Scope
-
QPS
-
SLA
-
Required Performance
- The system should be able to generate 10,000 IDs per second.
-
Do IDs only contain numerical values?
- Interviewer: Yes, that is correct.
-
What is the ID length requirement?
- Interviewer: IDs should fit into 64-bit.
-
For each new record, does ID increment by 1?
- Interviewer: The ID increments by time but not necessarily only increments by 1. IDs created in the evening are larger than those created in the morning on the same day.
High-level Design
Scenarios to use ID generator
Multiple options can be used to generate unique IDs in distributed systems. The options we considered are:
- Multi-master replication
- Universally unique identifier (UUID)
- Ticket server
- Twitter snowflake approach
Multi-master replication
This approach uses the databases’ auto_increment feature. Instead of increasing the next ID by 1, we increase it by k, where k is the number of database servers in use. As illustrated in Figure 7-2, next ID to be generated is equal to the previous ID in the same server plus 2. This solves some scalability issues because IDs can scale with the number of database servers. However, this strategy has some major drawbacks:
- Hard to scale with multiple data centers
- IDs do not go up with time across multiple servers.
- It does not scale well when a server is added or removed.
Universally unique identifier (UUID)
UUID 是 Universally Unique Identifier(通用唯一标识符) 的缩写。UUID 包含 32 个 16 进制数字(8-4-4-4-12)。
RFC 4122 中关于 UUID 的示例是这样的:
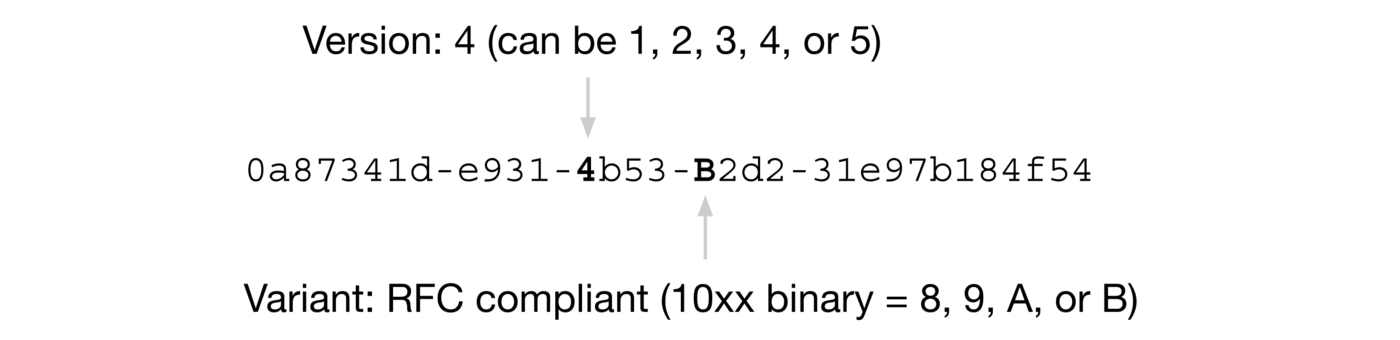
我们这里重点关注一下这个 Version(版本),不同的版本对应的 UUID 的生成规则是不同的。
5 种不同的 Version(版本)值分别对应的含义:
- 版本 1 : UUID 是根据时间和节点 ID(通常是 MAC 地址)生成;
- 版本 2 : UUID 是根据标识符(通常是组或用户 ID)、时间和节点 ID 生成;
- 版本 3、版本 5 : 版本 5 - 确定性 UUID 通过散列(hashing)名字空间(namespace)标识符和名称生成;
- 版本 4 : UUID 使用随机性或伪随机性生成。
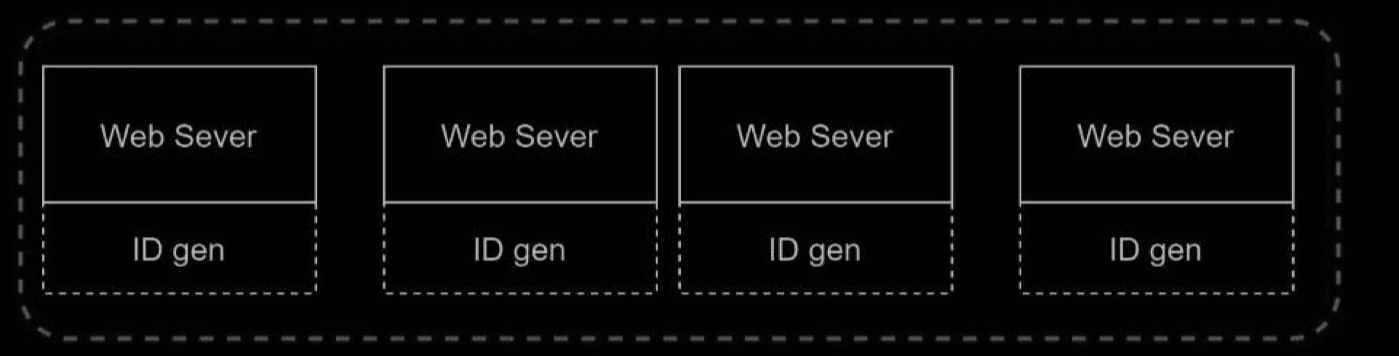
In this design, each web server contains an ID generator, and a web server is responsible for generating IDs independently.
Pros:
- Generating UUID is simple. No coordination between servers is needed so there will not be any synchronization issues.
- The system is easy to scale because each web server is responsible for generating IDs they consume. ID generator can easily scale with web servers.
Cons:
- IDs are 128 bits long, but our requirement is 64 bits.
- IDs do not go up with time.
- IDs could be non-numeric.
Ticket server
The idea is to use a centralized auto_increment feature in a single database server (Ticket Server). To learn more about this, refer to flicker’s engineering blog article [2].
Pros:
- Numeric IDs.
- It is easy to implement, and it works for small to medium-scale applications.
Cons:
- Single point of failure. Single ticket server means if the ticket server goes down, all systems that depend on it will face issues. To avoid a single point of failure, we can set up multiple ticket servers. However, this will introduce new challenges such as data synchronization.
Twitter snowflake approach

Each section is explained below.
- Sign bit: 1 bit. It will always be 0. This is reserved for future uses. It can potentially be used to distinguish between signed and unsigned numbers.
- Timestamp: 41 bits. Milliseconds since the epoch or custom epoch. We use Twitter snowflake default epoch 1288834974657, equivalent to Nov 04, 2010, 01:42:54 UTC.
- Datacenter ID: 5 bits, which gives us 2 ^ 5 = 32 datacenters.
- Machine ID: 5 bits, which gives us 2 ^ 5 = 32 machines per datacenter.
- Sequence number: 12 bits. For every ID generated on that machine/process, the sequence number is incremented by 1. The number is reset to 0 every millisecond.
Deep Dive
Reference
- System Design Interview – An insider’s guide
- https://tech.meituan.com/2017/04/21/mt-leaf.html