...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 3...
[CONSUMER] Consuming 3...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 4...
[CONSUMER] Consuming 4...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 5...
[CONSUMER] Consuming 5...
[PRODUCER] Consumer return: 200 OK
注意到consumer函数是一个generator,把一个consumer传入produce后:
- 首先调用
c.send(None)启动生成器; - 然后,一旦生产了东西,通过
c.send(n)切换到consumer执行; consumer通过yield拿到消息,处理,又通过yield把结果传回;produce拿到consumer处理的结果,继续生产下一条消息;produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
最后套用Donald Knuth的一句话总结协程的特点:
“子程序就是协程的一种特例。”
Reference
- 协程 - https://www.liaoxuefeng.com/wiki/897692888725344/923057403198272
- 理解Python的协程(Coroutine) - https://juejin.im/post/5c13245ee51d455fa5451f33
- Python并发编程协程(Coroutine)之Gevent - https://www.cnblogs.com/zhaof/p/7536569.html