热点数据
热点数据 比较好理解,那就是用户的热点请求对应的数据。而热点数据又分为“静态热点数据”和“动态热点数据”。
- 静态热点数据
- 所谓“静态热点数据”,就是能够提前预测的热点数据。例如,我们可以通过卖家报名的方式提前筛选出来,通过报名系统对这些热点商品进行打标。另外,我们还可以通过大数据分析来提前发现热点商品,比如我们分析历史成交记录、用户的购物车记录,来发现哪些商品可能更热门、更好卖,这些都是可以提前分析出来的热点。
- 动态热点数据
- 所谓“动态热点数据”,就是不能被提前预测到的,系统在运行过程中临时产生的热点。例如,卖家在抖音上做了广告,然后商品一下就火了,导致它在短时间内被大量购买。
发现热点数据
一个关键的问题来了:如何发现这些秒杀商品,或者更准确地说,如何发现热点商品呢?你可能会说“参加秒杀的商品就是秒杀商品啊”,没错,关键是系统怎么知道哪些商品参加了秒杀活动呢?所以,你要有一个机制提前来区分普通商品和秒杀商品。我们从发现静态热点和发现动态热点两个方面来看一下。
发现静态热点数据
如前面讲的,静态热点数据可以通过商业手段,例如强制让卖家通过报名参加的方式提前把热点商品筛选出来,实现方式是通过一个运营系统,把参加活动的商品数据进行打标,然后通过一个后台系统对这些热点商品进行预处理,如提前进行缓存。但是这种通过报名提前筛选的方式也会带来新的问题,即增加卖家的使用成本,而且实时性较差,也不太灵活。
不过,除了提前报名筛选这种方式,你还可以通过技术手段提前预测,例如对买家每天访问的商品进行大数据计算,然后统计出 TOP N 的商品,我们可以认为这些 TOP N 的商品就是热点商品。
发现动态热点数据
我们可以通过卖家报名或者大数据预测这些手段来提前预测静态热点数据,但这其中有一个痛点,就是实时性较差,如果我们的系统能在秒级内自动发现热点商品那就完美了。能够动态地实时发现热点不仅对秒杀商品,对其他热卖商品也同样有价值,所以我们需要想办法实现热点的动态发现功能。
能够动态地实时发现热点不仅对秒杀商品,对其他热卖商品也同样有价值,所以我们需要想办法实现热点的动态发现功能。
这里我给出一个动态热点发现系统的具体实现。
- 构建一个异步的系统,它可以收集交易链路上各个环节中的中间件产品的热点 Key,如 Nginx、缓存、RPC 服务框架等这些中间件(一些中间件产品本身已经有热点统计模块)。
- 建立一个热点上报和可以按照需求订阅的热点服务的下发规范,主要目的是通过交易链路上各个系统(包括详情、购物车、交易、优惠、库存、物流等)访问的时间差,把上游已经发现的热点透传给下游系统,提前做好保护。比如,对于大促高峰期,详情系统是最早知道的,在统一接入层上 Nginx 模块统计的热点 URL。
- 将上游系统收集的热点数据发送到热点服务台,然后下游系统(如交易系统)就会知道哪些商品会被频繁调用,然后做热点保护。
其中用户访问商品时经过的路径有很多,我们主要是依赖前面的导购页面(包括首页、搜索页面、商品详情、购物车等)提前识别哪些商品的访问量高,通过这些系统中的中间件来收集热点数据,并记录到日志中。
处理热点数据处理
热点数据通常有几种思路:一是优化,二是限制,三是隔离。
先来说说优化。优化热点数据最有效的办法就是缓存热点数据,如果热点数据做了动静分离,那么可以长期缓存静态数据。但是,缓存热点数据更多的是“临时”缓存,即不管是静态数据还是动态数据,都用一个队列短暂地缓存数秒钟,由于队列长度有限,可以采用 LRU 淘汰算法替换。
再来说说限制。限制更多的是一种保护机制,限制的办法也有很多,例如对被访问商品的 ID 做一致性 Hash,然后根据 Hash 做分桶,每个分桶设置一个处理队列,这样可以把热点商品限制在一个请求队列里,防止因某些热点商品占用太多的服务器资源,而使其他请求始终得不到服务器的处理资源。
最后介绍一下隔离。秒杀系统设计的第一个原则就是将这种热点数据隔离出来,不要让 1% 的请求影响到另外的 99%,隔离出来后也更方便对这 1% 的请求做针对性的优化。
具体到“秒杀”业务,我们可以在以下几个层次实现隔离。
- 业务隔离。把秒杀做成一种营销活动,卖家要参加秒杀这种营销活动需要单独报名,从技术上来说,卖家报名后对我们来说就有了已知热点,因此可以提前做好预热。
- 系统隔离。系统隔离更多的是运行时的隔离,可以通过分组部署的方式和另外 99% 分开。秒杀可以申请单独的域名,目的也是让请求落到不同的集群中。
- 数据隔离。秒杀所调用的数据大部分都是热点数据,比如会启用单独的 Cache 集群或者 MySQL 数据库来放热点数据,目的也是不想 0.01% 的数据有机会影响 99.99% 数据。
流量削峰
但是对秒杀这个场景来说,最终能够抢到商品的人数是固定的,也就是说 100 人和 10000 人发起请求的结果都是一样的,并发度越高,无效请求也越多。
但是从业务上来说,秒杀活动是希望更多的人来参与的,也就是开始之前希望有更多的人来刷页面,但是真正开始下单时,秒杀请求并不是越多越好。因此我们可以设计一些规则,让并发的请求更多地延缓,而且我们甚至可以过滤掉一些无效请求。
为什么要削峰
为什么要削峰呢?或者说峰值会带来哪些坏处?
我们知道服务器的处理资源是恒定的,你用或者不用它的处理能力都是一样的,所以出现峰值的话,很容易导致忙到处理不过来,闲的时候却又没有什么要处理。但是由于要保证服务质量,我们的很多处理资源只能按照忙的时候来预估,而这会导致资源的一个浪费。
这就好比因为存在早高峰和晚高峰的问题,所以有了错峰限行的解决方案。削峰的存在,一是可以让服务端处理变得更加平稳,二是可以节省服务器的资源成本。针对秒杀这一场景,削峰从本质上来说就是更多地延缓用户请求的发出,以便减少和过滤掉一些无效请求,它遵从“请求数要尽量少”的原则。
今天,我就来介绍一下流量削峰的一些操作思路:排队、答题、分层过滤。这几种方式都是无损(即不会损失用户的发出请求)的实现方案,当然还有些有损的实现方案,包括我们后面要介绍的关于稳定性的一些办法,比如限流和机器负载保护等一些强制措施也能达到削峰保护的目的,当然这都是不得已的一些措施,因此就不归类到这里了。
如何削峰
排队
要对流量进行削峰,最容易想到的解决方案就是用消息队列来缓冲瞬时流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,在另一端平滑地将消息推送出去。在这里,消息队列就像“水库”一样, 拦蓄上游的洪水,削减进入下游河道的洪峰流量,从而达到减免洪水灾害的目的。用消息队列来缓冲瞬时流量的方案,如下图所示:
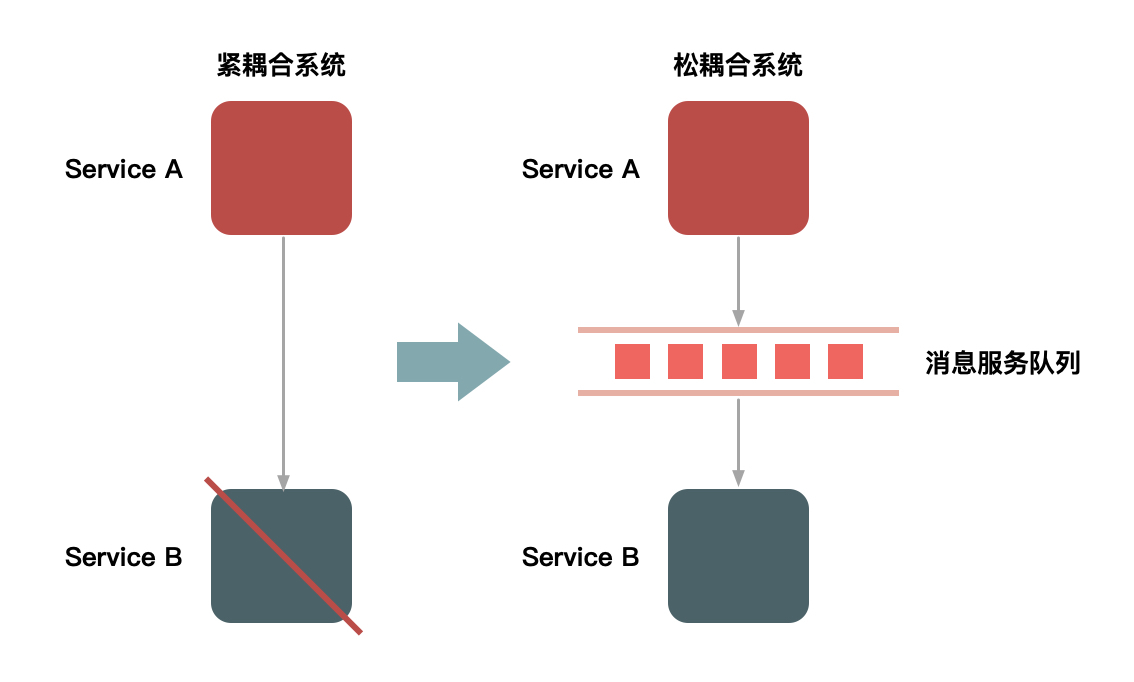
但是,如果流量峰值持续一段时间达到了消息队列的处理上限,例如本机的消息积压达到了存储空间的上限,消息队列同样也会被压垮,这样虽然保护了下游的系统,但是和直接把请求丢弃也没多大的区别。就像遇到洪水爆发时,即使是有水库恐怕也无济于事。
除了消息队列,类似的排队方式还有很多,例如:
- 利用线程池加锁等待也是一种常用的排队方式;
- 先进先出、先进后出等常用的内存排队算法的实现方式;把
- 请求序列化到文件中,然后再顺序地读文件(例如基于 MySQL binlog 的同步机制)来恢复请求等方式。
可以看到,这些方式都有一个共同特征,就是把“一步的操作”变成“两步的操作”,其中增加的一步操作用来起到缓冲的作用。
答题
你是否还记得,最早期的秒杀只是纯粹地刷新页面和点击购买按钮,它是后来才增加了答题功能的。那么,为什么要增加答题功能呢?
这主要是为了增加购买的复杂度,从而达到两个目的。
第一个目的是防止部分买家使用秒杀器在参加秒杀时作弊。2011 年秒杀非常火的时候,秒杀器也比较猖獗,因而没有达到全民参与和营销的目的,所以系统增加了答题来限制秒杀器。增加答题后,下单的时间基本控制在 2s 后,秒杀器的下单比例也大大下降。
第二个目的其实就是延缓请求,起到对请求流量进行削峰的作用,从而让系统能够更好地支持瞬时的流量高峰。这个重要的功能就是把峰值的下单请求拉长,从以前的 1s 之内延长到 2s~10s。这样一来,请求峰值基于时间分片了。这个时间的分片对服务端处理并发非常重要,会大大减轻压力。而且,由于请求具有先后顺序,靠后的请求到来时自然也就没有库存了,因此根本到不了最后的下单步骤,所以真正的并发写就非常有限了。这种设计思路目前用得非常普遍,如当年支付宝的“咻一咻”、微信的“摇一摇”都是类似的方式。
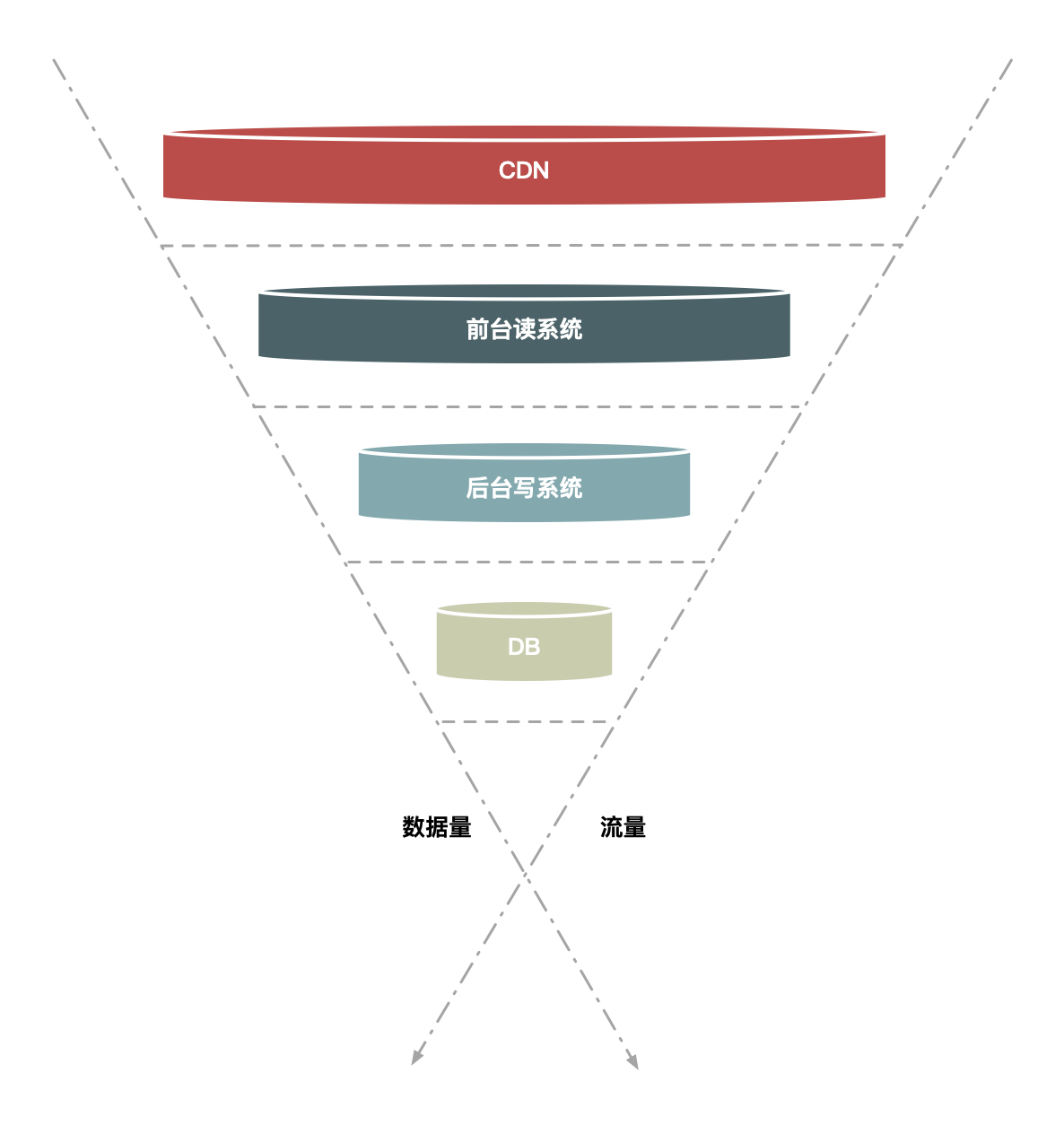
分层过滤
前面介绍的排队和答题要么是少发请求,要么对发出来的请求进行缓冲,而针对秒杀场景还有一种方法,就是对请求进行分层过滤,从而过滤掉一些无效的请求。分层过滤其实就是采用“漏斗”式设计来处理请求的,如下图所示。
考虑
- 很多人觉得在数据库层面实现高一致性最靠谱,确实,数据库有事务机制,能保证数据的原子性、一致性、隔离性和持久性 。比如使用悲观锁,在读取库存时就锁定记录,其他请求只能等待,这样能确保不会超卖,但缺点也很明显,并发性能太差,高并发下数据库压力巨大。
- 事务消息:利用消息队列的事务消息功能,确保库存扣减和后续业务操作要么都成功,要么都失败。
- 分布式锁:在操作库存前获取分布式锁,只有拿到锁的请求才能进行库存操作,避免并发冲突。
Plan B
降级(Downgrade)
所谓“降级”,就是当系统的容量达到一定程度时,限制或者关闭系统的某些非核心功能,从而把有限的资源保留给更核心的业务。它是一个有目的、有计划的执行过程,所以对降级我们一般需要有一套预案来配合执行。如果我们把它系统化,就可以通过预案系统和开关系统来实现降级。
执行降级无疑是在系统性能和用户体验之间选择了前者,降级后肯定会影响一部分用户的体验,例如在双 11 零点时,如果优惠券系统扛不住,可能会临时降级商品详情的优惠信息展示,把有限的系统资源用在保障交易系统正确展示优惠信息上,即保障用户真正下单时的价格是正确的。所以降级的核心目标是牺牲次要的功能和用户体验来保证核心业务流程的稳定,是一个不得已而为之的举措。
限流(Rate Limits)
如果说降级是牺牲了一部分次要的功能和用户的体验效果,那么限流就是更极端的一种保护措施了。限流就是当系统容量达到瓶颈时,我们需要通过限制一部分流量来保护系统,并做到既可以人工执行开关,也支持自动化保护的措施。