Background
Redis is a TCP server using the client-server model and what is called a Request/Response protocol.
This means that usually a request is accomplished with the following steps:
- The client sends a query to the server, and reads from the socket, usually in a blocking way, for the server response.
- The server processes the command and sends the response back to the client.
So for instance a four commands sequence is something like this:
- Client: INCR X
- Server: 1
- Client: INCR X
- Server: 2
- Client: INCR X
- Server: 3
- Client: INCR X
- Server: 4
Clients and Servers are connected via a networking link. Such a link can be very fast (a loopback interface) or very slow (a connection established over the Internet with many hops between the two hosts). Whatever the network latency is, there is a time for the packets to travel from the client to the server, and back from the server to the client to carry the reply.
This time is called RTT (Round Trip Time). It is very easy to see how this can affect the performances when a client needs to perform many requests in a row (for instance adding many elements to the same list, or populating a database with many keys). For instance if the RTT time is 250 milliseconds (in the case of a very slow link over the Internet), even if the server is able to process 100k requests per second, we’ll be able to process at max four requests per second.
If the interface used is a loopback interface, the RTT is much shorter (for instance my host reports 0,044 milliseconds pinging 127.0.0.1), but it is still a lot if you need to perform many writes in a row.
Fortunately there is a way to improve this use case.
Redis Pipelining
A Request/Response server can be implemented so that it is able to process new requests even if the client didn’t already read the old responses. This way it is possible to send multiple commands to the server without waiting for the replies at all, and finally read the replies in a single step.
This is called pipelining, and is a technique widely in use since many decades.
IMPORTANT NOTE: While the client sends commands using pipelining, the server will be forced to queue the replies, using memory. So if you need to send a lot of commands with pipelining, it is better to send them as batches having a reasonable number, for instance 10k commands, read the replies, and then send another 10k commands again, and so forth. The speed will be nearly the same, but the additional memory used will be at max the amount needed to queue the replies for these 10k commands.
It’s not just a matter of RTT
Pipelining is not just a way in order to reduce the latency cost due to the round trip time, it actually improves by a huge amount the total operations you can perform per second in a given Redis server. This is the result of the fact that, without using pipelining, serving each command is very cheap from the point of view of accessing the data structures and producing the reply, but it is very costly from the point of view of doing the socket I/O. This involves calling the read() and write() syscall, that means going from user land to kernel land. The context switch is a huge speed penalty.
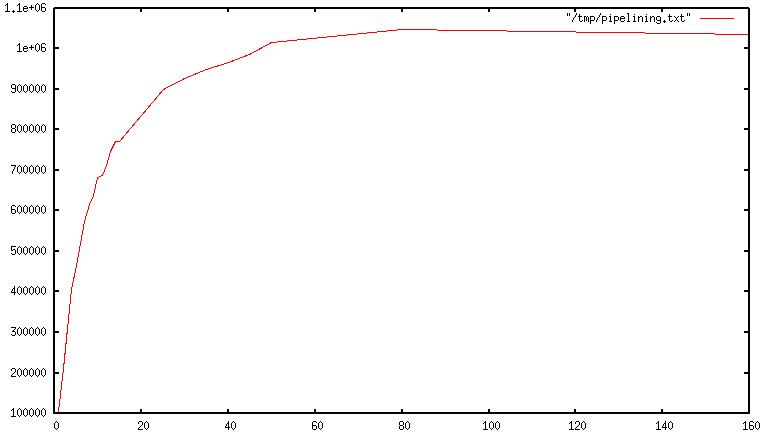
When pipelining is used, many commands are usually read with a single read() system call, and multiple replies are delivered with a single write() system call. Because of this, the number of total queries performed per second initially increases almost linearly with longer pipelines, and eventually reaches 10 times the baseline obtained not using pipelining, as you can see from the following graph:
Pipeline 和 Transaction 的区别
- pipeline的执行会在 client 缓存(这意味着,在pipeline开始执行后,而执行
EXEC之前,都不会有为了这次 pipeline 而进行的 TCP通信),而 Transaction 的执行会在 redis server缓存; - 请求次数的不一致,multi需要每个命令都发送一次给服务端,pipeline最后一次性发送给服务端,请求次数相对于multi减少
- multi/exec可以保证原子性,而pipeline不保证原子性
Experiment
Pipeline
p := client.Pipeline()
p.SAdd("saddKey", []string{"1", "2", "3"})
p.Set("cache1", "aabbcc", 0)
cmders, err := p.Exec()
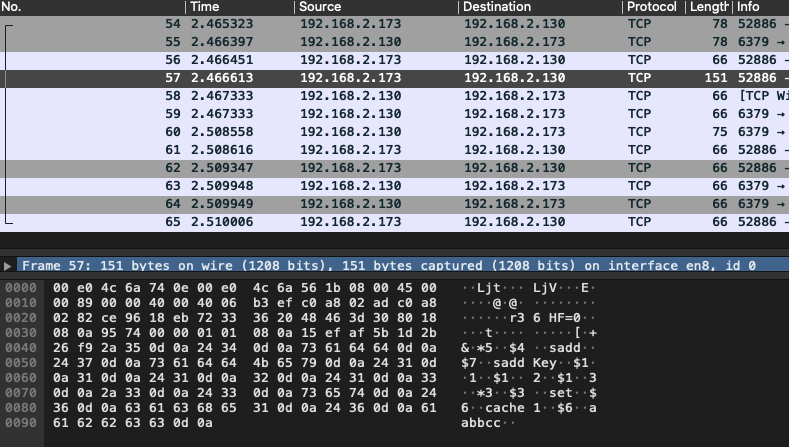
client 将待执行的命令写入到自己的缓冲区(client-buffer)中,最后当调用 EXEC 命令时,(通过 TCP 通讯)一次性发送给 redis server 以执行。
但是有一种情况是,client 缓冲区(client-buffer)的大小是有限制的(这当然与client 具体的实现也有关系),比如Jedis,限制为8192,超过了,则刷缓存,发送请求到Redis,
Transaction
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set aaabbbccc 123456
QUEUED
127.0.0.1:6379> set cccbbbaaa 987654
QUEUED
127.0.0.1:6379> get aaabbbccc
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) OK
3) "123456"
我们总共执行了5条命令,每条命令都会有对应的TCP通讯(每次通讯都会附上这条命令对应的执行内容):
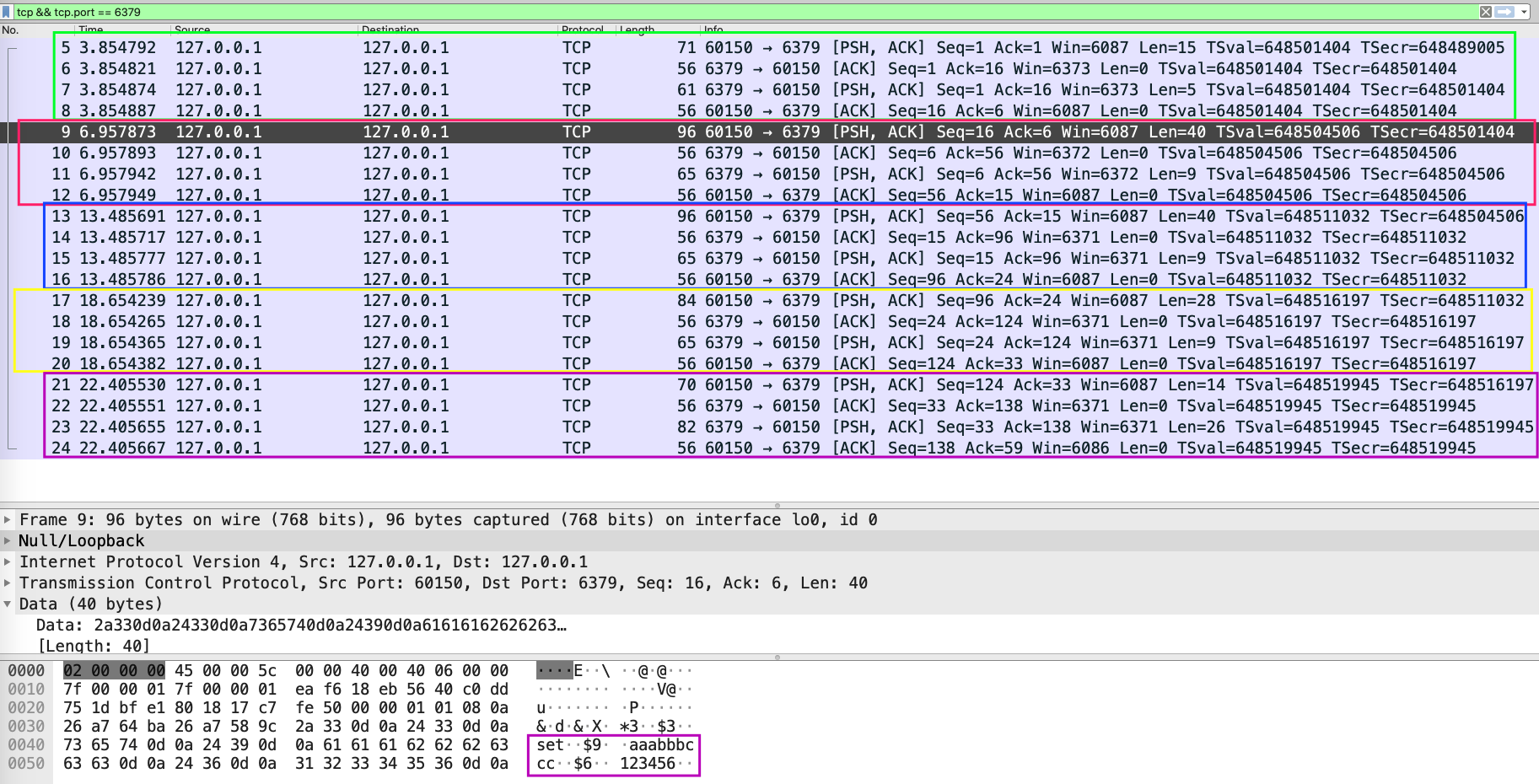
这点其实是相比较 pipeline而言的,在 pipeline中,所有command都会缓存在 client,只有当执行 EXEC 命令时,才会进行TCP 通讯。
这也意味着,如果执行大量的 transaction,redis server的memory usage会上升(因为有大量未被执行的command 被缓存在 redis server的memory中);而如果执行大量的 pipeline(而每个pipeline中执行命令数量不多或者这些命令对应执行后的结果的数据量并不大),这时候并不会消耗很多的redis server memory。