Background
Context Swtitches
https://en.wikipedia.org/wiki/Context_switch
虽然线程比较轻量,但是在调度时也有比较大的额外开销。每个线程会都占用 1M 以上的内存空间,在切换线程时不止会消耗较多的内存,恢复寄存器中的内容还需要向操作系统申请或者销毁资源,每一次线程上下文的切换都需要消耗 ~1us 左右的时间,但是 Go 调度器对 Goroutine 的上下文切换约为 ~0.2us,减少了 80% 的额外开销。
History
今天的 Go 语言调度器有着优异的性能,但是如果我们回头看 Go 语言的 0.x 版本的调度器会发现最初的调度器不仅实现非常简陋,也无法支撑高并发的服务。调度器经过几个大版本的迭代才有今天的优异性能,历史上几个不同版本的调度器引入了不同的改进,也存在着不同的缺陷:
- 单线程调度器 - 0.x
- 只包含 40 多行代码;
- 程序中只能存在一个活跃线程,由 G-M 模型组成;
- 多线程调度器 - 1.0
- 允许运行多线程的程序;
- 全局锁导致竞争严重;
- 任务窃取调度器 - 1.1
- 引入了处理器 P,构成了目前的 G-M-P 模型;
- 在处理器 P 的基础上实现了基于工作窃取的调度器;
- 在某些情况下,Goroutine 不会让出线程,进而造成饥饿问题;
- 时间过长的垃圾回收(Stop-the-world,STW)会导致程序长时间无法工作;
- 抢占式调度器 - 1.2 ~ 至今
- 基于协作的抢占式调度器 - 1.2 ~ 1.13
- 通过编译器在函数调用时插入抢占检查指令,在函数调用时检查当前 Goroutine 是否发起了抢占请求,实现基于协作的抢占式调度;
- Goroutine 可能会因为垃圾回收和循环长时间占用资源导致程序暂停;
- 基于信号的抢占式调度器 - 1.14 ~ 至今
- 实现基于信号的真抢占式调度;
- 垃圾回收在扫描栈时会触发抢占调度;
- 抢占的时间点不够多,还不能覆盖全部的边缘情况;
- 基于协作的抢占式调度器 - 1.2 ~ 1.13
- 非均匀存储访问调度器 · 提案
- 对运行时的各种资源进行分区;
- 实现非常复杂,到今天还没有提上日程;
除了多线程、任务窃取和抢占式调度器之外,Go 语言社区目前还有一个非均匀存储访问(Non-uniform memory access,NUMA)调度器的提案。在这一节中,我们将依次介绍不同版本调度器的实现原理以及未来可能会实现的调度器提案。
单线程调度器
0.x 版本调度器只包含表示 Goroutine 的 G 和表示线程的 M 两种结构,全局也只有一个线程。我们可以在 clean up scheduler 提交中找到单线程调度器的源代码,在这时 Go 语言的调度器还是由 C 语言实现的,调度函数 runtime.scheduler:9682400也只包含 40 多行代码 :
static void scheduler(void) {
G* gp;
lock(&sched);
if(gosave(&m->sched)){
lock(&sched);
gp = m->curg;
switch(gp->status){
case Grunnable:
case Grunning:
gp->status = Grunnable;
gput(gp);
break;
...
}
notewakeup(&gp->stopped);
}
gp = nextgandunlock();
noteclear(&gp->stopped);
gp->status = Grunning;
m->curg = gp;
g = gp;
gogo(&gp->sched);
}
该函数会遵循如下的过程调度 Goroutine:
- 获取调度器的全局锁;
- 调用
runtime.gosave:9682400] 保存栈寄存器和程序计数器; - 调用
runtime.nextgandunlock:9682400获取下一个需要运行的 Goroutine 并解锁调度器; - 修改全局线程
m上要执行的 Goroutine; - 调用
runtime.gogo:9682400函数运行最新的 Goroutine;
虽然这个单线程调度器的唯一优点就是能运行,但是这次提交已经包含了 G 和 M 两个重要的数据结构,也建立了 Go 语言调度器的框架。
多线程调度器 - G-M 模型

2012年3月28日,Go 1.0正式发布。在这个版本中支持了多线程的调度器。在这个调度器中,
- G:每个goroutine对应于runtime中的一个抽象结构
- M(machine):OS thread,即作为“物理CPU”的存在而被抽象为一个结构
与上一个版本几乎不可用的调度器相比,Go 语言团队在这一阶段实现了从不可用到可用的跨越。我们可以在 pkg/runtime/proc.c 文件中找到 1.0.1 版本的调度器,多线程版本的调度函数 runtime.schedule:go1.0.1 包含 70 多行代码,我们在这里保留了该函数的核心逻辑:
static void schedule(G *gp) {
schedlock();
if(gp != nil) {
gp->m = nil;
uint32 v = runtime·xadd(&runtime·sched.atomic, -1<<mcpuShift);
if(atomic_mcpu(v) > maxgomaxprocs)
runtime·throw("negative mcpu in scheduler");
switch(gp->status){
case Grunning:
gp->status = Grunnable;
gput(gp);
break;
case ...:
}
} else {
...
}
gp = nextgandunlock();
gp->status = Grunning;
m->curg = gp;
gp->m = m;
runtime·gogo(&gp->sched, 0);
}
整体的逻辑与单线程调度器没有太多区别,因为我们的程序中可能同时存在多个活跃线程,所以多线程调度器引入了 GOMAXPROCS 变量帮助我们灵活控制程序中的最大处理器数,即活跃线程数。
Google工程师Dmitry Vyukov在其《Scalable Go Scheduler Design》一文中指出了G-M模型的一个重要不足: 限制了Go并发程序的伸缩性,尤其是对那些有高吞吐或并行计算需求的服务程序。主要体现在如下几个方面:
-
单一全局互斥锁
Sched.Lock和集中状态存储的存在导致所有goroutine相关操作,比如:创建、完成、重新调度等都要上锁,从而导致锁竞争;- Note:创建goroutine需要一个全局锁看起来无法避免,但是“重新调度”时需要需要碰到全局锁就可能导致throughput大大降低了。解决办法可以是缩小锁的粒度
-
goroutine传递问题(hand-off):M经常在M之间传递 Runnable goroutine,这导致调度延迟增大以及额外的性能损耗;
- Note:每个goroutine都需要占用一定的内存,或者每个goroutine所执行代码不同,因而当一个goroutine从一个M切换到另外一个M时,(在最坏的情况下),这两个M可能处于不同的Core,因而可能出现CPU cache miss的情况,因而需要把这个stack从memory load到CPU cache中
-
Per-M memory cache (M.mcache). Memory cache and other caches (stack alloc) are associated with all M’s, while they need to be associated only with M’s running Go code (an M blocked inside of syscall does not need mcache). A ratio between M’s running Go code and all M’s can be as high as 1:100. This leads to excessive resource consumption (each MCache can suck up up to 2M) and poor data locality.
-
Aggressive thread blocking/unblocking. In presence of syscalls worker threads are frequently blocked and unblocked. This adds a lot of overhead.
这里的全局锁问题和 Linux 操作系统调度器在早期遇到的问题比较相似,解决的方案也都大同小异。
运行时 G-M-P 模型中引入的处理器 P 是线程和 Goroutine 的中间层(在Golang 1.2中实现),我们从它的结构体中就能看到处理器与 M 和 G 的关系:
struct P {
Lock;
uint32 status;
P* link;
uint32 tick;
M* m;
MCache* mcache;
G** runq;
int32 runqhead;
int32 runqtail;
int32 runqsize;
G* gfree;
int32 gfreecnt;
};
处理器持有一个由可运行的 Goroutine 组成的环形的运行队列 runq,还反向持有一个线程。调度器在调度时会从处理器的队列中选择队列头的 Goroutine 放到线程 M 上执行。如下所示的图片展示了 Go 语言中的线程 M、处理器 P 和 Goroutine 的关系。
抢占式调度器(preemptive scheduler)- G-M-P 模型
基于协作(co-operative)的抢占式调度
对 Go 语言并发模型的修改提升了调度器的性能,但是 1.1 版本中的调度器仍然不支持抢占式调度,程序只能依靠 Goroutine 主动让出 CPU 资源才能触发调度。
Dmitry Vyukov提出了《Go Preemptive Scheduler Design》,并在Go 1.2中实现了基于协作抢占式调度。
这解决下面的问题:
- 某些 Goroutine 可以长时间占用线程,造成其它 Goroutine 的饥饿;
- 比如,某个G中出现死循环或永久循环的代码逻辑,那么G将永久占用分配给它的P和M,位于同一个P中的其他G将得不到调度,出现“饿死”的情况。
- 垃圾回收需要暂停整个程序(Stop-the-world,STW),最长可能需要几分钟的时间,导致整个程序无法工作;
1.2 版本的抢占式调度虽然能够缓解这个问题,但是它实现的抢占式调度是基于协作的,它的原理是在每个函数或方法的入口,加上一段额外的代码,让runtime有机会检查是否需要执行抢占调度。这种解决方案只能说局部解决了“饿死”问题,对于没有函数调用,纯算法循环计算的G,scheduler依然无法抢占。
在之后很长的一段时间里 Go 语言的调度器都没有这些无法抢占的边缘情况,直到 1.14 这些问题中的一部分才被基于信号的抢占式调度解决。
基于协作的抢占式调度的工作原理:
- 编译器会在调用函数前插入
runtime.morestack; - Go 语言运行时会在垃圾回收暂停程序、系统监控发现 Goroutine 运行超过 10ms 时发出抢占请求
StackPreempt; - 当发生函数调用时,可能会执行编译器插入的
runtime.morestack,它调用的runtime.newstack会检查 Goroutine 的stackguard0字段是否为StackPreempt; - 如果
stackguard0是StackPreempt,就会触发抢占让出当前线程;
这种实现方式虽然增加了运行时的复杂度,但是实现相对简单,也没有带来过多的额外开销,总体来看还是比较成功的实现,也在 Go 语言中使用了十几个版本。因为这里的抢占是通过编译器插入函数实现的,还是需要函数调用作为入口才能触发抢占,所以这是一种协作式的抢占式调度。
基于信号的抢占式调度/非协作的抢占式调度(Non-cooperative preemption)
Go currently uses compiler-inserted cooperative preemption points in function prologues. The majority of the time, this is good enough to allow Go developers to ignore preemption and focus on writing clear parallel code, but it has sharp edges that we’ve seen degrade the developer experience time and time again. When it goes wrong, it goes spectacularly wrong, leading to mysterious system-wide latency issues and sometimes complete freezes. And because this is a language implementation issue that exists outside of Go’s language semantics, these failures are surprising and very difficult to debug.
Go 语言在 1.14 版本中实现了非协作的抢占式调度(Non-cooperative preemption)。
目前的抢占式调度也只会在正在执行垃圾回收扫描任务时被触发,抢占式调度过程:
- 程序启动时,在
runtime.sighandler中注册SIGURG信号的处理函数runtime.doSigPreempt; - 在触发垃圾回收的栈扫描时会调用
runtime.suspendG挂起 Goroutine,该函数会执行下面的逻辑:- 将
_Grunning状态的 Goroutine 标记成可以被抢占,即将preemptStop设置成true; - 调用
runtime.preemptM触发抢占;
- 将
runtime.preemptM会调用runtime.signalM向线程发送信号SIGURG;- 操作系统会中断正在运行的线程并执行预先注册的信号处理函数
runtime.doSigPreempt; runtime.doSigPreempt函数会处理抢占信号,获取当前的 SP 和 PC 寄存器并调用runtime.sigctxt.pushCall;runtime.sigctxt.pushCall会修改寄存器并在程序回到用户态时执行runtime.asyncPreempt;- 汇编指令
runtime.asyncPreempt会调用运行时函数runtime.asyncPreempt2; runtime.asyncPreempt2会调用runtime.preemptPark;runtime.preemptPark会修改当前 Goroutine 的状态到_Gpreempted并调用runtime.schedule让当前函数陷入休眠并让出线程,调度器会选择其它的 Goroutine 继续执行;
上述 9 个步骤展示了基于信号的抢占式调度的执行过程。除了分析抢占的过程之外,我们还需要讨论一下抢占信号的选择,提案根据以下的四个原因选择 SIGURG 作为触发异步抢占的信号;
- 该信号需要被调试器透传;
- 该信号不会被内部的 libc 库使用并拦截;
- 该信号可以随意出现并且不触发任何后果;
- 我们需要处理多个平台上的不同信号;
STW 和栈扫描是一个可以抢占的安全点(Safe-points),所以 Go 语言会在这里先加入抢占功。基于信号的抢占式调度只解决了垃圾回收和栈扫描时存在的问题,它到目前为止没有解决所有问题,但是这种真抢占式调度是调度器走向完备的开始,相信在未来我们会在更多的地方触发抢占。
Go Scheduler
于是Dmitry Vyukov亲自操刀改进Go scheduler,在Go 1.1中实现了G-P-M调度模型和 work stealing算法,这个模型一直沿用至今。
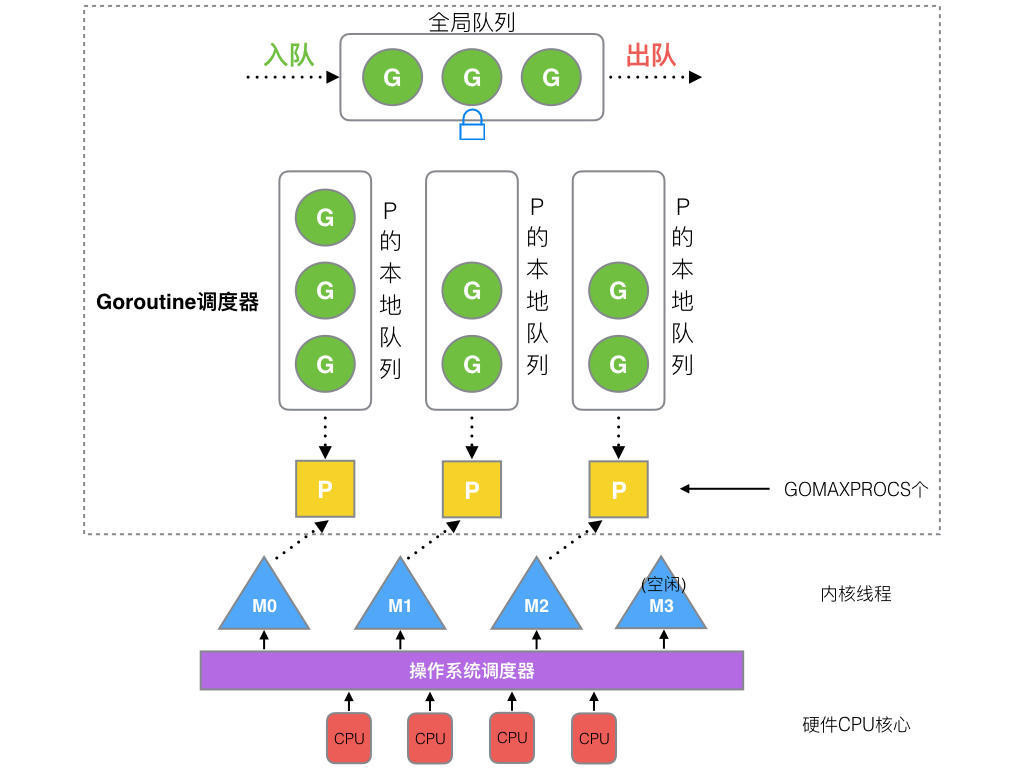
有名人曾说过:“计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决”,我觉得Dmitry Vyukov的G-P-M模型恰是这一理论的践行者。Dmitry Vyukov通过向G-M模型中增加了一个P,实现了Go scheduler的scalable。
- M(machine):代表真正的可执行计算的资源,是由系统管理的进程,也就是上面的N个系统进程的缩影,是真正干活的。
- G:代表着goroutines, 它有自己的栈,计数器(instruction pointer),以及其他调度需要的重要数据。
- Goroutine 是 Go 语言调度器中待执行的任务,它在运行时调度器中的地位与线程在操作系统中差不多,但是它占用了更小的内存空间,也降低了上下文切换的开销。
- P(logical processor):可以理解为在一个M(OS线程)上的调度器,即局部调度器。它需要获取操作系统线程(M)以运行G,它是实现从N:1到M:N的关键。
- 每个P都会有自己的队列(称为local run queue)
- Goroutine 只存在于 Go 语言的运行时,它是 Go 语言在用户态提供的线程,作为一种粒度更细的资源调度单元,如果使用得当能够在高并发的场景下更高效地利用机器的 CPU。
- 通过
runtime.GOMAXPROCS(numLogicalProcessors)可以控制最多多少个P会被创建。如果你需要调整这个参数,只需要设置一次,且只应该设置一次, 因为它需要STWgc pause。
P是一个“逻辑Proccessor”,每个G要想真正被运行起来,首先需要被分配给一个P(进入到P的local run queue中,或进入global run queue)。对于G来说,P就是运行它的“CPU”,可以说:G的眼里只有P。
但从Go scheduler视角来看,真正的“CPU”是M,只有将P和M绑定才能让P的runq中G得以真实运行起来。这样的P与M的关系,就好比Linux操作系统调度层面用户线程(user thread)与核心线程(kernel thread)的对应关系那样(N x M)。
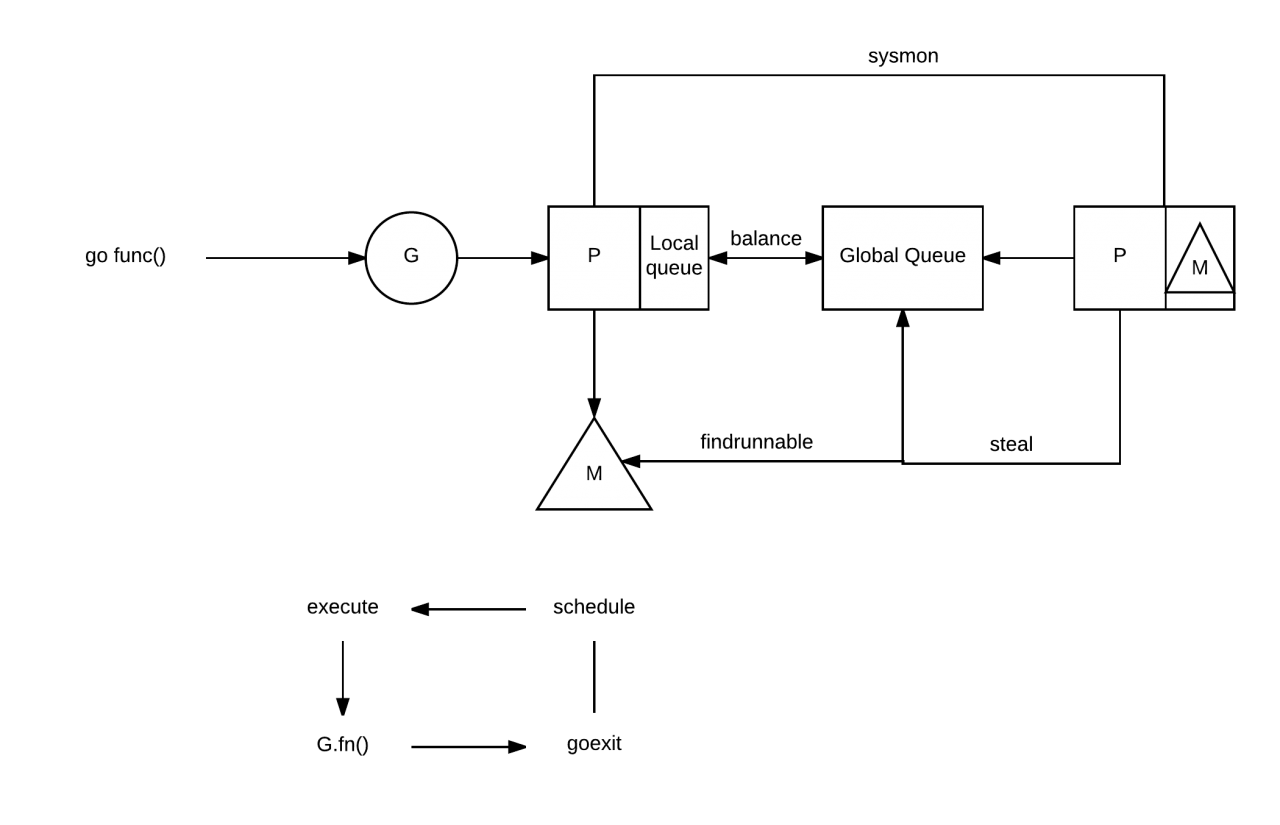
**我们应该从哪里运行下一个goroutine?**在Go中,轮询顺序定义如下:
- 本地运行队列(local run queue)
- 全局运行队列(global run queue)
- 网络轮询器(netpull)
- 工作偷窃(work stealing)
Go运行时会在下面的goroutine被阻塞的情况下运行另外一个goroutine:
- blocking syscall (for example opening a file)
- network input
- channel operations,
- primitives in the sync package
为什么需要P
调度器为啥需要这个P呢?直接将runqueues放在M上,不是就挺好?事实并非如此,比如我们其中一个系统线程因为某种原因就是被blocked了(比如发生了blocking I/O),该怎么办呢?需要对队列中所有G进行转移,而如果有P这一层的存在,只需要P寻求一个新的M就好了,这样是不是更高效,更合理。
例如,我们有一个系统调用阻塞了一个系统进程,也就是一个M(称为M0)被阻塞了,为了G还能正常被调度,这时需要把P从这个M上转移走。
当这个系统调用返回时(完成或失败),M0自然也就不是阻塞状态了,这时M0为了能继续执行G0必须尝试去获取一个上下文P。常规操作是去别的M上“偷”一个P过来。但是如果偷失败了,那么只能将G0放到全局的runqueues中,把自身放到线程池中等待被使用。
每个P在执行完自己的队列后都会去全局的队列中拉新的G下来执行。当然,每个P其实也是会定期检查一下全局队列是否有G, 不然放到全局的这些G可能就卡死了,甚至由于没有P可用,永远不能执行了。
正是因为调度器对系统调用的处理方式,即便将GOMAXPROCS设置为1,也不会有问题。
Source Code
G
// /usr/local/go/src/runtime/runtime2.go
type g struct {
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the C stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
param unsafe.Pointer // passed parameter on wakeup
atomicstatus uint32 // status of this goroutine
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
goid int64
schedlink guintptr
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
preemptShrink bool // shrink stack at synchronous safe point
// asyncSafePoint is set if g is stopped at an asynchronous
// safe point. This means there are frames on the stack
// without precise pointer information.
asyncSafePoint bool
paniconfault bool // panic (instead of crash) on unexpected fault address
gcscandone bool // g has scanned stack; protected by _Gscan bit in status
throwsplit bool // must not split stack
// activeStackChans indicates that there are unlocked channels
// pointing into this goroutine's stack. If true, stack
// copying needs to acquire channel locks to protect these
// areas of the stack.
activeStackChans bool
raceignore int8 // ignore race detection events
sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
sysexitticks int64 // cputicks when syscall has returned (for tracing)
traceseq uint64 // trace event sequencer
tracelastp puintptr // last P emitted an event for this goroutine
lockedm muintptr
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
gopc uintptr // pc of go statement that created this goroutine
ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
timer *timer // cached timer for time.Sleep
selectDone uint32 // are we participating in a select and did someone win the race?
// Per-G GC state
// gcAssistBytes is this G's GC assist credit in terms of
// bytes allocated. If this is positive, then the G has credit
// to allocate gcAssistBytes bytes without assisting. If this
// is negative, then the G must correct this by performing
// scan work. We track this in bytes to make it fast to update
// and check for debt in the malloc hot path. The assist ratio
// determines how this corresponds to scan work debt.
gcAssistBytes int64
}
结构体 runtime.g 的 atomicstatus 字段存储了当前 Goroutine 的状态。除了几个已经不被使用的以及与 GC 相关的状态之外,Goroutine 可能处于以下 9 种状态:
| 状态 | 描述 |
|---|---|
_Gidle |
刚刚被分配并且还没有被初始化 |
_Grunnable |
没有执行代码,没有栈的所有权,存储在运行队列中 |
_Grunning |
可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P |
_Gsyscall |
正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上 |
_Gwaiting |
由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上 |
_Gdead |
没有被使用,没有执行代码,可能有分配的栈 |
_Gcopystack |
栈正在被拷贝,没有执行代码,不在运行队列上 |
_Gpreempted |
由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒 |
_Gscan |
GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 |
虽然 Goroutine 在运行时中定义的状态非常多而且复杂,但是我们可以将这些不同的状态聚合成三种:等待中、可运行、运行中,运行期间会在这三种状态来回切换:
- 等待中:Goroutine 正在等待某些条件满足,例如:系统调用结束等,包括
_Gwaiting、_Gsyscall和_Gpreempted几个状态; - 可运行:Goroutine 已经准备就绪,可以在线程运行,如果当前程序中有非常多的 Goroutine,每个 Goroutine 就可能会等待更多的时间,即
_Grunnable; - 运行中:Goroutine 正在某个线程上运行,即
_Grunning;
M
Go 语言并发模型中的 M 是操作系统线程。调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行。
在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数,我们也可以在程序中使用 runtime.GOMAXPROCS来改变最大的活跃线程数。
在默认情况下,一个四核机器会创建四个活跃的操作系统线程,每一个线程都对应一个运行时中的 runtime.m 结构体。
在大多数情况下,我们都会使用 Go 的默认设置,也就是线程数等于 CPU 数,默认的设置不会频繁触发操作系统的线程调度和上下文切换,所有的调度都会发生在用户态,由 Go 语言调度器触发,能够减少很多额外开销。
其中 g0 是持有调度栈的 Goroutine,curg 是在当前线程上运行的用户 Goroutine,这也是操作系统线程唯一关心的两个 Goroutine。
g0 是一个运行时中比较特殊的 Goroutine,它会深度参与运行时的调度过程,包括 Goroutine 的创建、大内存分配和 CGO 函数的执行。在后面的小节中,我们会经常看到 g0 的身影。
// /usr/local/go/src/runtime/runtime2.go
type m struct {
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
// Fields not known to debuggers.
procid uint64 // for debuggers, but offset not hard-coded
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
sigmask sigset // storage for saved signal mask
tls [6]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
id int64
mallocing int32
throwing int32
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
profilehz int32
spinning bool // m is out of work and is actively looking for work
blocked bool // m is blocked on a note
newSigstack bool // minit on C thread called sigaltstack
printlock int8
incgo bool // m is executing a cgo call
freeWait uint32 // if == 0, safe to free g0 and delete m (atomic)
fastrand [2]uint32
needextram bool
traceback uint8
ncgocall uint64 // number of cgo calls in total
ncgo int32 // number of cgo calls currently in progress
cgoCallersUse uint32 // if non-zero, cgoCallers in use temporarily
cgoCallers *cgoCallers // cgo traceback if crashing in cgo call
park note
alllink *m // on allm
schedlink muintptr
mcache *mcache
lockedg guintptr
createstack [32]uintptr // stack that created this thread.
lockedExt uint32 // tracking for external LockOSThread
lockedInt uint32 // tracking for internal lockOSThread
nextwaitm muintptr // next m waiting for lock
waitunlockf func(*g, unsafe.Pointer) bool
waitlock unsafe.Pointer
waittraceev byte
waittraceskip int
startingtrace bool
syscalltick uint32
freelink *m // on sched.freem
// these are here because they are too large to be on the stack
// of low-level NOSPLIT functions.
libcall libcall
libcallpc uintptr // for cpu profiler
libcallsp uintptr
libcallg guintptr
syscall libcall // stores syscall parameters on windows
vdsoSP uintptr // SP for traceback while in VDSO call (0 if not in call)
vdsoPC uintptr // PC for traceback while in VDSO call
// preemptGen counts the number of completed preemption
// signals. This is used to detect when a preemption is
// requested, but fails. Accessed atomically.
preemptGen uint32
// Whether this is a pending preemption signal on this M.
// Accessed atomically.
signalPending uint32
dlogPerM
mOS
}
P
调度器中的处理器 P 是线程和 Goroutine 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率。
因为调度器在启动时就会创建 GOMAXPROCS 个处理器,所以 Go 语言程序的处理器数量一定会等于 GOMAXPROCS,这些处理器会绑定到不同的内核线程上。
runtime.p 是处理器的运行时表示,作为调度器的内部实现,它包含的字段也非常多,其中包括与性能追踪、垃圾回收和计时器相关的字段,
// /usr/local/go/src/runtime/runtime2.go
type p struct {
id int32
status uint32 // one of pidle/prunning/...
link puintptr
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
pcache pageCache
raceprocctx uintptr
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
sudogcache []*sudog
sudogbuf [128]*sudog
// Cache of mspan objects from the heap.
mspancache struct {
// We need an explicit length here because this field is used
// in allocation codepaths where write barriers are not allowed,
// and eliminating the write barrier/keeping it eliminated from
// slice updates is tricky, moreso than just managing the length
// ourselves.
len int
buf [128]*mspan
}
tracebuf traceBufPtr
// traceSweep indicates the sweep events should be traced.
// This is used to defer the sweep start event until a span
// has actually been swept.
traceSweep bool
// traceSwept and traceReclaimed track the number of bytes
// swept and reclaimed by sweeping in the current sweep loop.
traceSwept, traceReclaimed uintptr
palloc persistentAlloc // per-P to avoid mutex
_ uint32 // Alignment for atomic fields below
// The when field of the first entry on the timer heap.
// This is updated using atomic functions.
// This is 0 if the timer heap is empty.
timer0When uint64
// Per-P GC state
gcAssistTime int64 // Nanoseconds in assistAlloc
gcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic)
gcBgMarkWorker guintptr // (atomic)
gcMarkWorkerMode gcMarkWorkerMode
// gcMarkWorkerStartTime is the nanotime() at which this mark
// worker started.
gcMarkWorkerStartTime int64
// gcw is this P's GC work buffer cache. The work buffer is
// filled by write barriers, drained by mutator assists, and
// disposed on certain GC state transitions.
gcw gcWork
// wbBuf is this P's GC write barrier buffer.
//
// TODO: Consider caching this in the running G.
wbBuf wbBuf
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
// Lock for timers. We normally access the timers while running
// on this P, but the scheduler can also do it from a different P.
timersLock mutex
// Actions to take at some time. This is used to implement the
// standard library's time package.
// Must hold timersLock to access.
timers []*timer
// Number of timers in P's heap.
// Modified using atomic instructions.
numTimers uint32
// Number of timerModifiedEarlier timers on P's heap.
// This should only be modified while holding timersLock,
// or while the timer status is in a transient state
// such as timerModifying.
adjustTimers uint32
// Number of timerDeleted timers in P's heap.
// Modified using atomic instructions.
deletedTimers uint32
// Race context used while executing timer functions.
timerRaceCtx uintptr
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
pad cpu.CacheLinePad
}
Discussion
调度器的实现 - schedule()与findrunnable()函数
Goroutine调度是在P中进行,每当runtime需要进行调度时,会调用schedule()函数, 该函数在proc1.go文件中定义。
schedule()函数首先调用runqget()从当前P的队列中取一个可以执行的G。 如果队列为空,继续调用findrunnable()函数。findrunnable()函数会按照以下顺序来取得G:
- 调用runqget()从当前P的队列中取G(和schedule()中的调用相同);
- 调用globrunqget()从全局队列中取可执行的G;
- 调用netpoll()取异步调用结束的G,该次调用为非阻塞调用,直接返回;
- 调用runqsteal()从其他P的队列中“偷”。
如果以上四步都没能获取成功,就继续执行一些低优先级的工作:
- 如果处于垃圾回收标记阶段,就进行垃圾回收的标记工作;
- 再次调用globrunqget()从全局队列中取可执行的G;
- 再次调用netpoll()取异步调用结束的G,该次调用为阻塞调用。
如果还没有获得G,就停止当前M的执行,返回findrunnable()函数开头重新执行。 如果findrunnable()正常返回一个G,shedule()函数会调用execute()函数执行该G。 execute()函数会调用gogo()函数(在汇编源文件asm_XXX.s中定义,XXX代表系统架构),gogo() 函数会从G.sched结构中恢复出G上次被调度器暂停时的寄存器现场(SP、PC等),然后继续执行。
如何进行抢占?
有了这种机制,Go运行时便有了具有所有必需功能的Scheduler。
- 它可以处理并行执行(多线程)。
- 处理阻塞系统调用和网络I/O。
- 处理用户级别(在channel上)的阻塞调用。
- 可扩展
- 高效
- 公平
这提供了大量的并发性,并且始终尝试实现最大的利用率和最小的延迟。
抢占式调度(preemptive scheduling)
和操作系统按时间片调度线程不同,Go并没有时间片的概念。如果某个G没有进行system call、没有阻塞在一个channel操作上,那么M如何让G停下来并调度下一个runnable G的呢?答案是:G是被抢占调度的。
Go程序启动时,runtime会去启动一个名为sysmon的M(一般称为监控线程),该M无需绑定P即可运行,该M在整个Go程序的运行过程中至关重要:
sysmon每20us~10ms启动一次,sysmon主要完成如下工作:
- 释放闲置超过5分钟的span物理内存;
- 如果超过2分钟没有垃圾回收,强制执行;
- 将长时间未处理的netpoll结果添加到任务队列;
- 向长时间运行的G发出抢占调度;
- 收回因syscall长时间阻塞的P;
任何运行时间超过10ms的goroutine都被标记为可被抢占(软限制)。但是,抢占仅在函数执行开始处才能完成。Go当前在函数开始处中使用了由编译器插入的协作抢占点。
我们看到sysmon将“向长时间运行的G任务发出抢占调度”,这个事情由retake实施:
// /usr/local/go/src/runtime/proc.go
// forcePreemptNS is the time slice given to a G before it is
// preempted.
const forcePreemptNS = 10 * 1000 * 1000 // 10ms
func retake(now int64) uint32 {
n := 0
// Prevent allp slice changes. This lock will be completely
// uncontended unless we're already stopping the world.
lock(&allpLock)
// We can't use a range loop over allp because we may
// temporarily drop the allpLock. Hence, we need to re-fetch
// allp each time around the loop.
for i := 0; i < len(allp); i++ {
...
可以看出,如果一个G任务运行10ms,sysmon就会认为其运行时间太久而发出抢占式调度的请求。一旦G的可被抢占标志位被设为true,那么待这个G下一次调用函数或方法时,runtime便可以将G抢占,并移出运行状态,放入P的local run queue中,等待下一次被调度。
阻塞的 system call 情况下的调度
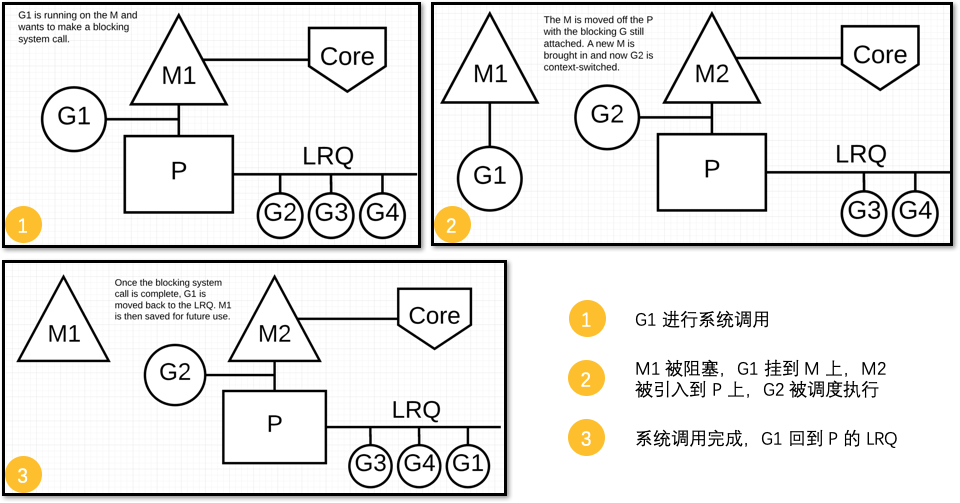
如果G被阻塞在某个system call操作上,那么不光G会被阻塞,执行该G的M和P也会被阻塞,这时执行该G的P会解绑这个M(实质是被sysmon抢走了),让这个M与这个G一起进入sleep状态,这时候这个M会进入M waiting queue中。
如果此时有idle的M,则P与该M进行绑定,并继续执行该 P 中的G;如果没有idle M,但这个 P 中仍然有其他G要被执行,那么就会创建一个新M(OS thread)。
当阻塞在syscall上的G完成syscall调用后,G会会被标记为runnable
- Go runtime 会尝试获取之前绑定的那个P(通过加入到这个P的LRQ中),然后继续执行。
- 如果不成功,Go runtime 尝试在P空闲列表中获取一个P并恢复执行。
- 如果还不成功,Go runtime 将这个G放在全局队列中,并将关联的M放到M空闲列表。
Go optimizes the system calls — whatever it is blocking or not — by wrapping them up in the runtime.

Blocking System Call wrapper.
The Blocking SYSCALL method is encapsulated between
runtime.entersyscall(SB)runtime.exitsyscall(SB)
**In a literal sense, some logic is executed before entering the system call, and some logic is executed after exiting the system call. This wrapper will automatically dissociate the P from the thread M when a blocking system call is made and allow another thread to run on it.

Blocking Syscall Handoffs P.
This allows Go runtime to handle the blocking system call efficiently without increasing the run queue.
非阻塞的 system call 情况下的调度
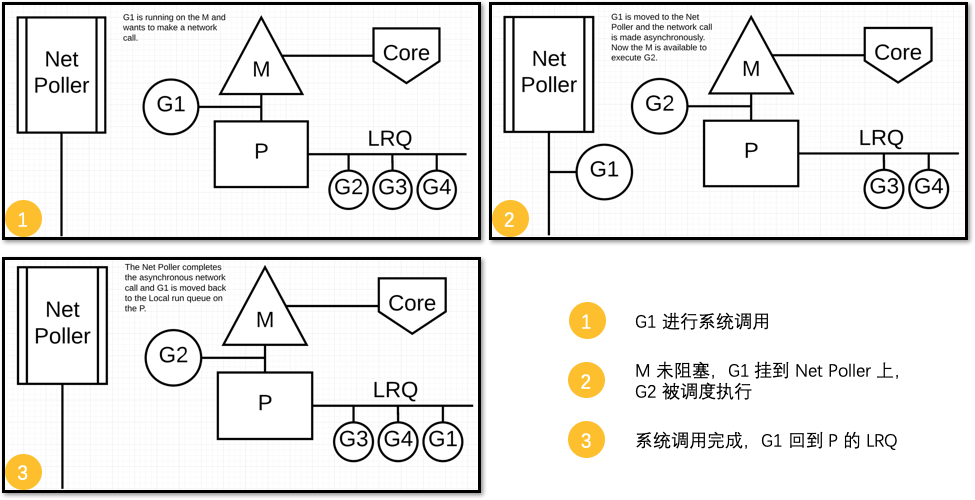
例如,在非阻塞I/O(例如TCP)的情况下。由于资源尚未准备就绪,第一个syscall(比如read)将不会成功,并直接返回(因为Golang runtime会将其设置为non-blocking),这将迫使Go使用代理人(network poller)接手,并将该G置为sleep状态。
这时,该G对应的P对应的M将不会被阻塞,因而可以继续去执行当前M关联的P中的 LRQ 里的其他 G。
Once the first syscall is done and explicitly says the resource is not yet ready, the goroutine will be park-ed and will become runnable until the network poller notifies it that the resource is now ready.
Poller will use select / kqueue / epoll / IOCP based on the operating system to know which file descriptor is ready and will put the goroutine back on the run queue as soon as the file descriptor is ready for reading or writing.
The ability to turn Blocking I/O work into CPU-bound work at the OS level is where we get a big win in leveraging more CPU capacity over time.
In Go, it’s possible to get more work done, over time, because the Go scheduler attempts to use less Threads and do more on each Thread, which helps to reduce load on the OS and the hardware.
network poller将基于操作系统使用select/kqueue/epoll/IOCP等机制来接收通知以知道哪个文件描述符已准备好,一旦文件描述符准备好进行读取或写入,它将把该G放回到之前的P的 LRQ 中。
netpoller
Go runtime已经实现了netpoller,这使得即便G发起网络I/O操作也不会导致M被阻塞(仅阻塞G,更准确的说,是park 了 G),从而不会导致大量M(OS thread)被创建出来。Otherwise it becomes really expensive once you have 10,000 client threads, all stuck in a syscall waiting for their I/O operation to succeed.
The part that converts asynchronous I/O into blocking I/O is called the netpoller. It sits in its own thread, receiving events from goroutines wishing to do network I/O. The netpoller uses whichever interface the OS provides to do polling of network sockets. On Linux, it uses epoll, on the BSDs and Darwin, it uses kqueue and on Windows it uses IoCompletionPort. These interfaces all have in common that they provide user space a way to efficiently poll for the status of network I/O.
Whenever you open or accept a connection in Go, the file descriptor that backs it is set to non-blocking mode. This means that if you try to do I/O on it and the file descriptor isn’t ready, it will return an error code saying so. Whenever a goroutine tries to read or write to a connection, the networking code will do the operation until it receives such an error, then call into the netpoller, telling it to notify the goroutine when it is ready to perform I/O again. The goroutine is then scheduled out of the thread it’s running on and another goroutine is run in its place.
When the netpoller receives notification from the OS that it can perform I/O on a file descriptor, it will look through its internal data structure, see if there are any goroutines that are blocked on that file and notify them if there are any. The goroutine can then retry the I/O operation that caused it to block and succeed in doing so.
但是对于regular file的I/O操作一旦阻塞,那么M将进入sleep状态,等待I/O返回后被唤醒;这种情况下P将与sleep的M分离,再选择一个idle的M。如果此时没有idle的M,则会新创建一个M,这就是为何大量I/O操作导致大量Thread被创建的原因。
Ian Lance Taylor在Go 1.9 dev周期中增加了一个Poller for os package的功能,这个功能可以像netpoller那样,在G操作支持pollable的fd时,仅阻塞G,而不阻塞M。不过该功能依然不能对regular file有效,regular file不是pollable的。不过,对于scheduler而言,这也算是一个进步了。
Work Stealing
Go scheduler 的职责就是将所有处于 runnable 的 goroutines 均匀分布到在 P 上运行的 M。
当一个 P 发现自己的 LRQ 已经没有 G 时,会 “偷” 一些 G 来运行。看看这是什么精神!自己的工作做完了,为了全局的利益,主动为别人分担。这被称为 Work-stealing,Go 从 1.1 开始实现(https://docs.google.com/document/d/1TTj4T2JO42uD5ID9e89oa0sLKhJYD0Y_kqxDv3I3XMw/edit#heading=h.mmq8lm48qfcw)。
具体来说
- 先从全局队列中“偷”
- 如果全局队列是空的,就从其他的P的local queue 中“偷”
- 如果其他的P的local queue也都为空,从网络轮询器(netpuller)的queue中“偷”
Go scheduler 使用 M:N 模型,在任一时刻,M 个 goroutines(G) 要分配到 N 个内核线程(M),这些 M 跑在个数最多为 GOMAXPROCS 的逻辑处理器(P)上。每个 M 必须依附于一个 P,每个 P 在同一时刻只能运行一个 M。如果 P 上的 M 阻塞了,那这个 P 就需要其他的 M 来运行这个 P 的 LRQ 里的 goroutines。
实际上,Go scheduler 每一轮调度要做的工作就是找到处于 runnable 的 goroutines,并执行它。找的顺序如下:
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
找到一个可执行的 goroutine 后,就会一直执行下去,直到被阻塞。
当 P2 上的一个 G 执行结束,它就会去 LRQ 获取下一个 G 来执行。如果 LRQ 已经空了,就是说本地可运行队列已经没有 G 需要执行,并且这时 GRQ 也没有 G 了。这时,P2 会随机选择一个 P(称为 P1),P2 会从 P1 的 LRQ “偷”过来一半的 G。
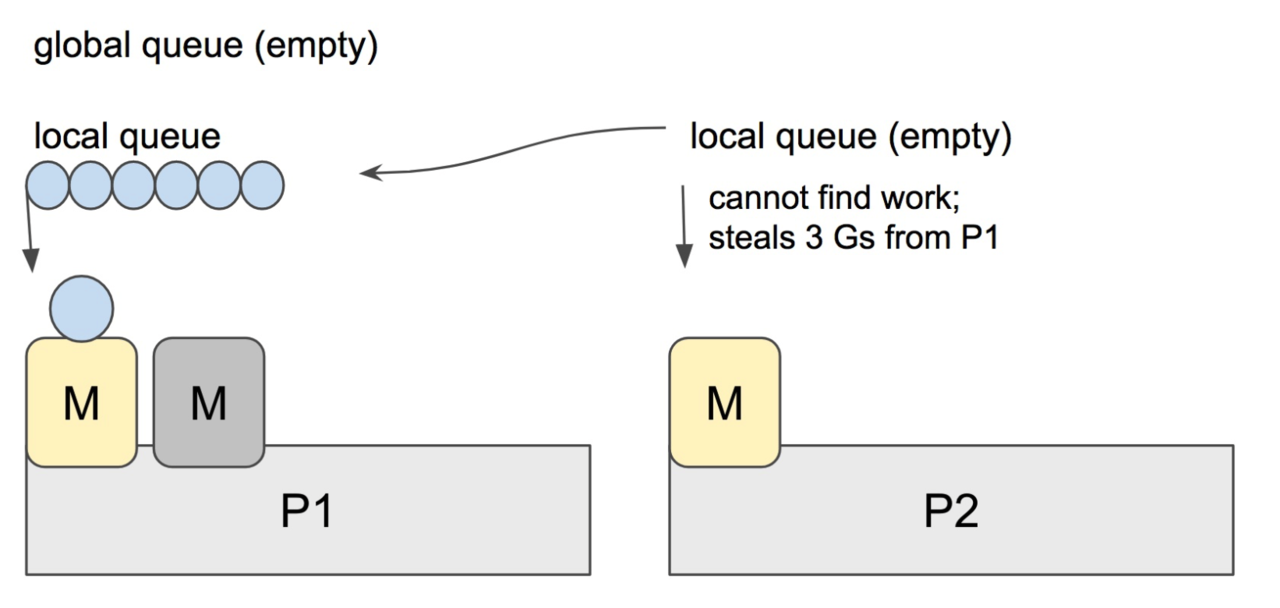
这样做的好处是,有更多的 P 可以一起工作,加速执行完所有的 G。
Debug
调度器状态的查看方法
Go提供了调度器当前状态的查看方法:使用Go运行时环境变量GODEBUG。
$ GODEBUG=schedtrace=1000 ./program
SCHED 0ms: gomaxprocs=4 idleprocs=3 threads=3 spinningthreads=0 idlethreads=0 runqueue=0 [0 0 0 0]
SCHED 1001ms: gomaxprocs=4 idleprocs=0 threads=9 spinningthreads=0 idlethreads=3 runqueue=2 [8 14 5 2]
SCHED 2006ms: gomaxprocs=4 idleprocs=0 threads=25 spinningthreads=0 idlethreads=19 runqueue=12 [0 0 4 0]
SCHED 3006ms: gomaxprocs=4 idleprocs=0 threads=26 spinningthreads=0 idlethreads=8 runqueue=2 [0 1 1 0]
... ...
GODEBUG这个Go运行时环境变量很是强大,通过给其传入不同的key1=value1,key2=value2… 组合,Go的runtime会输出不同的调试信息,比如在这里我们给GODEBUG传入了”schedtrace=1000″,其含义就是每1000ms,打印输出一次goroutine scheduler的状态,每次一行。每一行各字段含义如下:
以上面例子中最后一行为例:
SCHED 6016ms: gomaxprocs=4 idleprocs=0 threads=26 spinningthreads=0 idlethreads=20 runqueue=1 [3 4 0 10]
SCHED:调试信息输出标志字符串,代表本行是goroutine scheduler的输出;
6016ms:即从程序启动到输出这行日志的时间;
gomaxprocs: P的数量;
idleprocs: 处于idle状态的P的数量;通过gomaxprocs和idleprocs的差值,我们就可知道执行go代码的P的数量;
threads: os threads的数量,包含scheduler使用的m数量,加上runtime自用的类似sysmon这样的thread的数量;
spinningthreads: 处于自旋状态的os thread数量;
idlethread: 处于idle状态的os thread的数量;
runqueue=1: go scheduler全局队列中G的数量;
[3 4 0 10]: 分别为4个P的local queue中的G的数量。
我们还可以输出每个goroutine、m和p的详细调度信息,但对于Go user来说,绝大多数时间这是不必要的:
$ GODEBUG=schedtrace=1000,scheddetail=1 ./program
SCHED 0ms: gomaxprocs=4 idleprocs=3 threads=3 spinningthreads=0 idlethreads=0 runqueue=0 gcwaiting=0 nmidlelocked=0 stopwait=0 sysmonwait=0
P0: status=1 schedtick=0 syscalltick=0 m=0 runqsize=0 gfreecnt=0
P1: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0
P2: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0
P3: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0
M2: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=1 dying=0 helpgc=0 spinning=false blocked=false lockedg=-1
M1: p=-1 curg=17 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 helpgc=0 spinning=false blocked=false lockedg=17
M0: p=0 curg=1 mallocing=0 throwing=0 preemptoff= locks=1 dying=0 helpgc=0 spinning=false blocked=false lockedg=1
G1: status=8() m=0 lockedm=0
G17: status=3() m=1 lockedm=1
SCHED 1002ms: gomaxprocs=4 idleprocs=0 threads=13 spinningthreads=0 idlethreads=7 runqueue=6 gcwaiting=0 nmidlelocked=0 stopwait=0 sysmonwait=0
P0: status=2 schedtick=2293 syscalltick=18928 m=-1 runqsize=12 gfreecnt=2
P1: status=1 schedtick=2356 syscalltick=19060 m=11 runqsize=11 gfreecnt=0
P2: status=2 schedtick=2482 syscalltick=18316 m=-1 runqsize=37 gfreecnt=1
P3: status=2 schedtick=2816 syscalltick=18907 m=-1 runqsize=2 gfreecnt=4
M12: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 helpgc=0 spinning=false blocked=true lockedg=-1
M11: p=1 curg=6160 mallocing=0 throwing=0 preemptoff= locks=2 dying=0 helpgc=0 spinning=false blocked=false lockedg=-1
M10: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 helpgc=0 spinning=false blocked=true lockedg=-1
... ...
SCHED 2002ms: gomaxprocs=4 idleprocs=0 threads=23 spinningthreads=0 idlethreads=5 runqueue=4 gcwaiting=0 nmidlelocked=0 stopwait=0 sysmonwait=0
P0: status=0 schedtick=2972 syscalltick=29458 m=-1 runqsize=0 gfreecnt=6
P1: status=2 schedtick=2964 syscalltick=33464 m=-1 runqsize=0 gfreecnt=39
P2: status=1 schedtick=3415 syscalltick=33283 m=18 runqsize=0 gfreecnt=12
P3: status=2 schedtick=3736 syscalltick=33701 m=-1 runqsize=1 gfreecnt=6
M22: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 helpgc=0 spinning=false blocked=true lockedg=-1
M21: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=0 dying=0 helpgc=0 spinning=false blocked=true lockedg=-1
... ...
关于go scheduler调试信息输出的详细信息,可以参考Dmitry Vyukov的大作:《Debugging performance issues in Go programs》。这也应该是每个gopher必读的经典文章。当然更详尽的代码可参考$GOROOT/src/runtime/proc.go中的schedtrace函数。
Reference
- https://docs.google.com/document/d/1TTj4T2JO42uD5ID9e89oa0sLKhJYD0Y_kqxDv3I3XMw/edit#
- https://github.com/golang/proposal/blob/master/design/24543-non-cooperative-preemption.md
- https://rakyll.org/scheduler/
- https://golang.org/ref/mem
- https://github.com/golang/go/blob/master/src/runtime/proc.go
- https://povilasv.me/go-scheduler/
- https://www.ardanlabs.com/blog/2015/02/scheduler-tracing-in-go.html
- https://speakerdeck.com/retervision/go-runtime-scheduler?slide=32
- https://morsmachine.dk/go-scheduler
- http://www.cs.columbia.edu/~aho/cs6998/reports/12-12-11_DeshpandeSponslerWeiss_GO.pdf
- https://medium.com/@ankur_anand/illustrated-tales-of-go-runtime-scheduler-74809ef6d19b
- https://morsmachine.dk/netpoller
- https://www.youtube.com/watch?v=YHRO5WQGh0k
- https://www.youtube.com/watch?v=Yx6FBsGNOp4
CN
- https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-goroutine/
- https://tonybai.com/2017/06/23/an-intro-about-goroutine-scheduler/
- https://studygolang.com/articles/23272
- https://colobu.com/2017/05/04/go-scheduler/
- https://tonybai.com/2020/03/21/illustrated-tales-of-go-runtime-scheduler/
- https://learnku.com/articles/41728