Redis集群
当面对一个小型的Demo项目时,使用一台Redis服务器己经非常足够了,然而现实中的项目通常需要若干台Redis服务器的支持:
- 从结构上,单个Redis服务器会发生单点故障,同时一台服务器需要承受所有的请求负载。这就需要为数据生成多个副本并分配在不同的服务器上:
- 从容量上,单个Redis服务器的内存非常容易成为存储瓶颈,所以需要进行数据分片。
同时拥有多个Redis服务器后就会面临如何管理集群的问题,包括如何增加节点、故障恢复等操作。
为此,下文将依次详细介绍Redis中的数据分片(data sharding)、复制(replication)、哨兵(sentinel)和集群(cluster)的使用和原理。
数据分片(Data sharding)
Background
长期以来,Redis 本身仅支持单实例,内存一般最多 10 ~ 20GB。这无法支撑大型线上业务系统的需求(比如当双11的时候,对于缓存容量的要求,往往会远高于平日)。而且也造成资源的利用率过低——毕竟现在服务器内存动辄 100 ~ 200GB。
为解决单机承载能力不足和弹性设置容量的问题,我们就有了各种数据分片(data sharding)技术。
下面一一做介绍。
客户端分片(Client Sharding)
传统的客户端分片
这种方案将分片工作放在业务程序端,程序代码根据预先设置的路由规则(比如,对key hash然后按 10 取模,结果为1则存到 Redis node1,结果为2则存到Redis node2,以此类推),直接对多个 Redis 实例进行分布式访问。
Java redis客户端驱动 Jedis,支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。
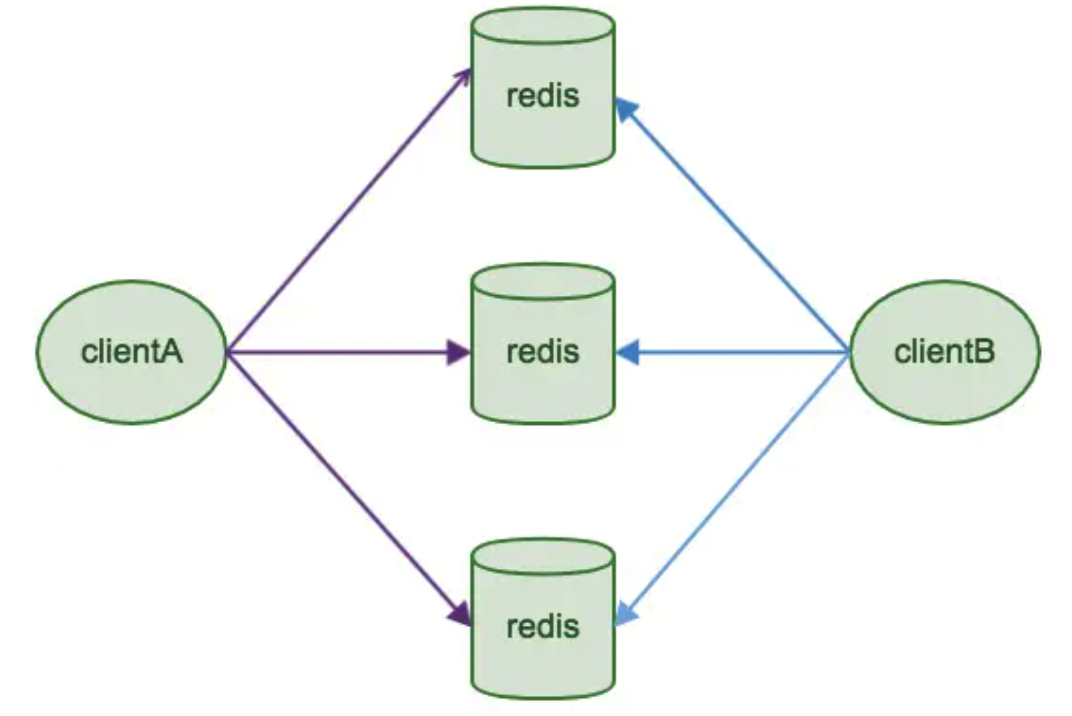
这样的好处是,非常简单,服务端的Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强。因为其不依赖于第三方分布式中间件,实现方法和代码都自己掌控,可随时调整,不用担心踩到坑。
另外,这种分片机制的性能比代理式更好(少了一个中间分发环节)。
这实际上是一种静态分片技术。Redis 实例的增减,都得手工调整分片程序。
客户端sharding的劣势也是很明显的
- 由于sharding处理放到客户端,规模进一步扩大时给运维带来挑战。客户端sharding不支持动态增删节点以扩容或缩容(无弹性)。
- 服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。连接不能共享,当应用规模增大时,资源浪费制约优化。
- 当某个Redis实例出现问题时,不太容易替换该节点
新一代的客户端分片 - Redis Cluster data sharding
Redis Cluster并非使用Porxy模式来连接集群节点,而是使用无中心节点的模式来组建集群(即没有coordinator)。
这意味着,client连接Redis Cluster时,Redis Cluster SDK需要计算出一个特定的key存在哪个Redis master node,通过 CRC16(key) mod 163484。
There are 16384 hash slots in Redis Cluster, and to compute what is the hash slot of a given key, we simply take the CRC16 of the key modulo 16384.
Every node in a Redis Cluster is responsible for a subset of the hash slots, so for example you may have a cluster with 3 nodes, where:
- Node A contains hash slots from 0 to 5500.
- Node B contains hash slots from 5501 to 11000.
- Node C contains hash slots from 11001 to 16383.
This allows to add and remove nodes in the cluster easily. For example if I want to add a new node D, I need to move some hash slot from nodes A, B, C to D. Similarly if I want to remove node A from the cluster I can just move the hash slots served by A to B and C. When the node A will be empty I can remove it from the cluster completely.
代理分片(Proxy Sharding)
这种方案,将分片工作交给专门的代理程序来做。代理程序接收到来自业务程序的数据请求,根据路由规则,将这些请求分发给正确的 Redis 实例并返回给业务程序。
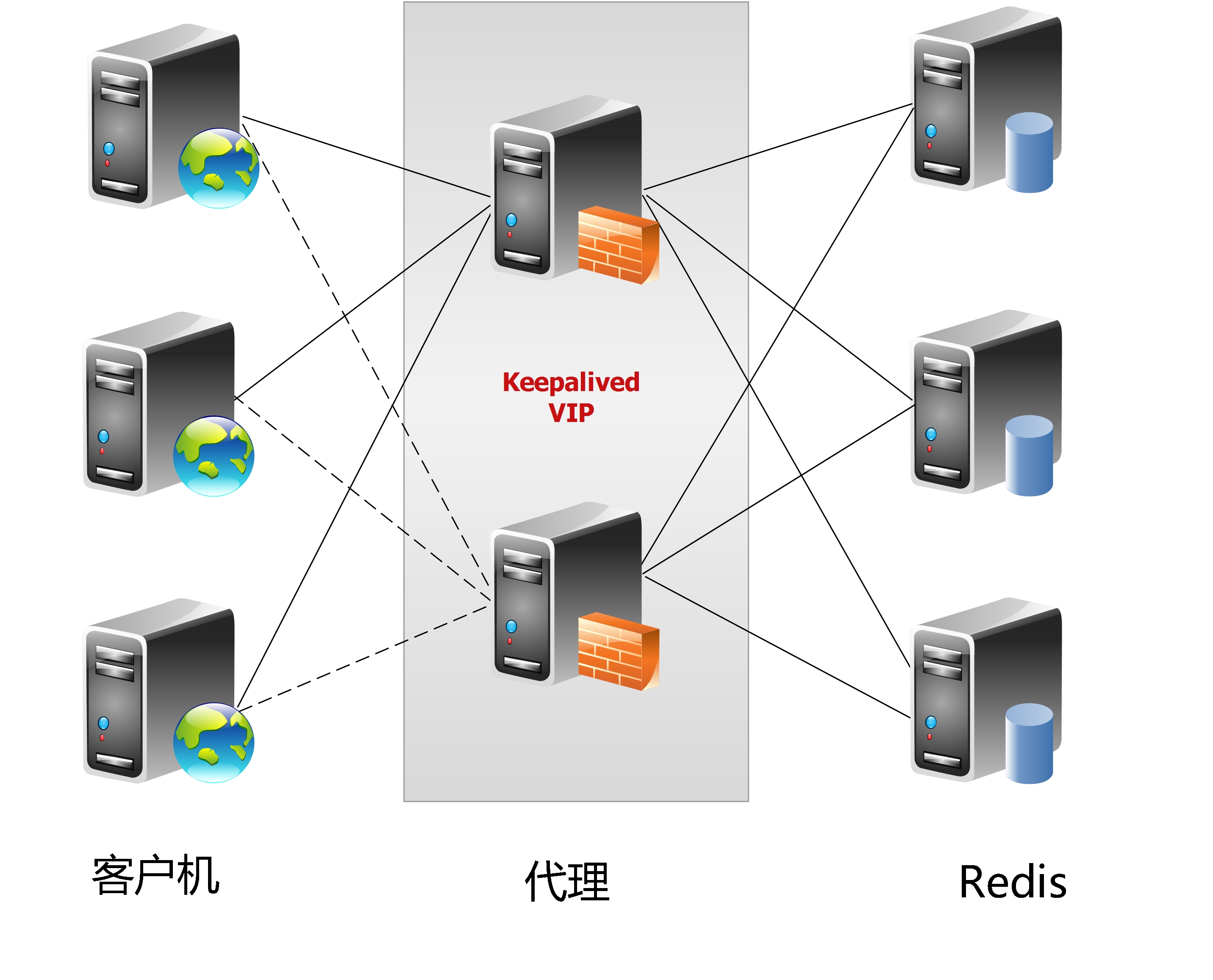
这样的好处是,业务程序不用关心后端 Redis 实例,运维起来也方便。虽然会因此带来些性能损耗,但对于 Redis 这种内存读写型应用,相对而言是能容忍的。
这是我们推荐的集群实现方案。基于该机制的开源产品: Twemproxy、Codis。
复制(replication)
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失) 数据。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。
为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。
为此, Redis提供了复制(replication)功能,可以实现当Master Redis node中的数据更新后(进行了写操作),自动将更新的数据同步到所有的Slave Redis node上。但不支持主主复制。
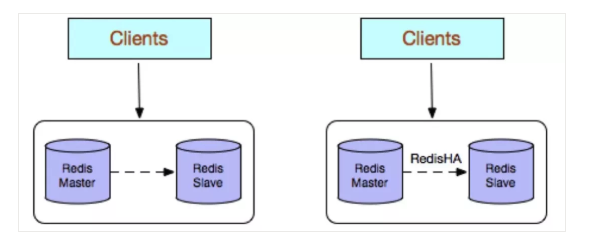
See https://redis.io/topics/replication for more details.
一致性保证(Consistency Guarantees)
Synchronous replication of certain data can be requested by the clients using the WAIT command.
However WAIT is only able to ensure that there are the specified number of acknowledged copies in the other Redis instances, it does not turn a set of Redis instances into a CP system with strong consistency: acknowledged writes can still be lost during a failover, depending on the exact configuration of the Redis persistence. However with WAIT the probability of losing a write after a failure event is greatly reduced to certain hard to trigger failure modes.
Redis Cluster is not able to guarantee strong consistency. In practical terms this means that under certain conditions it is possible that Redis Cluster will lose writes that were acknowledged by the system to the client.
The first reason why Redis Cluster can lose writes is because it uses asynchronous replication. This means that during writes the following happens:
- Your client writes to the master B.
- The master B replies OK to your client.
- The master B propagates the write to its slaves B1, B2 and B3.
As you can see, B does not wait for an acknowledgement from B1, B2, B3 before replying to the client, since this would be a prohibitive latency penalty for Redis, so if your client writes something, B acknowledges the write, but crashes before being able to send the write to its slaves, one of the slaves (that did not receive the write) can be promoted to master, losing the write forever.
See https://redis.io/topics/replication for more details.
优缺点
优点
- 高可靠性:一方面,采用双机主备架构(master-slave architecture),能够在主库出现故障时自动进行主备切换,从库提升为主库提供服务,保证服务平稳运行;另一方面,开启数据持久化功能和配置合理的备份策略,能有效的解决数据误操作和数据异常丢失的问题;
- 读写分离策略:从节点可以扩展主库节点的读能力,有效应对大并发量的读操作。
缺点
- 故障恢复(failure recovery)复杂,如果没有 RedisHA 系统(需要开发),当 master Redis node 出现故障时,需要手动将一个 slave Redis node 晋升为master Redis node,同时需要通知业务方变更配置,整个过程需要人为干预,比较繁琐;
- 主库的写能力受到单机的限制,可以考虑数据分片(data sharding),即将数据基于一定的规则(比如CRC16)存储到多个Redis node中;
- 主库的存储能力受到单机的限制,同样可以考虑数据分片(data sharding)。
哨兵(Sentinel)- High Availability
Background
在一个典型的一主多从的Redis系统中, Slava Redis Node 在整个系统中起到了数据冗余备份和读写分离的作用。当 Master Redis Node 遇到异常中断服务后,运维人员可以通过手动的方式选择一个 Slava Redis Node 来升格为Master Redis Node ,以使得系统能够继续提供服务。
为此,Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。
顾名思义,哨兵的作用就是监控Redis系统的运行状况。它的功能包括:
- 监控Master Redis node和Slave Redis node是否正常运行,
- Master Redis node出现故障时自动将Slave Redis node转换为Master Redis node。
Redis Sentinel
Redis Sentinel provides high availability for Redis. In practical terms this means that using Sentinel you can create a Redis deployment that resists without human intervention certain kinds of failures.
Redis Sentinel also provides other collateral tasks such as monitoring, notifications and acts as a configuration provider for clients.
This is the full list of Sentinel capabilities at a macroscopical level (i.e. the big picture):
- Monitoring. Sentinel constantly checks if your master and replica instances are working as expected.
- Notification. Sentinel can notify the system administrator, or other computer programs, via an API, that something is wrong with one of the monitored Redis instances.
- Automatic failover. If a master is not working as expected, Sentinel can start a failover process where a replica is promoted to master, the other additional replicas are reconfigured to use the new master, and the applications using the Redis server are informed about the new address to use when connecting.
- Configuration provider. Sentinel acts as a source of authority for clients service discovery: clients connect to Sentinels in order to ask for the address of the current Redis master responsible for a given service. If a failover occurs, Sentinels will report the new address.
See https://redis.io/topics/sentinel for more details.
哨兵是一个独立的进程,使用哨兵的一个典型架构如下图所示。
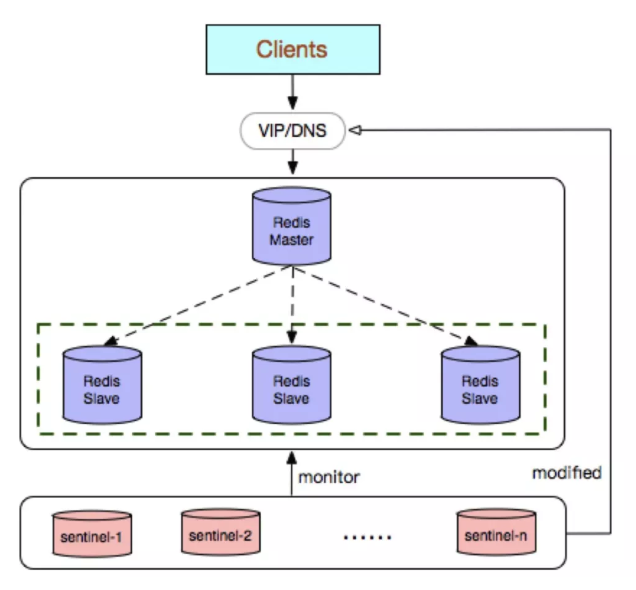
在一个一主多从的Redis系统中,可以使用多个哨兵进行监控任务以保证系统足够稳健, 如下图所示。注意,此时不仅哨兵会同时监控Master Redis node和Slave Redis node,哨兵之间也会互相监控。
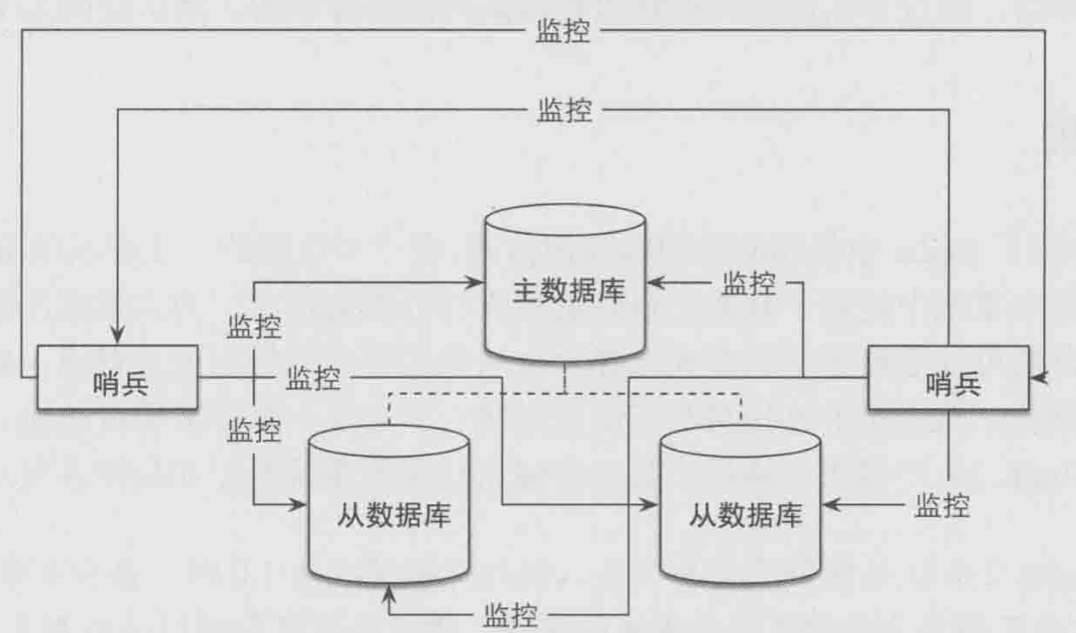
优缺点
优点
- Redis Sentinel 集群部署简单;
- 能够解决 Redis 主从模式下的高可用切换问题;
- 很方便实现 Redis 数据节点的线形扩展,轻松突破 Redis 自身单线程瓶颈,可极大满足 Redis 大容量或高性能的业务需求;
- 可以实现一套 Sentinel 监控一组 Redis 数据节点或多组数据节点。
缺点
- 部署相对 Redis 主从模式要复杂一些,原理理解更繁琐;
- 资源浪费,Redis 数据节点中 slave 节点作为备份节点不提供服务;
Redis Cluster(Redis 集群解决方案) - Redis 水平扩容
即使使用哨兵,此时的Redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储量受限于可用存储内存最小的数据库节点,形成木桶效应。由于Redis 中的所有数据都是基于内存存储,这一问题就尤为突出了,尤其是当使用Redis做持久化存储服务使用时。
对Redis进行水平扩容(horizential scaling),在旧版Redis中通常使用客户端分片(client Sharding)来解决这个问题,即启动多个Redis数据库节点,由客户端决定每个 key 交由哪个 Redis node 存储,下次客户端读取该 key 时,直接到该节点读取即可。
这样可以实现将整个数据分布存储在N个Redis node 中,每个 node 只存放总数据量的1/N。
对于需要扩容的场景来说,在客户端分片后,如果想增加更多的节点(这是很有可能的,比如整个 Redis 集群的memory usage快满了,或者performance bottleneck),就需要对数据进行手工迁移,同时在迁移的过程中为了保证数据的一致性, 还需要将集群暂时下线,相对比较复杂。
Redis Cluster data sharding
Redis Cluster does not use consistent hashing, but a different form of sharding where every key is conceptually part of what we call an hash slot.
There are 16384 hash slots in Redis Cluster, and to compute what is the hash slot of a given key, we simply take the CRC16 of the key modulo 16384.
Every node in a Redis Cluster is responsible for a subset of the hash slots, so for example you may have a cluster with 3 nodes, where:
- Node A contains hash slots from 0 to 5500.
- Node B contains hash slots from 5501 to 11000.
- Node C contains hash slots from 11001 to 16383.
This allows to add and remove nodes in the cluster easily. For example if I want to add a new node D, I need to move some hash slot from nodes A, B, C to D. Similarly if I want to remove node A from the cluster I can just move the hash slots served by A to B and C. When the node A will be empty I can remove it from the cluster completely.
Because moving hash slots from a node to another does not require to stop operations, adding and removing nodes, or changing the percentage of hash slots hold by nodes, does not require any downtime.
Redis Cluster supports multiple key operations as long as all the keys involved into a single command execution (or whole transaction, or Lua script execution) all belong to the same hash slot. The user can force multiple keys to be part of the same hash slot by using a concept called hash tags.
Hash tags are documented in the Redis Cluster specification, but the gist is that if there is a substring between {} brackets in a key, only what is inside the string is hashed, so for example this{foo}key and another{foo}key are guaranteed to be in the same hash slot, and can be used together in a command with multiple keys as arguments.
See https://redis.io/topics/cluster-tutorial for more details.
总结
哨兵与 Redis Cluster(Redis 集群解决方案) 没有太多的联系:
- 哨兵主要解决的是high-availability问题,即当一个 master Redis node挂了之后,我们需要一个自动化机制,使得 slave node自动取代 master Redis node(当然有一个前提,是我们配置了slave node),并成为一个新的 master node。
- 而 Redis Cluster 是一个Redis 集群解决方案,它主要为了解决水平扩容(horizential scaling)问题。
在 Redis Cluster 中,也为实现 high-availability 提供了 solution,即 failure failover,这个机制与哨兵机制稍有不同(当然他们都是为了实现 high-availability )。
换言之,当不需要数据分片(虽然这个assumption往往是不正确的,因为我们怎么能保证在最开始建立一个系统时,我们就知道需要多少数据量,且在此之后我们的系统永远不会超过这个数据量),或者己经在客户端进行 sharding 的场景下,哨兵就足够使用了。
但如果需要进行水平扩容(horizential scaling), 则 Redis Cluster 是一个非常好的选择。
Reference
- https://redis.io/topics/replication
- https://redis.io/topics/cluster-tutorial
- https://redis.io/topics/sentinel
- https://www.infoq.cn/article/effective-ops-part-03/?utm_campaign=infoq_content&utm_source=infoq&utm_medium=feed&utm_term=