背景
在介绍自旋锁前,我们需要介绍一些前提知识来帮助大家明白自旋锁的概念。
阻塞或唤醒一个Java线程需要操作系统进行 context swtich(e.g., kernel space <-> user space, interrupt handling due to I/O or waiting for synchrnization operation to complete)来完成,
Refer to https://swsmile.info/post/os-context-swtich/ in details.
这种 context 转换需要耗费处理器时间。如果同步代码块中的内容过于简单,context 转换消耗的时间有可能比用户代码执行的时间还要长。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃CPU的执行时间,看看持有锁的线程是否很快就会释放锁。
而为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。
自旋锁(Spinlock)
自旋锁也是一种实现互斥(mutual exclusion)的方式,相比经典的互斥锁(Mutex)会在因无法进入临界区而进入阻塞状态(因此互斥锁是一个阻塞锁),因而放弃CPU。
而自旋锁(Spin Lock)是指当一个线程在申请获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断地判断锁是否能够被成功获取,直到获取到锁后,才会退出循环。
在这种情况中,尝试获取锁的线程一直处于 Running 状态,但是并没有执行任何有效的任务,即紧密循环(tight loop),这个过程也称为忙等待(busy waiting)。
- 一个解决忙等待最简单的解决方案就是
sleep and wakeup。 sleep是一个可以使得调用者(caller)阻塞的系统调用,而wakeup包含一个参数,传入要唤醒的那个进程。
其实,自旋锁与互斥锁(Mutexes)比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,“自旋"一词就是因此而得名。
Analysis
自旋锁是一种非阻塞式的锁,其设计的初衷是尽量减少进程的上下文切换。
[Critical Thinking] 与其叫自旋锁,其实叫自旋同步机制(sychrinization)会更准确且容易理解一些。因为狭义的锁的含义,就是阻塞的,而这与“自旋锁”的非阻塞特性是相互矛盾的。
当锁持有的时间短(临界区代码的执行非常快),而且不希望频繁地对进程/线程进行上下文切换时,适合使用自旋锁(而不是互斥锁)。
Because they avoid overhead from operating system process rescheduling or context switching, spinlocks are efficient if threads are likely to be blocked for only short periods. For this reason, operating-system kernels often use spinlocks. However, spinlocks become wasteful if held for longer durations, as they may prevent other threads from running and require rescheduling. The longer a thread holds a lock, the greater the risk that the thread will be interrupted by the OS scheduler while holding the lock. If this happens, other threads will be left “spinning” (repeatedly trying to acquire the lock), while the thread holding the lock is not making progress towards releasing it. The result is an indefinite postponement until the thread holding the lock can finish and release it. This is especially true on a single-processor system, where each waiting thread of the same priority is likely to waste its quantum (allocated time where a thread can run) spinning until the thread that holds the lock is finally finished.
自旋锁应用场景
互斥同步最大的问题在于阻塞的实现,挂起和恢复线程的操作都分别需要进行内核态(kernel mode)与用户态(user mode)的一次转换,这给操作系统的并发带来了很大压力。
同时,虚拟机开发团队注意到很多应用上,共享数据的锁定状态只会持续很短一段时间,为了这段时间去挂起和恢复线程不值得。
所以我们可以让线程稍微等一下,而不放弃处理器的执行时间,看看持有锁的线程是否很快就释放了锁。这样的实现就是让线程执行一个循环(自旋),这就是自旋锁了。
在 JDK 1.6 中自旋锁就已经改为默认开启了。自旋等待不能代替阻塞,且不说对处理器数量的要求,自旋本身虽然避免了线程切换的开销,但是其需要占用处理器的时间,所以如果锁被占用的时间很短,自旋等待的效果就会非常好。反之如果锁被占用的时间很长,那么自旋的线程只会白白消耗处理器资源,而不会做任何有用的工作,反而会带来性能的浪费。
因此自旋等待的时间必须要有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程了。在Java 中,自旋次数的默认值是 10 次,用户可以使用参数 -XX:PreBlockSpin 来更改。
适应性自旋锁(Adaptive Spinning Lock)
在 Java 的 JDK 1.6 中引入了**自适应(adaptive)**的自旋锁。
**自适应自旋锁(Adaptive Spinning Lock)**意味着自旋的时间不再固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能再次成功,进而它将允许自旋等待持续相对更长的时间,比如100个循环。另一方面,如果对于某个锁,自旋很少成功获得过,那在以后要获取这个锁时将可能省略掉自旋过程,以避免浪费处理器资源。
有了自适应自旋,随着程序运行和程序中记录的统计信息的不断完善,虚拟机对程序锁的状况预测就会越来越准确,虚拟机就会变得越来越“聪明”了。
自旋锁存在的问题
- 如果某个线程持有锁的时间过长,就会导致其它等待获取锁的线程进入循环等待,消耗 CPU 。使用不当会造成 CPU 使用率极高。
- 上面 Java 实现的自旋锁不是公平的,即无法满足等待时间最长的线程优先获取锁。不公平的锁就会存在“线程饥饿”问题。
自旋锁的优点
- 自旋锁不会使线程状态发生切换,一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快
- 非自旋锁在获取不到锁的时候会进入阻塞状态,从而进入内核态,当获取到锁的时候需要从内核态恢复,需要线程上下文切换。 (线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能)
自旋锁与互斥锁对比
如果是多核处理器,如果预计进程需要等待锁的时间很短,短到比进程进行两次上下文切换的时间还要少时,使用自旋锁相对更优。
如果是多核处理器,如果预计进程需要等待锁的时间较长,至少比进程进行两次上下文切换的时间还长,使用互斥锁则更优。
如果是单核处理器,使用自旋锁会造成额外的无用 CPU 消耗。因为,如果运行的进程发现无法获取锁,则只能不断”自旋“以获取锁的状态,直到分配给它的 CPU 时间片被用完。 而事实上,由于在同一时间只有一个进程处于运行状态,因此已经持有锁的进程,在自旋进程处于自旋的过程中,根本没有机会运行,因而锁的状态并不会发生改变。这意味着自旋进程的自旋过程只是在做无用功。而事实上,操作系统会判断当前环境是否为单核处理器,若是,则禁止进程的自旋。
Implementation
Implementing spin locks correctly is challenging because programmers must take into account the possibility of simultaneous access to the lock, which could cause race conditions. Generally, such an implementation is possible only with special assembly-language instructions, such as atomic test-and-set operations and cannot be easily implemented in programming languages not supporting truly atomic operations.
Java Level
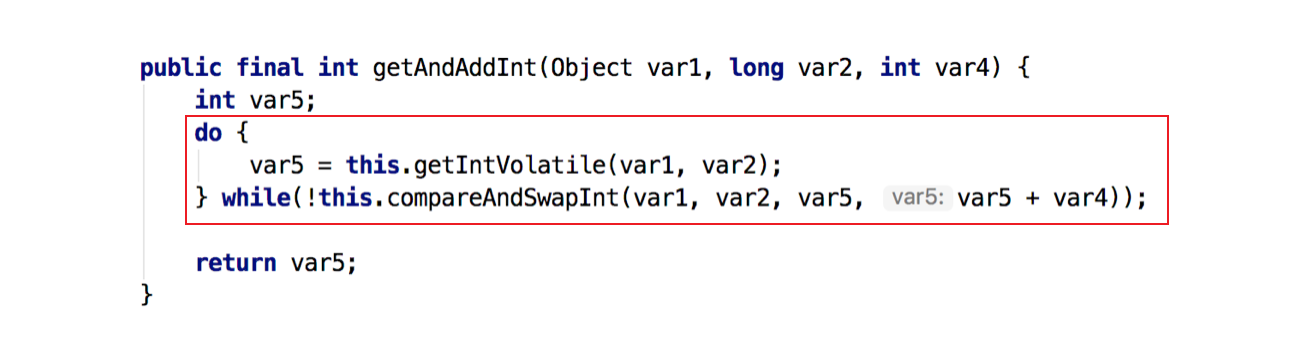
自旋锁基于CAS实现,AtomicInteger 中调用unsafe进行自增操作的源码中的do-while循环就是一个自旋操作,如果修改数值失败则通过循环来执行自旋,直至修改成功。
Example
下面是个简单的例子:
public class SpinLock {
private AtomicReference<Thread> cas = new AtomicReference<Thread>();
public void lock() {
Thread current = Thread.currentThread();
// 利用CAS
while (!cas.compareAndSet(null, current)) {
// DO nothing
}
}
public void unlock() {
Thread current = Thread.currentThread();
cas.compareAndSet(current, null);
}
}
lock() 方法利用的CAS,当第一个线程 A 获取锁的时候,能够成功获取到,不会进入 while 循环,如果此时线程 A 没有释放锁,另一个线程 B 又来获取锁,此时由于不满足 CAS,所以就会进入 while 循环,不断判断是否满足 CAS ,直到 A 线程调用 unlock() 方法释放了该锁。
Refer to https://swsmile.info/post/jave-cas-lock-free-algorhithm/ for details.
High-level
On architectures without such operations, or if high-level language implementation is required, a non-atomic locking algorithm may be used, e.g. Peterson’s algorithm. However, such an implementation may require more memory than a spinlock, be slower to allow progress after unlocking, and may not be implementable in a high-level language if out-of-order execution is allowed.
Assembly-language Instructions based Implementation
Simple Implementation
The following example uses x86 assembly language to implement a spinlock. It will work on any Intel 80386 compatible processor.
; Intel syntax
locked: ; The lock variable. 1 = locked, 0 = unlocked.
dd 0
spin_lock:
mov eax, 1 ; Set the EAX register to 1.
xchg eax, [locked] ; Atomically swap the EAX register with
; the lock variable.
; This will always store 1 to the lock, leaving
; the previous value in the EAX register.
test eax, eax ; Test EAX with itself. Among other things, this will
; set the processor's Zero Flag if EAX is 0.
; If EAX is 0, then the lock was unlocked and
; we just locked it.
; Otherwise, EAX is 1 and we didn't acquire the lock.
jnz spin_lock ; Jump back to the MOV instruction if the Zero Flag is
; not set; the lock was previously locked, and so
; we need to spin until it becomes unlocked.
ret ; The lock has been acquired, return to the calling
; function.
spin_unlock:
xor eax, eax ; Set the EAX register to 0.
xchg eax, [locked] ; Atomically swap the EAX register with
; the lock variable.
ret ; The lock has been released.
Improvement
The simple implementation above works on all CPUs using the x86 architecture. However, a number of performance optimizations are possible:
- On later implementations of the x86 architecture, spin_unlock can safely use an unlocked MOV instead of the slower locked XCHG. This is due to subtle memory ordering rules which support this, even though MOV is not a full memory barrier.
- To reduce inter-CPU bus traffic, code trying to acquire a lock should loop reading without trying to write anything until it reads a changed value.
- Because of MESI caching protocols, this causes the cache line for the lock to become “Shared”; then there is remarkably no bus traffic while a CPU waits for the lock. This optimization is effective on all CPU architectures that have a cache per CPU, because MESI is so widespread. On Hyper-Threading CPUs, pausing with
rep nopgives additional performance by hinting the core that it can work on the other thread while the lock spins waiting
- Because of MESI caching protocols, this causes the cache line for the lock to become “Shared”; then there is remarkably no bus traffic while a CPU waits for the lock. This optimization is effective on all CPU architectures that have a cache per CPU, because MESI is so widespread. On Hyper-Threading CPUs, pausing with
Alternatives
The primary disadvantage of a spinlock is that, while waiting to acquire a lock, it wastes time that might be productively spent elsewhere. There are two ways to avoid this:
- Do not acquire the lock. In many situations it is possible to design data structures that do not require locking, e.g. by using per-thread or per-CPU data and disabling interrupts.
- Switch to a different thread while waiting. This typically involves attaching the current thread to a queue of threads waiting for the lock, followed by switching to another thread that is ready to do some useful work. This scheme also has the advantage that it guarantees that resource starvation does not occur as long as all threads eventually relinquish locks they acquire and scheduling decisions can be made about which thread should progress first. Spinlocks that never entail switching, usable by real-time operating systems, are sometimes called raw spinlocks.[4]
Most operating systems (including Solaris, Mac OS X and FreeBSD) use a hybrid approach called “adaptive mutex”. The idea is to use a spinlock when trying to access a resource locked by a currently-running thread, but to sleep if the thread is not currently running. (The latter is always the case on single-processor systems.)
Reference
- https://en.wikipedia.org/wiki/Lock_(computer_science)
- https://en.wikipedia.org/wiki/Spinlock
- https://docs.oracle.com/cd/E26502_01/html/E35303/ggecq.html
- https://stackoverflow.com/questions/1957398/what-exactly-are-spin-locks