Background
Functional Requirements
Candidate: What kind of chat app shall we design? 1 on 1 or group based? Interviewer: It should support both 1 on 1 and group chat.
Candidate: Is this a mobile app? Or a web app? Or both? Interviewer: Both.
Candidate: For group chat, what is the group member limit? Interviewer: A maximum of 100 people
Candidate: What features are important for the chat app? Can it support attachment? Interviewer: 1 on 1 chat, group chat, online indicator. The system only supports text messages.
Non-functional Requirements
Candidate: What is the scale of this app? A startup app or massive scale? Interviewer: It should support 50 million daily active users (DAU).
- Candidate: Is there a message size limit?
- Interviewer: Yes, text length should be less than 100,000 characters long.
- Candidate: Is end-to-end encryption required?
- Interviewer: Not required for now but we will discuss that if time allows.
Candidate: How long shall we store the chat history? Interviewer: Forever.
Scope
How to Communicate
To develop a high-quality design, we should have a basic knowledge of how clients and servers communicate. In a chat system, clients can be either mobile applications or web applications. Clients do not communicate directly with each other. Instead, each client connects to a chat service, which supports all the features mentioned above. Let us focus on fundamental operations. The chat service must support the following functions:
- Receive messages from other clients.
- Find the right recipients for each message and relay the message to the recipients.
- If a recipient is not online, hold the messages for that recipient on the server until she is online.
Requests are initiated by the client for most client/server applications. This is also true for the sender side of a chat application. When the sender sends a message to the receiver via the chat service, it uses the time-tested HTTP protocol, which is the most common web protocol. In this scenario, the client opens a HTTP connection with the chat service and sends the message, informing the service to send the message to the receiver. The keep-alive is efficient for this because the keep-alive header allows a client to maintain a persistent connection with the chat service. It also reduces the number of TCP handshakes. HTTP is a fine option on the sender side, and many popular chat applications such as Facebook [1] used HTTP initially to send messages.
However, the receiver side is a bit more complicated. Since HTTP is client-initiated, it is not trivial to send messages from the server. Over the years, many techniques are used to simulate a server-initiated connection: polling, long polling, and WebSocket. Those are important techniques widely used in system design interviews so let us examine each of them.
Communication Protocol
Polling
Polling is a technique that the client periodically asks the server if there are messages available. Depending on polling frequency, polling could be costly. It could consume precious server resources to answer a question that offers no as an answer most of the time.
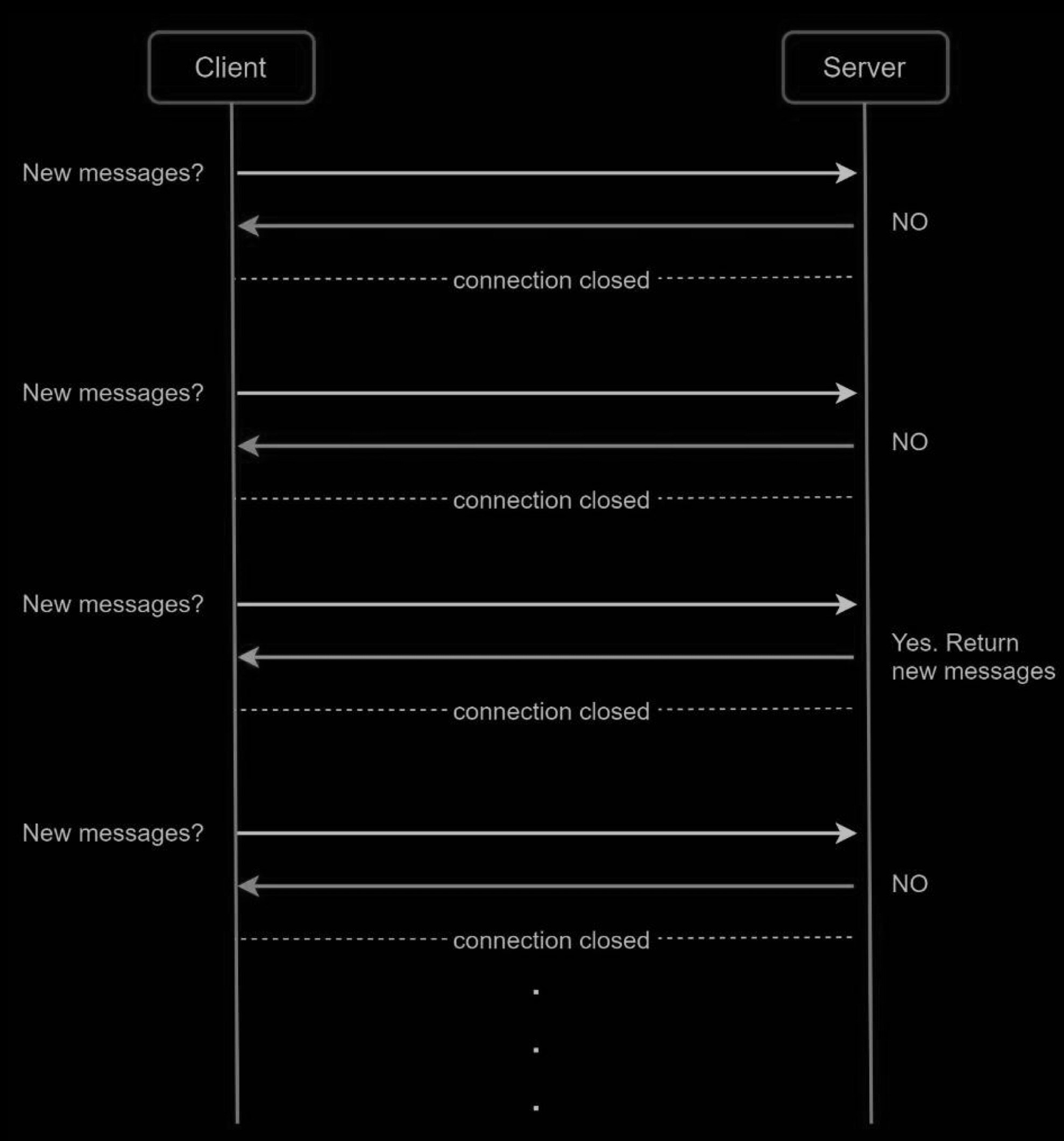
Long polling
Because polling could be inefficient, the next progression is long polling.
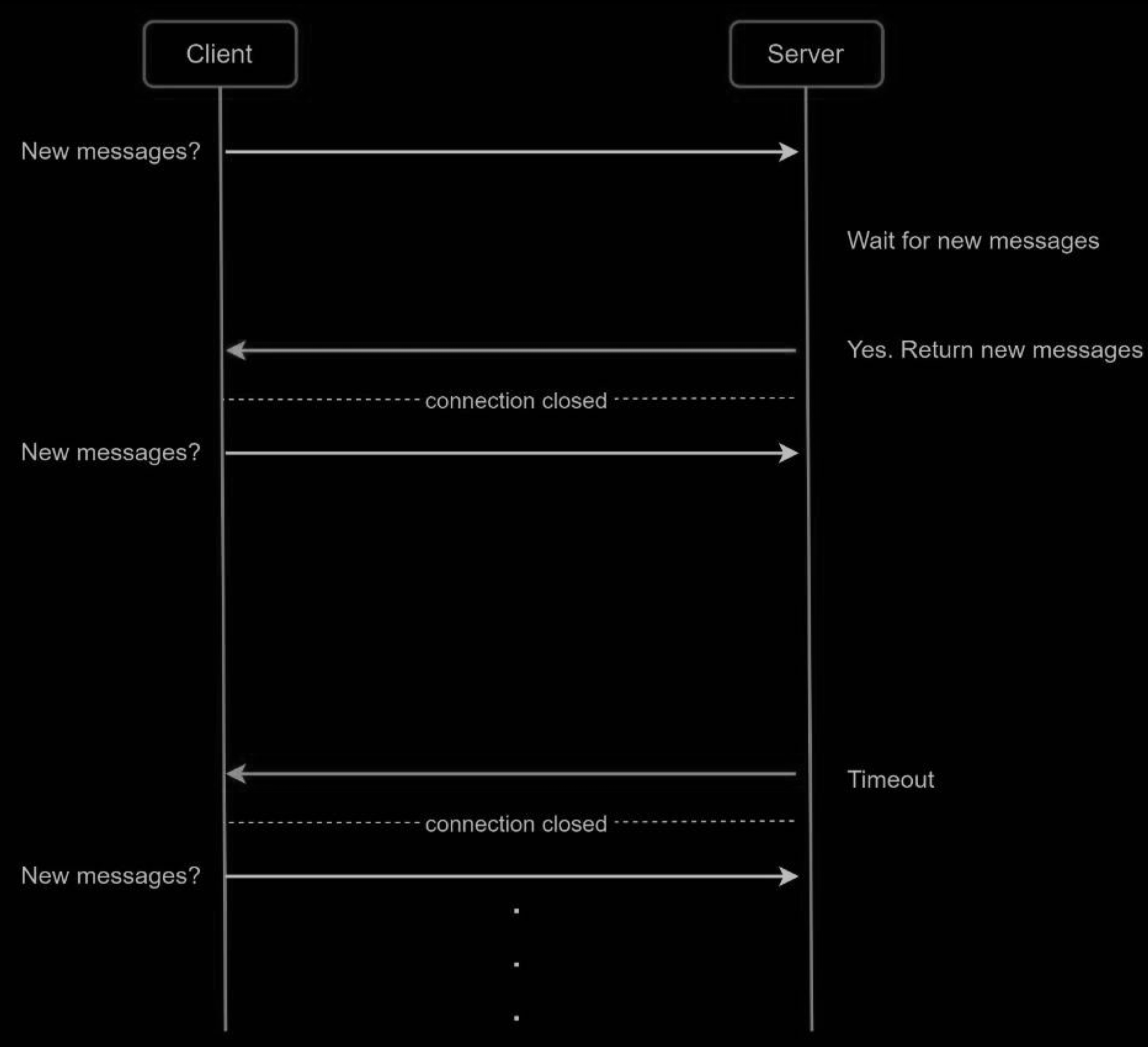
In long polling, a client holds the connection open until there are actually new messages available or a timeout threshold has been reached. Once the client receives new messages, it immediately sends another request to the server, restarting the process. Long polling has a few drawbacks:
- Sender and receiver may not connect to the same chat server. HTTP based servers are usually stateless. If you use round robin for load balancing, the server that receives the message might not have a long-polling connection with the client who receives the message.
- A server has no good way to tell if a client is disconnected.
- It is inefficient. If a user does not chat much, long polling still makes periodic connections after timeouts.
WebSocket
WebSocket is the most common solution for sending asynchronous updates from server to client.
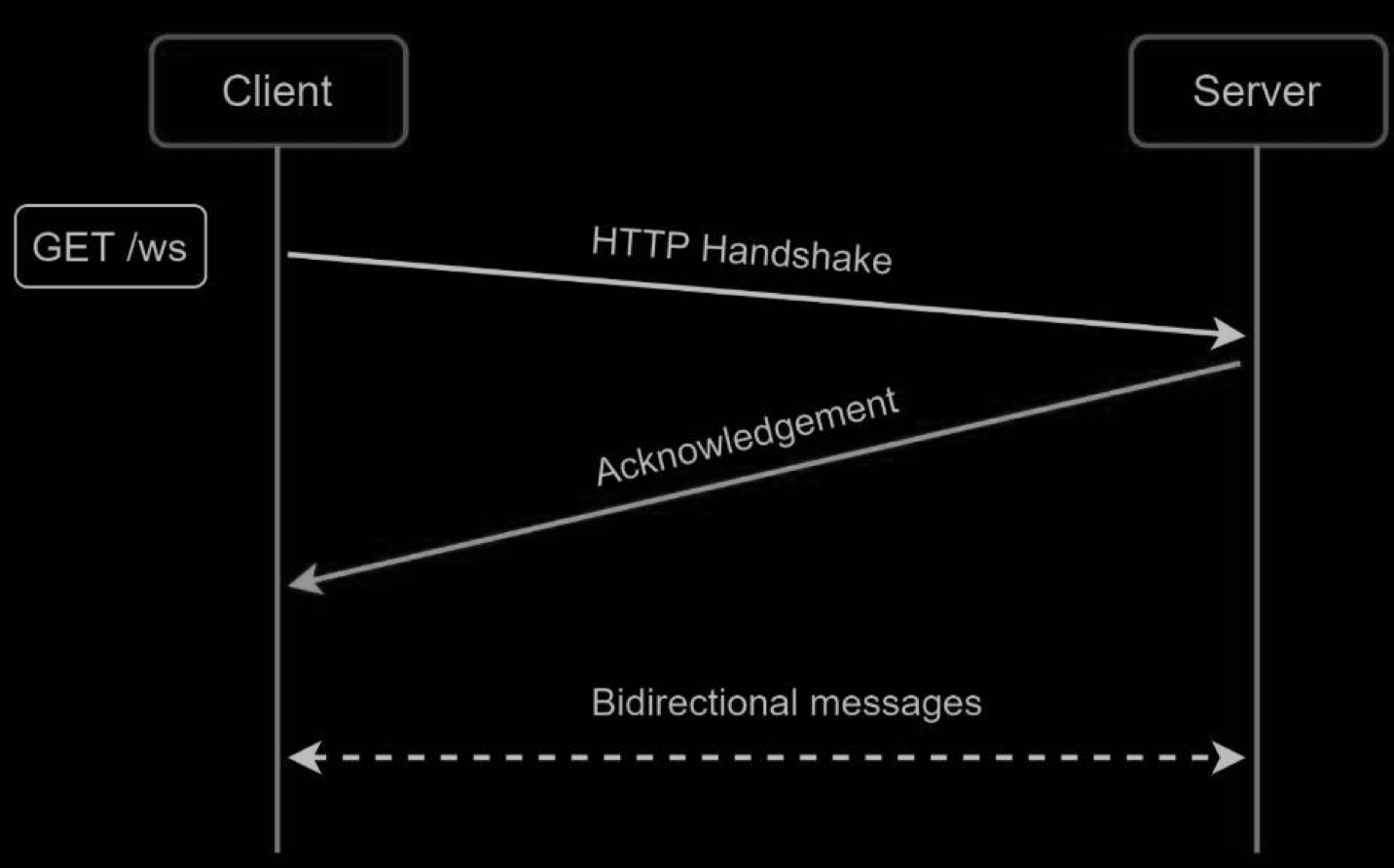
WebSocket connection is initiated by the client. It is bi-directional and persistent. It starts its life as a HTTP connection and could be “upgraded” via some well-defined handshake to a WebSocket connection. Through this persistent connection, a server could send updates to a client. WebSocket connections generally work even if a firewall is in place. This is because they use port 80 or 443 which are also used by HTTP/HTTPS connections.
Earlier we said that on the sender side HTTP is a fine protocol to use, but since WebSocket is bidirectional, there is no strong technical reason not to use it also for sending.
HTTP/2 and HTTP/3
HTTP/2:
- Introduced multiplexing, allowing multiple streams of data to be sent and received simultaneously over a single TCP connection.
- Supports server push, where the server can proactively send resources to the client without an explicit request.
- Reduces latency by avoiding the need for multiple connections.
HTTP/3:
- Built on QUIC, a transport protocol that operates over UDP.
- Provides all the features of HTTP/2, including multiplexing and server push, with reduced connection setup times and improved performance over unreliable networks.
- Enhanced bi-directional communication capabilities due to QUIC’s low-latency design and faster recovery from packet loss compared to TCP.
High-level Design

Proocol
- TCP
- HTTP
- WebSocket
Other features
- sign-up
- login
- user profile
- push notification
Components
- Chat services
Architecture
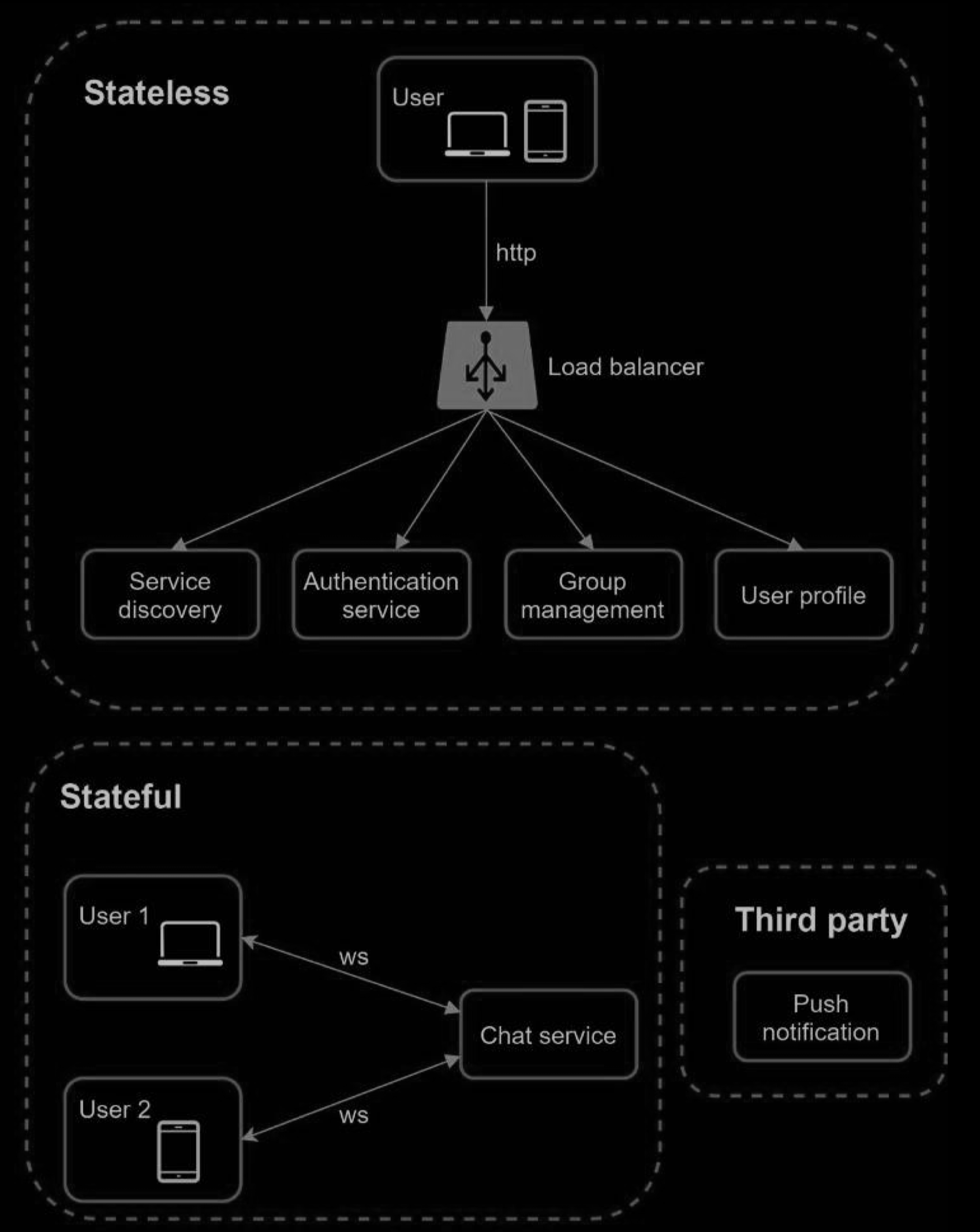
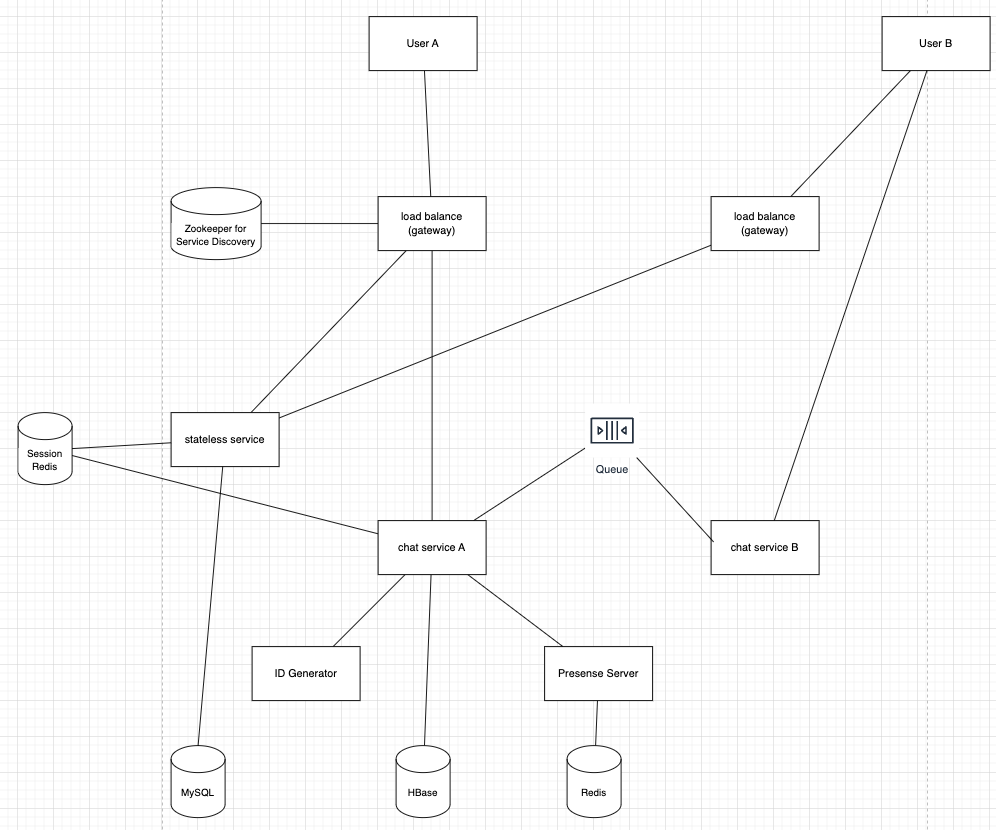
Stateless Services
Stateless services are traditional public-facing request/response services, used to manage the login, signup, user profile, etc. These are common features among many websites and apps.
Stateless services sit behind a load balancer whose job is to route requests to the correct services based on the request paths. These services can be monolithic or individual microservices. We do not need to build many of these stateless services by ourselves as there are services in the market that can be integrated easily. The one service that we will discuss more in deep dive is the service discovery. Its primary job is to give the client a list of DNS host names of chat servers that the client could connect to.
Stateful Service
The only stateful service is the chat service. The service is stateful because each client maintains a persistent network connection to a chat server. In this service, a client normally does not switch to another chat server as long as the server is still available. The service discovery coordinates closely with the chat service to avoid server overloading.
Third-party integration
For a chat app, push notification is the most important third-party integration. It is a way to inform users when new messages have arrived, even when the app is not running. Proper integration of push notification is crucial. R
Scalability
On a small scale, all services listed above could fit in one server. Even at the scale we design for, it is in theory possible to fit all user connections in one modern cloud server. The number of concurrent connections that a server can handle will most likely be the limiting factor. In our scenario, at 1M concurrent users, assuming each user connection needs 10K of memory on the server (this is a very rough figure and very dependent on the language choice), it only needs about 10GB of memory to hold all the connections on one box.
If we propose a design where everything fits in one server, this may raise a big red flag in the interviewer’s mind. No technologist would design such a scale in a single server. Single server design is a deal breaker due to many factors. The single point of failure is the biggest among them.
However, it is perfectly fine to start with a single server design. Just make sure the interviewer knows this is a starting point. Putting everything we mentioned together.
Storage
At this point, we have servers ready, services up running and third-party integrations complete. Deep down the technical stack is the data layer. Data layer usually requires some effort to get it correct. An important decision we must make is to decide on the right type of database to use: relational databases or NoSQL databases? To make an informed decision, we will examine the data types and read/write patterns.
Two types of data exist in a typical chat system. The first is generic data, such as user profile, setting, user friends list. These data are stored in robust and reliable relational databases. Replication and sharding are common techniques to satisfy availability and scalability requirements.
The second is unique to chat systems: chat history data. It is important to understand the read/write pattern.
The second is unique to chat systems: chat history data. It is important to understand the read/write pattern.
- The amount of data is enormous for chat systems. A previous study reveals that Facebook messenger and Whatsapp process 60 billion messages a day.
- Only recent chats are accessed frequently. Users do not usually look up for old chats.
- Although very recent chat history is viewed in most cases, users might use features that require random access of data, such as search, view your mentions, jump to specific messages, etc. These cases should be supported by the data access layer.
- The read to write ratio is about 1:1 for 1 on 1 chat apps.
Selecting the correct storage system that supports all of our use cases is crucial. We recommend key-value stores for the following reasons:
- Key-value stores allow easy horizontal scaling.
- Key-value stores provide very low latency to access data.
- Relational databases do not handle long tail of data well. When the indexes grow large, random access is expensive.
- Key-value stores are adopted by other proven reliable chat applications. For example, both Facebook messenger and Discord use key-value stores. Facebook messenger uses HBase and Discord uses Cassandra.
Data Models
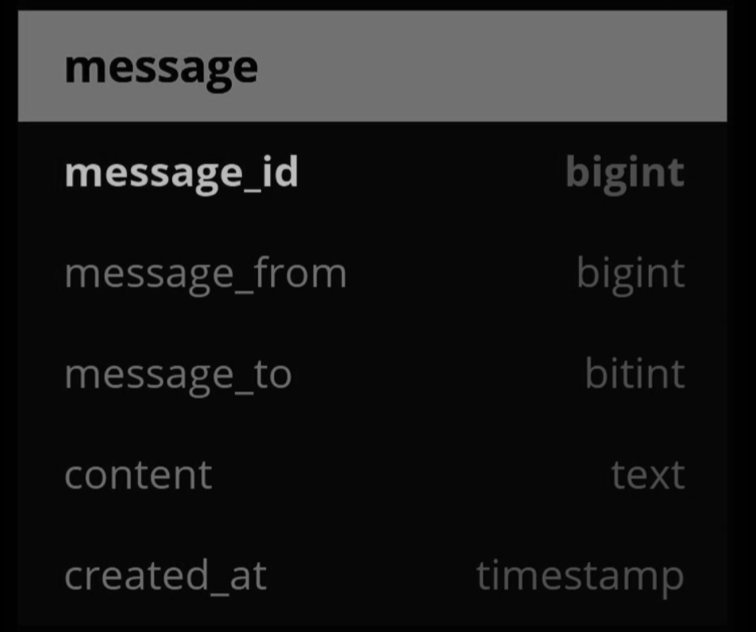
Message table for 1 on 1 chat
The pic below shows the message table for 1 on 1 chat. The primary key is message_id, which helps to decide message sequence. We cannot rely on created_at to decide the message sequence because two messages can be created at the same time.
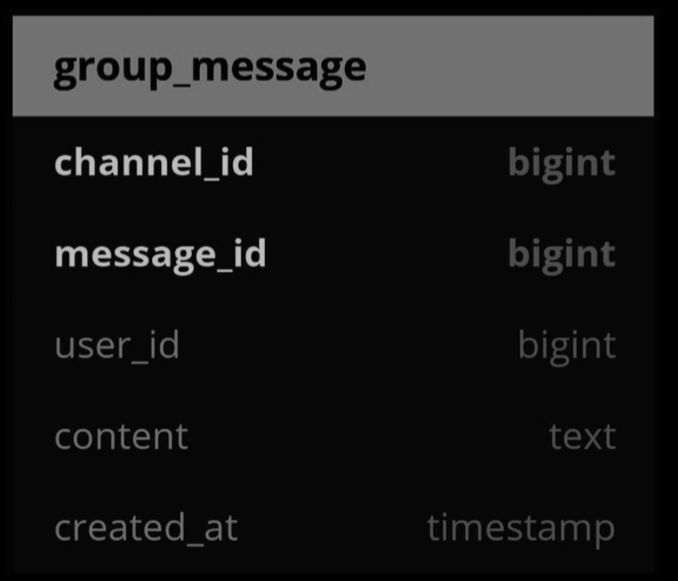
Message table for group chat
The pic below shows the message table for group chat. The composite primary key is (channel_id, message_id). Channel and group represent the same meaning here. channel_id is the partition key because all queries in a group chat operate in a channel
Message ID
How to generate message_id is an interesting topic worth exploring. Message_id carries the responsibility of ensuring the order of messages. To ascertain the order of messages, message_id must satisfy the following two requirements:
- IDs must be unique.
- IDs should be sortable by time, meaning new rows have higher IDs than old ones.
How can we achieve those two guarantees? The first idea that comes to mind is the “auto_increment” keyword in MySql. However, NoSQL databases usually do not provide such a feature.
The second approach is to use a global 64-bit sequence number generator like Snowflake.
The final approach is to use local sequence number generator. Local means IDs are only unique within a group. The reason why local IDs work is that maintaining message sequence within one-on-one channel or a group channel is sufficient. This approach is easier to implement in comparison to the global ID implementation.
Deep Dive
Service Discovery
The primary role of service discovery is to recommend the best chat server for a client based on the criteria like geographical location, server capacity, etc. Apache Zookeeper is a popular open-source solution for service discovery. It registers all the available chat servers and picks the best chat server for a client based on predefined criteria.
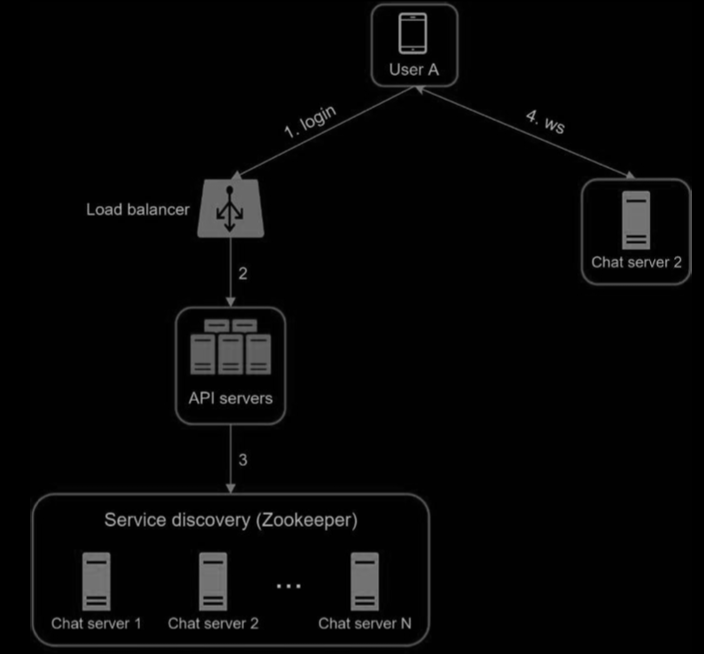
Find a Chat Server via API Server
-
User A tries to log in to the app.
-
The load balancer sends the login request to API servers.
-
After the backend authenticates the user, service discovery finds the best chat server for User A. In this example, server 2 is chosen and the server info is returned back to User A.
-
User A connects to chat server 2 through WebSocket.
Message flows
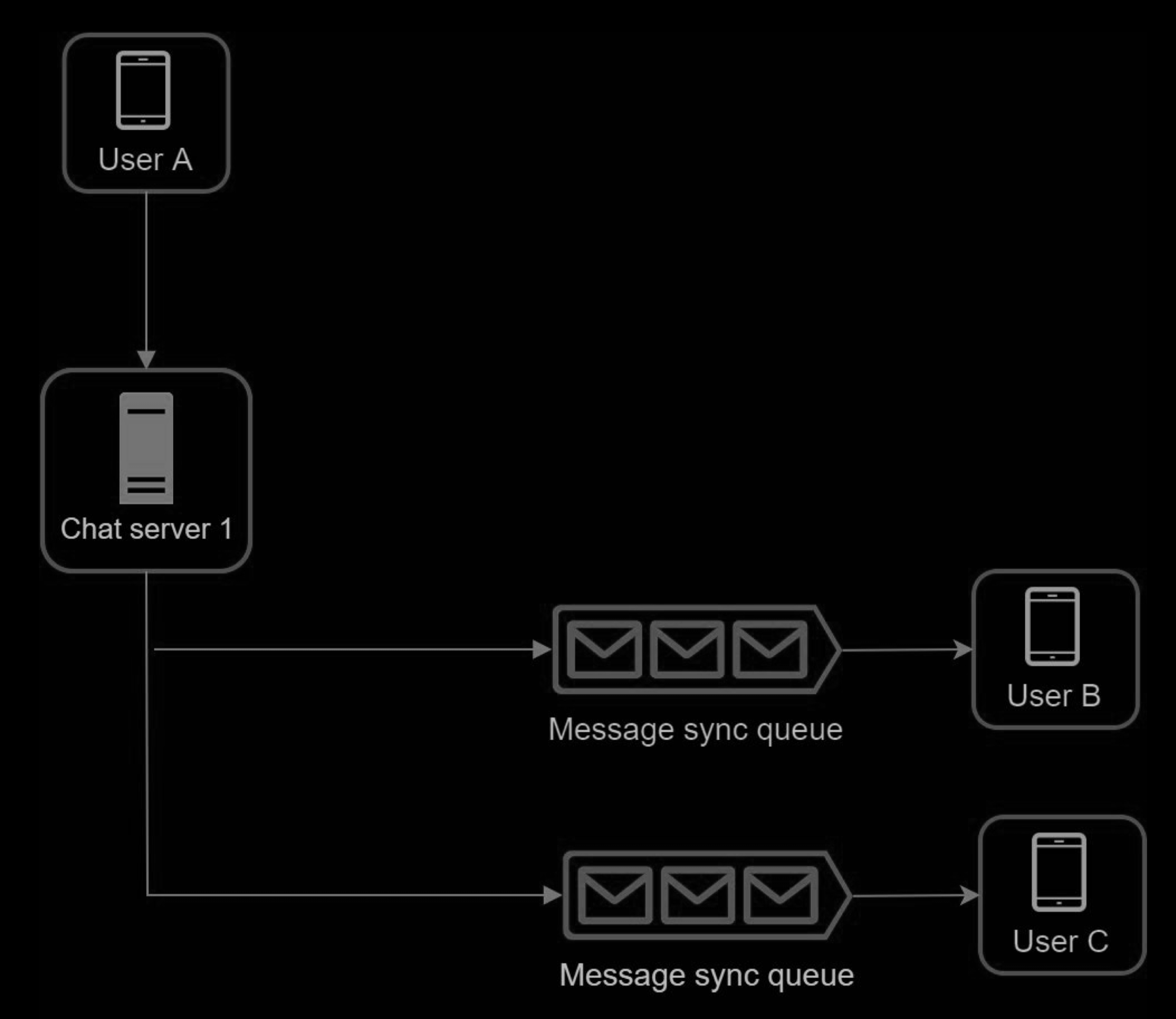
1 on 1 chat flow
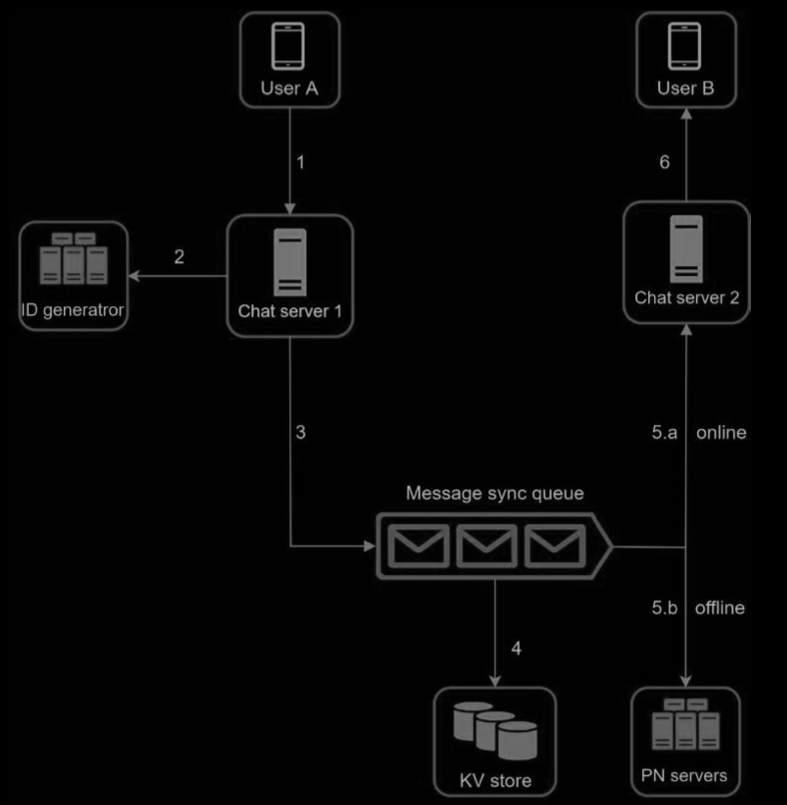
-
User A sends a chat message to Chat server 1.
-
Chat server 1 obtains a message ID from the ID generator.
-
Chat server 1 sends the message to the message sync queue.
-
The message is stored in a key-value store.
-
If User B is online, the message is forwarded to Chat server 2 where User B is connected.
-
If User B is offline, a push notification is sent from push notification (PN) servers.
-
Chat server 2 forwards the message to User B. There is a persistent WebSocket connection between User B and Chat server 2.
Message synchronization across multiple devices
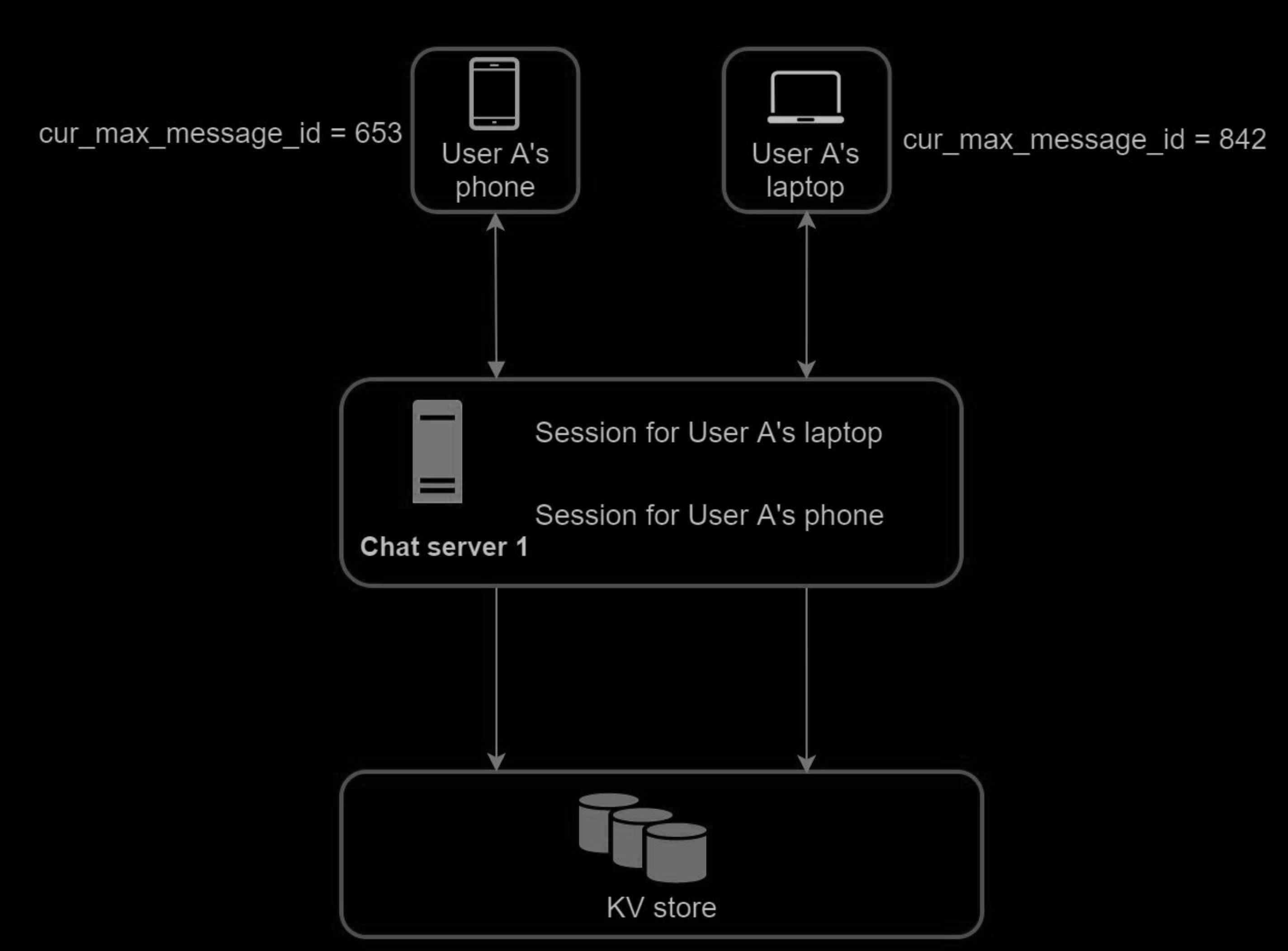
Many users have multiple devices. We will explain how to sync messages across multiple devices.
user A has two devices: a phone and a laptop. When User A logs in to the chat app with her phone, it establishes a WebSocket connection with Chat server 1. Similarly, there is a connection between the laptop and Chat server 1.
Each device maintains a variable called cur_max_message_id, which keeps track of the latest message ID on the device. Messages that satisfy the following two conditions are considered as news messages:
- The recipient ID is equal to the currently logged-in user ID.
- Message ID in the key-value store is larger than cur_max_message_id .
With distinct cur_max_message_id on each device, message synchronization is easy as each device can get new messages from the KV store.
Small group chat flow(写扩散)
User disconnection
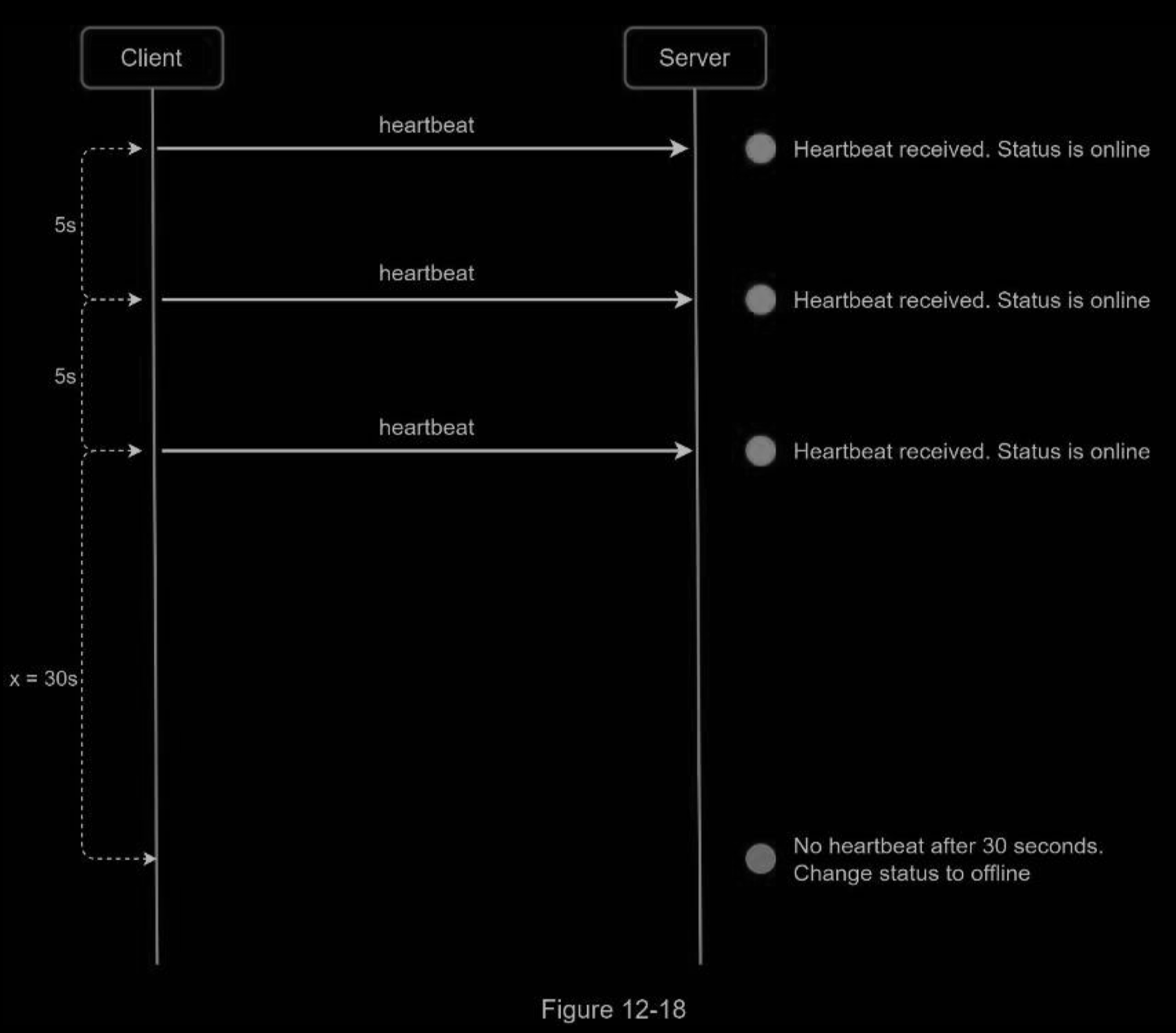
We all wish our internet connection is consistent and reliable. However, that is not always the case; thus, we must address this issue in our design. When a user disconnects from the internet, the persistent connection between the client and server is lost. A naive way to handle user disconnection is to mark the user as offline and change the status to online when the connection re-establishes. However, this approach has a major flaw. It is common for users to disconnect and reconnect to the internet frequently in a short time. For example, network connections can be on and off while a user goes through a tunnel. Updating online status on every disconnect/reconnect would make the presence indicator change too often, resulting in poor user experience.
We introduce a heartbeat mechanism to solve this problem. Periodically, an online client sends a heartbeat event to presence servers. If presence servers receive a heartbeat event within a certain time, say x seconds from the client, a user is considered as online. Otherwise, it is offline.
In the pic below, the client sends a heartbeat event to the server every 5 seconds. After sending 3 heartbeat events, the client is disconnected and does not reconnect within x = 30 seconds (This number is arbitrarily chosen to demonstrate the logic). The online status is changed to offline.
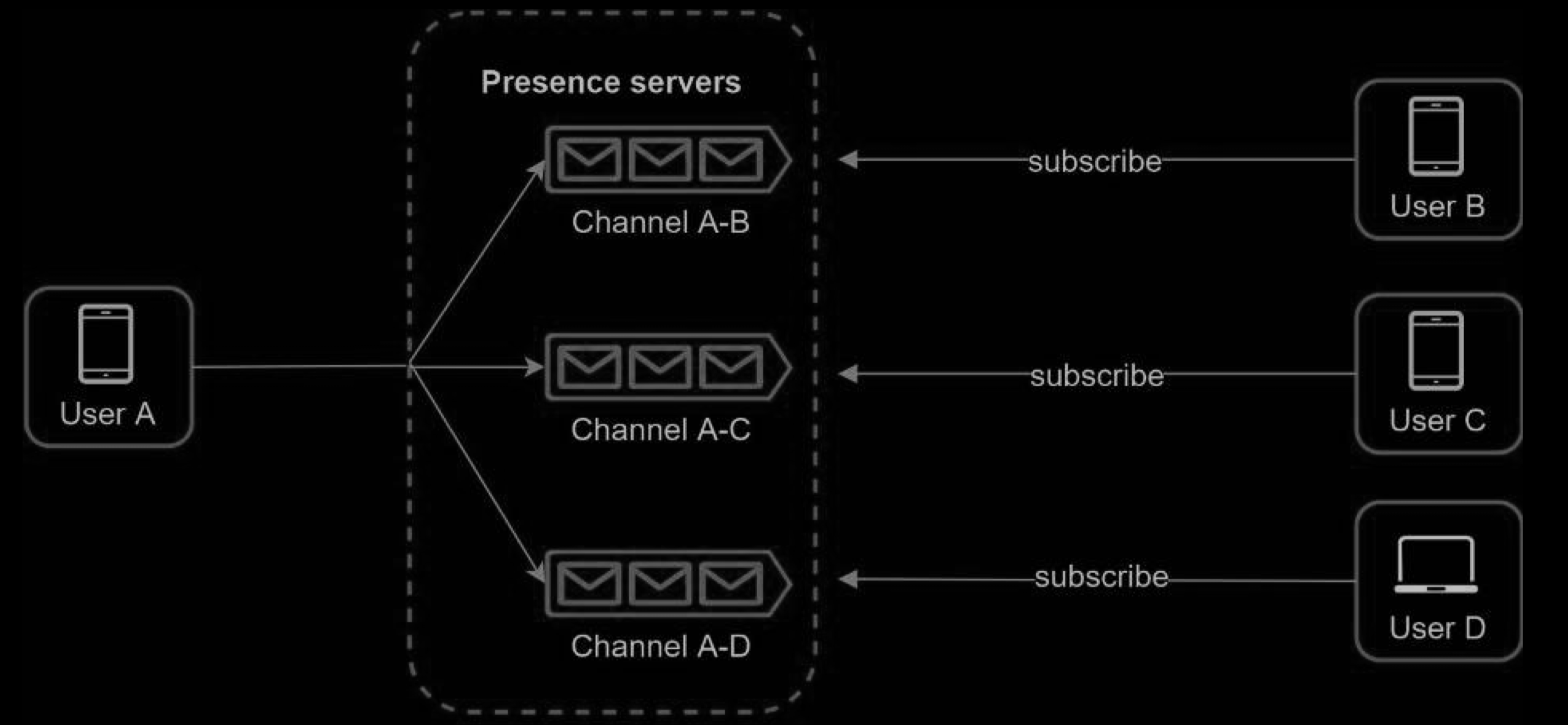
Online status fanout(写扩散)
How do user A’s friends know about the status changes? Figure 12-19 explains how it works. Presence servers use a publish-subscribe model, in which each friend pair maintains a channel. When User A’s online status changes, it publishes the event to three channels, channel A-B, A-C, and A-D. Those three channels are subscribed by User B, C, and D, respectively. Thus, it is easy for friends to get online status updates. The communication between clients and servers is through real-time WebSocket.
The above design is effective for a small user group. For instance, WeChat uses a similar approach because its user group is capped to 500. For larger groups, informing all members about online status is expensive and time consuming. Assume a group has 100,000 members. Each status change will generate 100,000 events. To solve the performance bottleneck, a possible solution is to fetch online status only when a user enters a group or manually refreshes the friend list.
Wrap up
If you have extra time at the end of the interview, here are additional talking points:
- Extend the chat app to support media files such as photos and videos. Media files are significantly larger than text in size. Compression, cloud storage, and thumbnails are interesting topics to talk about.
- End-to-end encryption. Whatsapp supports end-to-end encryption for messages. Only the sender and the recipient can read messages.
- Caching messages on the client-side is effective to reduce the data transfer between the client and server.
- Improve load time. Slack built a geographically distributed network to cache users’ data, channels, etc. for better load time
- Error handling.
- The chat server error. There might be hundreds of thousands, or even more persistent connections to a chat server. If a chat server goes offline, service discovery (Zookeeper) will provide a new chat server for clients to establish new connections with.
- Message resent mechanism. Retry and queueing are common techniques for resending messages.
Short Version
-
requirements
- Functional requirement
- single/group chat
- many people in a group
- supported media types
- cloud storage - CDN
- Thumbnails
- non-functional requirement
- active/total users num
- Functional requirement
-
high level
- service discovery
- Poll model/procotol
- websocket
- TCP
- HTTP3 - QUIC
- architecture
- stateful/stateless services
- chat
- api
- message queue
- thrid-party integration
- stateful/stateless services
- data model
- storage
- chat content - noSQL
- user info - mysql
-
details
- service discovery
- find chat server - Zookeeper
- message data flow
- Online presence - heart beats
- service discovery
-
wrap up
- Compression
- end-to-end encryption
- failover
- High-availability
- rate limit/ downgrade plan
Reference
- System Design Interview – An insider’s guide
- Erlang at Facebook: https://www.erlang-factory.com/upload/presentations/31/EugeneLetuchy-ErlangatFacebook.pdf
- Messenger and WhatsApp process 60 billion messages a day: https://www.theverge.com/2016/4/12/11415198/facebook-messenger-whatsapp-numbermessages-vs-sms-f8-2016
- Long tail: https://en.wikipedia.org/wiki/Long_tail
- The Underlying Technology of Messages: https://www.facebook.com/notes/facebookengineering/the-underlying-technology-of-messages/454991608919/
- How Discord Stores Billions of Messages: https://blog.discordapp.com/how-discordstores-billions-of-messages-7fa6ec7ee4c7
- Announcing Snowflake: https://blog.twitter.com/engineering/en_us/a/2010/announcingsnowflake.html
- From nothing: the evolution of WeChat background system (Article in Chinese): https://www.infoq.cn/article/the-road-of-the-growth-weixin-background
- End-to-end encryption: https://faq.whatsapp.com/en/android/28030015/
- Flannel: An Application-Level Edge Cache to Make Slack Scale: https://slack.engineering/flannel-an-application-level-edge-cache-to-make-slack-scaleb8a6400e2f6b
todo
- Discord