Background
If the API request count exceeds the threshold defined by the rate limiter, all the excess calls are blocked. Here are a few examples:
- A user can write no more than 2 posts per second.
- You can create a maximum of 10 accounts per day from the same IP address.
- You can claim rewards no more than 5 times per week from the same device.
The benefits of using an API rate limiter:
- Prevent resource starvation caused by Denial of Service (DoS) attack. Almost all APIs published by large tech companies enforce some form of rate limiting. For example, Twitter limits the number of tweets to 300 per 3 hours. Google docs APIs have the following default limit: 300 per user per 60 seconds for read requests. A rate limiter prevents DoS attacks, either intentional or unintentional, by blocking the excess calls.
- Reduce cost. Limiting excess requests means fewer servers and allocating more resources to high priority APIs. Rate limiting is extremely important for companies that use paid third party APIs. For example, you are charged on a per-call basis for the following external APIs: check credit, make a payment, retrieve health records, etc. Limiting the number of calls is essential to reduce costs.
- Prevent servers from being overloaded. To reduce server load, a rate limiter is used to filter out excess requests caused by bots or users’ misbehavior.
限流(Rate Limit)
Rate limiting is a technique used to control the rate at which requests are made to a network, server, or other resource. It is used to prevent excessive or abusive use of a resource and to ensure that the resource is available to all users.
Rate limiting is often used to protect against denial-of-service (DoS) attacks, which are designed to overwhelm a network or server with a high volume of requests, rendering it unavailable to legitimate users. It can also be used to limit the number of requests made by individual users, to ensure that a resource is not monopolized by a single user or group of users.
Scope
Functional Requirements
- Candidate: What kind of rate limiter are we going to design? Is it a client-side rate limiter or server-side API rate limiter?
- Interviewer: Great question. We focus on the server-side API rate limiter.
- client-side may be bypassed
-
- I could assume we use the rate limiter for one API or like different APIs in different services, i.e., the system work in a distributed environment
-
- Candidate: Does the rate limiter throttle API requests based on IP, the user ID, or other properties?
- Interviewer: The rate limiter should be flexible enough to support different sets of throttle rules.
-
- Candidate: Do we need to inform users who are throttled? Interviewer: Yes.
-
Let us assume that we don’t wanna integrate the rate limiter into any existing middlewares
- E.g., for service mesh, we need rate limiting during RPC calls
- For gateways, normally we need the functionality of the rating limiter as well.
-
Let us assume the scope of authentication is not under this rate limit
-
Do we wanna control the limit in real-time? or just hard-coded?
Non-functional Requirements
-
data size
-
latency
-
Candidate: What is the scale of the system? Is it built for a startup or a big company with a large user base?
- Interviewer: The system must be able to handle a large number of requests.
-
Candidate: Is the rate limiter a separate service or should it be implemented in application code? -
Interviewer: It is a design decision up to you -
High fault tolerance. If there are any problems with the rate limiter (for example, a cache server goes offline), it does not affect the entire system.
-
Other non-functional requirements? e.g., logging, monitoring
High-level Design
Where to put the rate limiter?
Intuitively, you can implement a rate limiter at either the client or server-side.
- Client-side implementation. Generally speaking, client is an unreliable place to enforce rate limiting because client requests can easily be forged by malicious actors. Moreover, we might not have control over the client implementation.
- Server-side implementation.

- rate limiter middleware
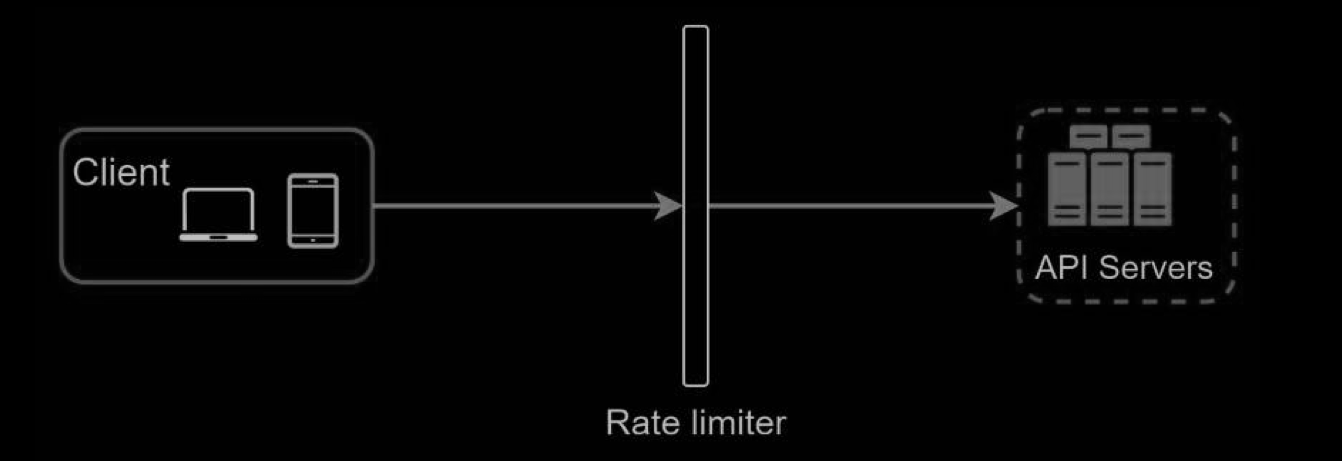
- Besides the client and server-side implementations, there is an alternative way. Instead of putting a rate limiter at the API servers, we create a rate limiter middleware,
Algorithms for rate limiting
关于限流的算法大体上可以分为四类:固定窗口计数器(Fixed Window Counter)、滑动窗口计数器(Silding Window Counter)、漏桶(也有称漏斗,Leaky bucket)、令牌桶(Token bucket)。
令牌桶(Token Bucket)
令牌桶算法是指系统以一定地速度往令牌桶里丢令牌,当一个请求过来的时候,会去令牌桶里申请一个令牌,如果能够获取到令牌,那么请求就可以正常进行,反之被丢弃。
现在的令牌桶算法,像Guava和Sentinel的实现都有冷启动/预热的方式,为了避免在流量激增的同时把系统打挂,令牌桶算法会在最开始一段时间内冷启动,随着流量的增加,系统会根据流量大小动态地调整生成令牌的速度,最终直到请求达到系统的阈值。
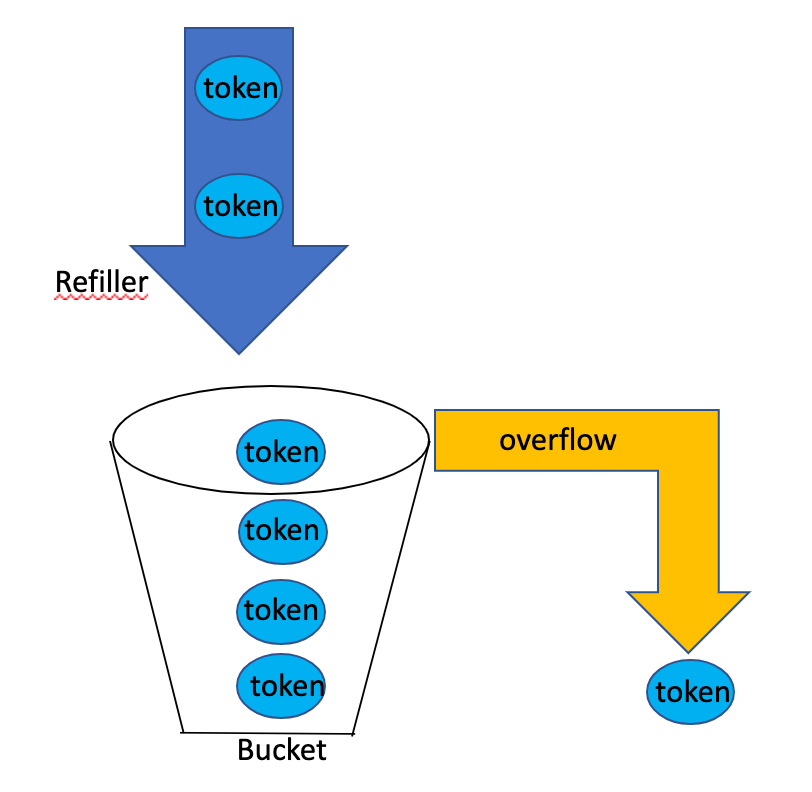
- Refill 5 tokens at 1 minute interval
- One coming request takes 1 token
- When a request comes and there no token, reject this request
Pros and Cons
Pros:
- The algorithm is easy to implement.
- Memory efficient.
- Token bucket allows a burst of traffic for short periods. A request can go through as long as there are tokens left.
Cons:
- Two parameters in the algorithm are bucket size and token refill rate. However, it might be challenging to tune them properly.
漏桶(Leaky Bucket)
漏桶算法,人如其名,他就是一个漏的桶,不管请求的数量有多少,最终都会以固定的出口流量大小匀速流出,如果请求的流量超过漏桶大小,那么超出的流量将会被丢弃。
也就是说流量流入的速度是不定的,但是流出的速度是恒定的。
这个和MQ削峰填谷的思想比较类似,在面对突然激增的流量的时候,通过漏桶算法可以做到匀速排队,固定速度限流。
漏桶算法的优势是匀速,匀速是优点也是缺点,很多人说漏桶不能处理突增流量,这个说法并不准确。
漏桶本来就应该是为了处理间歇性的突增流量,流量一下起来了,然后系统处理不过来,可以在空闲的时候去处理,防止了突增流量导致系统崩溃,保护了系统的稳定性。
但是,换一个思路来想,其实这些突增的流量对于系统来说完全没有压力,你还在慢慢地匀速排队,其实是对系统性能的浪费。
所以,对于这种有场景来说,令牌桶算法比漏桶就更有优势。
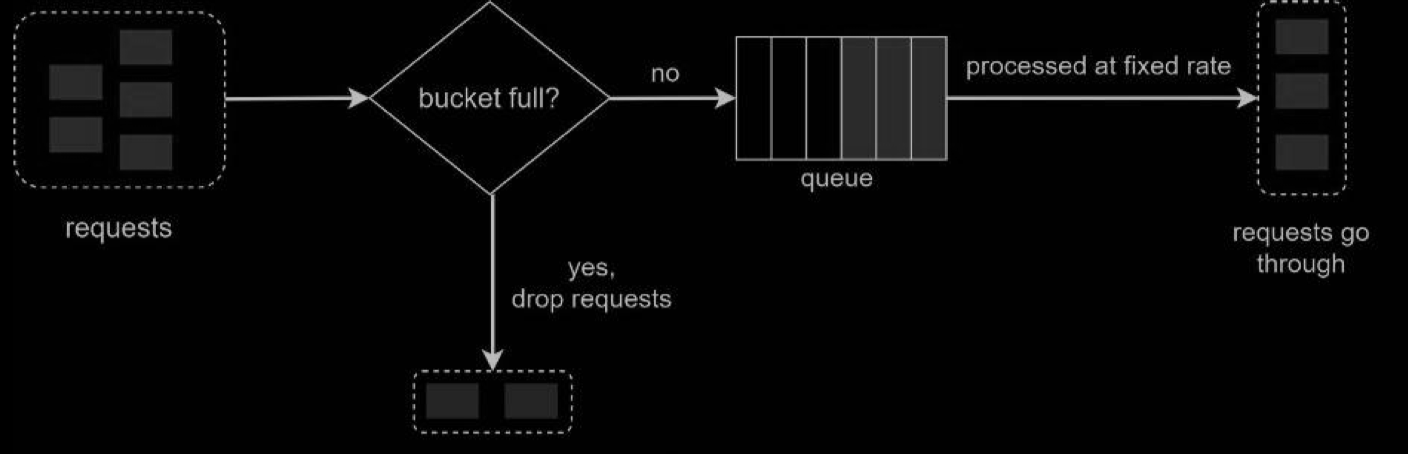
The leaking bucket algorithm is similar to the token bucket except that requests are processed at a fixed rate. It is usually implemented with a first-in-first-out (FIFO) queue. The algorithm works as follows:
- When a request arrives, the system checks if the queue is full. If it is not full, the request is added to the queue.
- Otherwise, the request is dropped
- Requests are pulled from the queue and processed at regular intervals.
Pros and Cons
Pros:
- Memory efficient given the limited queue size.
- Requests are processed at a fixed rate therefore it is suitable for use cases that a stable outflow rate is needed.
Cons:
- A burst of traffic fills up the queue with old requests, and if they are not processed in time, recent requests will be rate limited.
- There are two parameters in the algorithm. It might not be easy to tune them properly.
固定窗口计数器(Fixed Window Counter)
Fixed window counter algorithm works as follows:
- The algorithm divides the timeline into fix-sized time windows and assign a counter for each window.
- Each request increments the counter by one.
- Once the counter reaches the pre-defined threshold, new requests are dropped until a new time window starts.
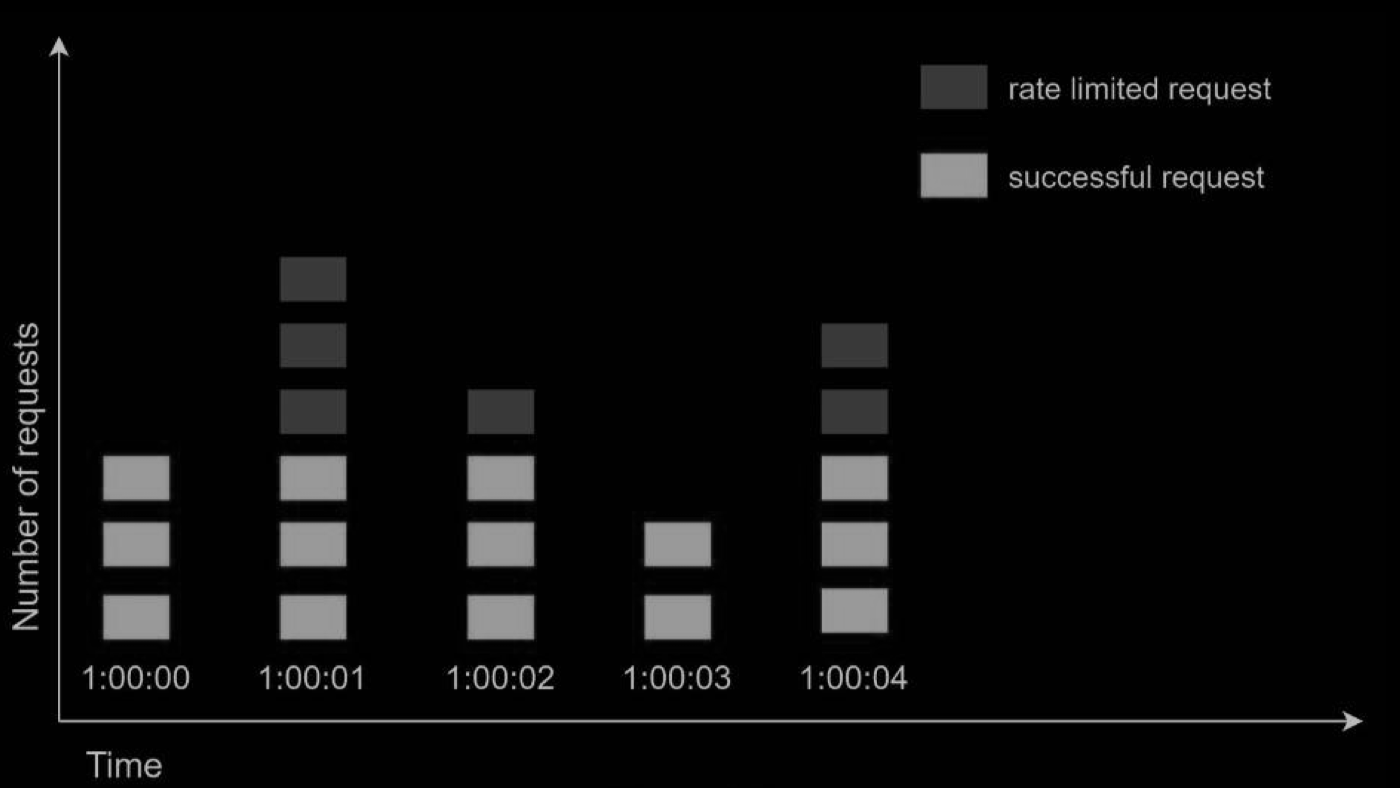
Let us use a concrete example to see how it works. In the Figure below, the time unit is 1 second and the system allows a maximum of 3 requests per second. In each second window, if more than 3 requests are received, extra requests are dropped as shown below
问题
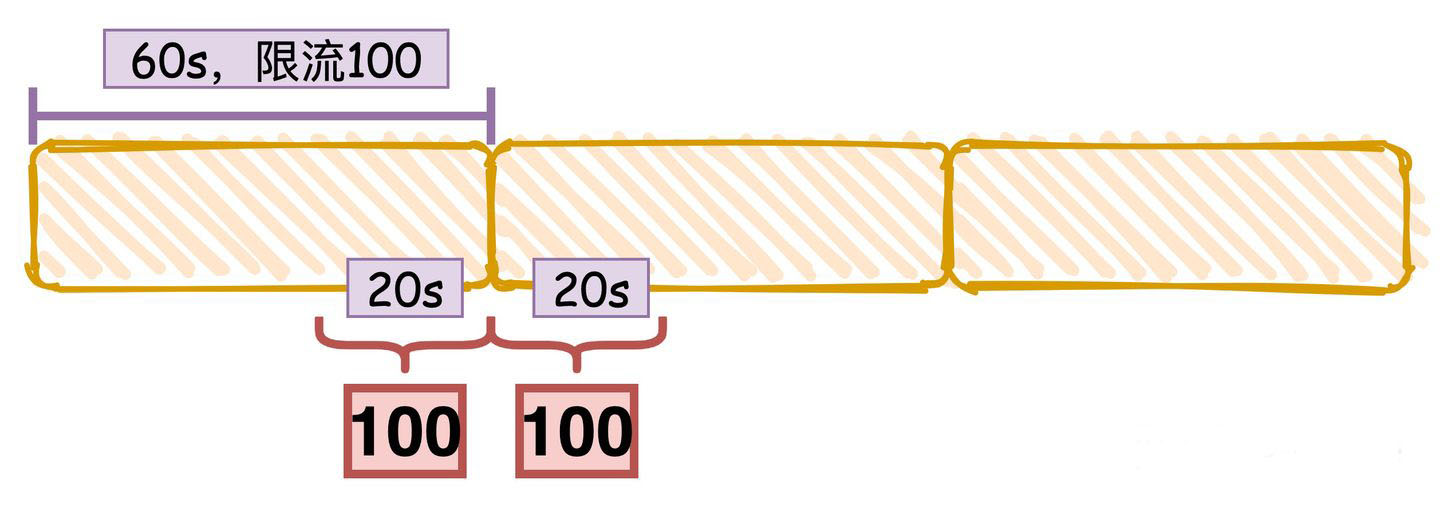
A major problem with this algorithm is that a burst of traffic at the edges of time windows could cause more requests than allowed quota to go through. Consider the following case: 我们下图中的黄色区域就是固定时间窗口,默认时间范围是60s,限流数量是100。
如图中括号内所示,前面一段时间都没有流量,刚好后面20秒内来了100个请求,此时因为没有超过限流阈值,所以请求全部通过,然后下一个窗口的20秒内同样通过了100个请求。
所以变相的相当于在这个括号的40秒的时间内就通过了200个请求,超过了我们限流的阈值。
Pros and Cons
Pros:
- Memory efficient.
- Easy to understand.
- Resetting available quota at the end of a unit time window fits certain use cases.
Cons:
- Spike in traffic at the edges of a window could cause more requests than the allowed quota to go through.
Implementation
Redis
Use LUA script to include below to achieve atomicity:
INCR- Increments the number stored at
keyby one. - If the key does not exist, it is set to
0before performing the operation.
- Increments the number stored at
TTL- Expire the key after every 1 second
滑动窗口计数器(Silding Window Counter)
比如我们下图中的黄色区域就是固定时间窗口,默认时间范围是60s,限流数量是100。
如图中括号内所示,前面一段时间都没有流量,刚好后面20秒内来了100个请求,此时因为没有超过限流阈值,所以请求全部通过,然后下一个窗口的20秒内同样通过了100个请求。
所以变相的相当于在这个括号的40秒的时间内就通过了200个请求,超过了我们限流的阈值。
为解决这个问题,计数器算法经过优化后,产生了滑动窗口算法:
我们将时间间隔均匀分隔,比如将一分钟分为6个10秒,每一个10秒内单独计数,总的数量限制为这6个10秒的总和,我们把这6个10秒成为“窗口”。
那么每过10秒,窗口往前滑动一步,数量限制变为新的6个10秒的总和,如图所示:
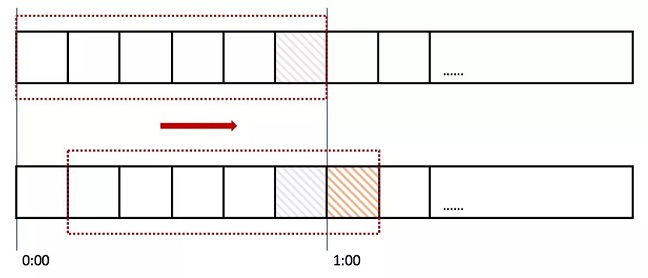
那么如果在临界时,收到10个请求(图中灰色格子),在下一个时间段来临时,橙色部分又进入10个请求,但窗口内包含灰色部分,所以已经到达请求上线,不再接收新的请求。
这就是**“滑动窗口”**算法。
Pros and Cons
Pros
-
It smooths out spikes in traffic because the rate is based on the average rate of the previous window.
-
Memory efficient.
Cons
- It only works for not-so-strict look back window. It is an approximation of the actual rate because it assumes requests in the previous window are evenly distributed. However, this problem may not be as bad as it seems. According to experiments done by Cloudflare, only 0.003% of requests are wrongly allowed or rate limited among 400 million requests.
Sliding Window Log
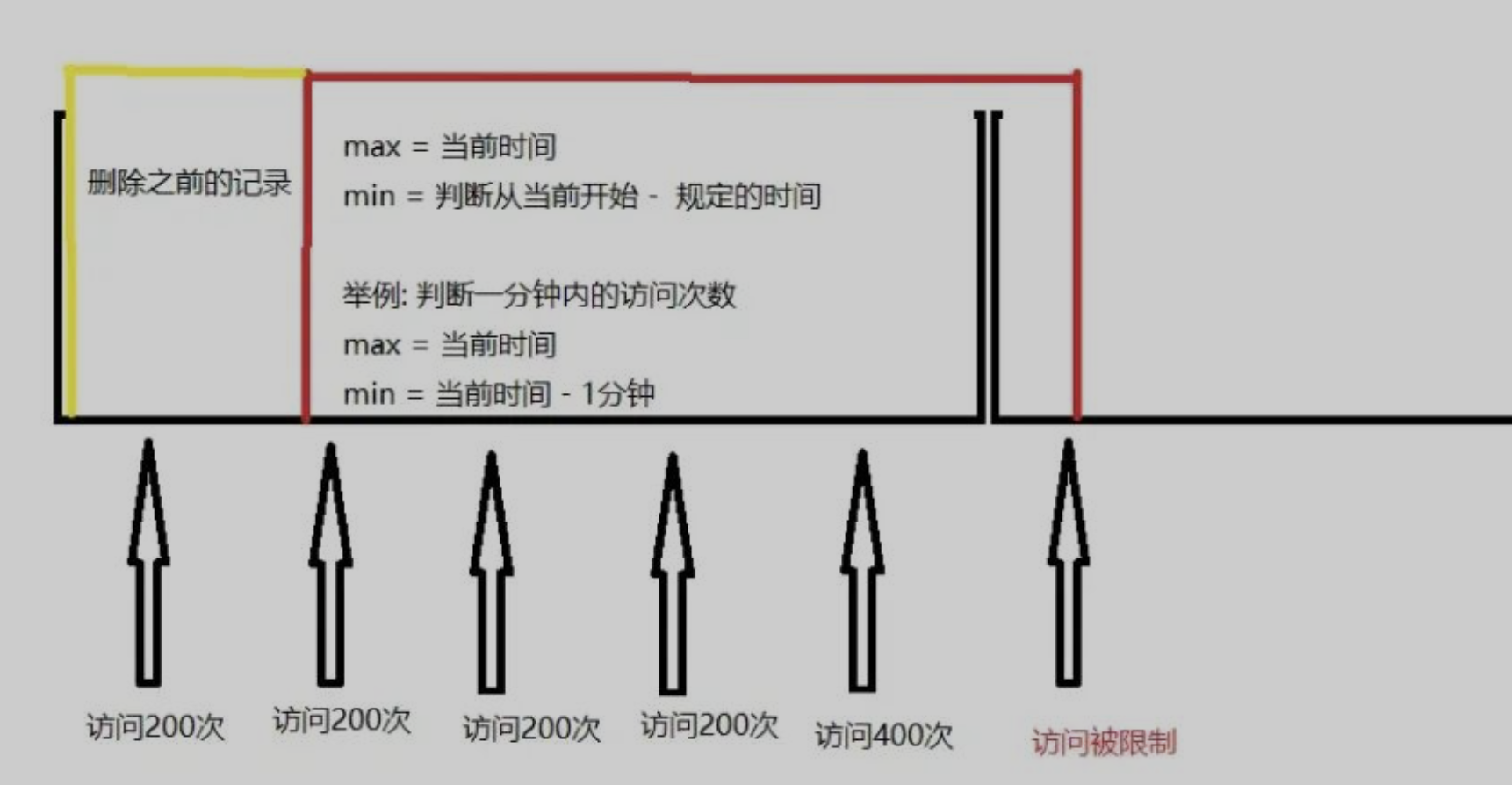
As discussed previously, the fixed window counter algorithm has a major issue: it allows more requests to go through at the edges of a window. The sliding window log algorithm fixes the issue. It works as follows:
- The algorithm keeps track of request timestamps. Timestamp data is usually kept in cache, such as sorted sets of Redis.
- When a new request comes in, remove all the outdated timestamps. Outdated timestamps are defined as those older than the start of the current time window.
- Add timestamp of the new request to the log.
- If the log size is the same or lower than the allowed count, a request is accepted. Otherwise, it is rejected.
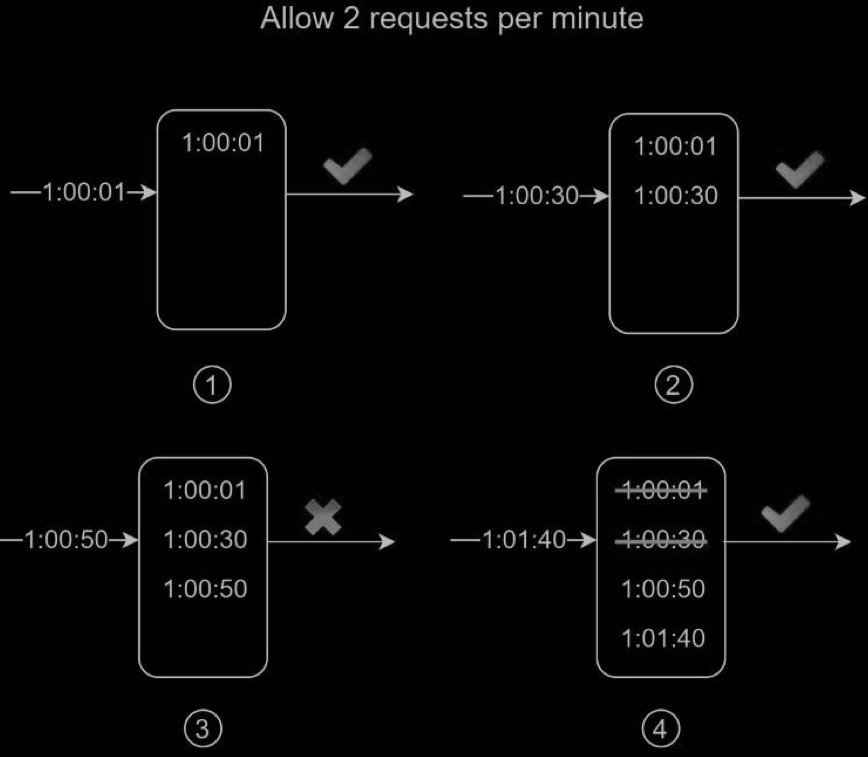
In this example, the rate limiter allows 2 requests per minute. Usually, Linux timestamps are stored in the log. However, human-readable representation of time is used in our example for better readability.
- The log is empty when a new request arrives at 1:00:01. Thus, the request is allowed.
- A new request arrives at 1:00:30, the timestamp 1:00:30 is inserted into the log. After the insertion, the log size is 2, not larger than the allowed count. Thus, the request is allowed.
- A new request arrives at 1:00:50, and the timestamp is inserted into the log. After the insertion, the log size is 3, larger than the allowed size 2. Therefore, this request is rejected even though the timestamp remains in the log.
- A new request arrives at 1:01:40. Requests in the range [1:00:40,1:01:40) are within the latest time frame, but requests sent before 1:00:40 are outdated. Two outdated timestamps, 1:00:01 and 1:00:30, are removed from the log. After the remove operation, the log size becomes 2; therefore, the request is accepted.
Pros and Cons
Pros:
- Rate limiting implemented by this algorithm is very accurate. In any rolling window, requests will not exceed the rate limit.
Cons: - The algorithm consumes a lot of memory because even if a request is rejected, its timestamp might still be stored in memory.
Implementation
Redis - Zset
Python
import time
from collections import deque
class SlidingWindowRateLimiter:
def __init__(self, max_requests: int, window_seconds: int):
self.max_requests = max_requests
self.window = window_seconds
self.timestamps = deque()
def allow_request(self) -> bool:
current_time = time.time()
# Step 1: 清除窗口外的旧请求
while self.timestamps and self.timestamps[0] <= current_time - self.window:
self.timestamps.popleft()
# Step 2: 判断是否超过限流
if len(self.timestamps) < self.max_requests:
self.timestamps.append(current_time)
return True
else:
return False
# 🧪 测试
limiter = SlidingWindowRateLimiter(max_requests=5, window_seconds=10)
for i in range(10):
if limiter.allow_request():
print(f"[{i}] Allowed ✅")
else:
print(f"[{i}] Rejected ❌")
time.sleep(1)
High-level architecture
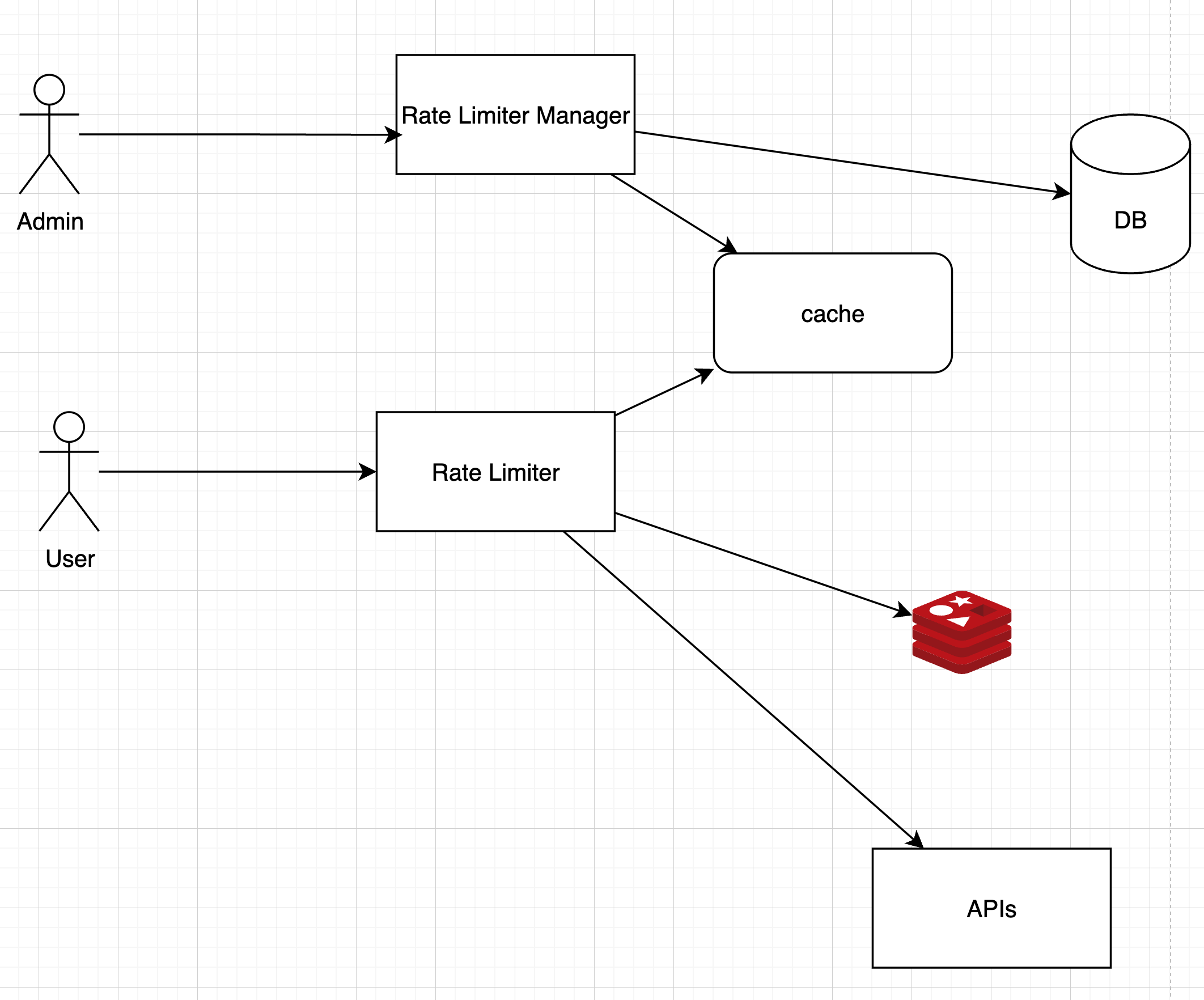
Where shall we store counters? Using the database is not a good idea due to slowness of disk access. In-memory cache is chosen because it is fast and supports time-based expiration strategy. For instance, Redis is a popular option to implement rate limiting. It is an in-memory store that offers two commands: INCR and EXPIRE.
- INCR: It increases the stored counter by 1.
- EXPIRE: It sets a timeout for the counter. If the timeout expires, the counter is automatically deleted.
- The client sends a request to rate limiting middleware.
- Rate limiting middleware fetches the counter from the corresponding bucket in Redis and checks if the limit is reached or not.
- If the limit is reached, the request is rejected.
- If the limit is not reached, the request is sent to API servers. Meanwhile, the system increments the counter and saves it back to Redis.
Deep Dive
Detailed Design
Rate Limiting Rules
- id
- entity
- duration
- limit
Race condition
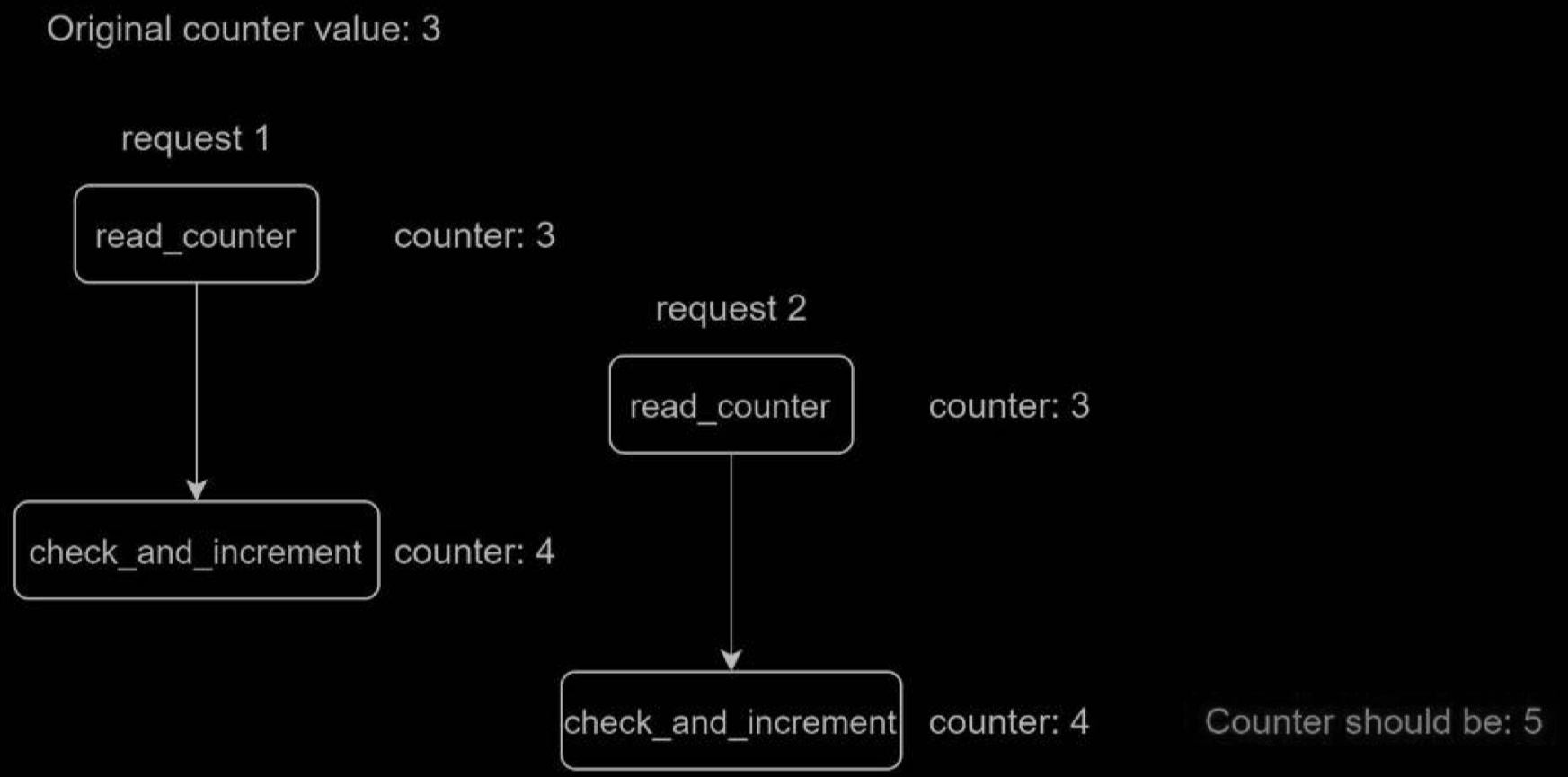
As discussed earlier, rate limiter works as follows at the high-level:
- Read the counter value from Redis.
- Check if ( counter + 1 ) exceeds the threshold.
- If not, increment the counter value by 1 in Redis.
Race conditions can happen in a highly concurrent environment as shown below:
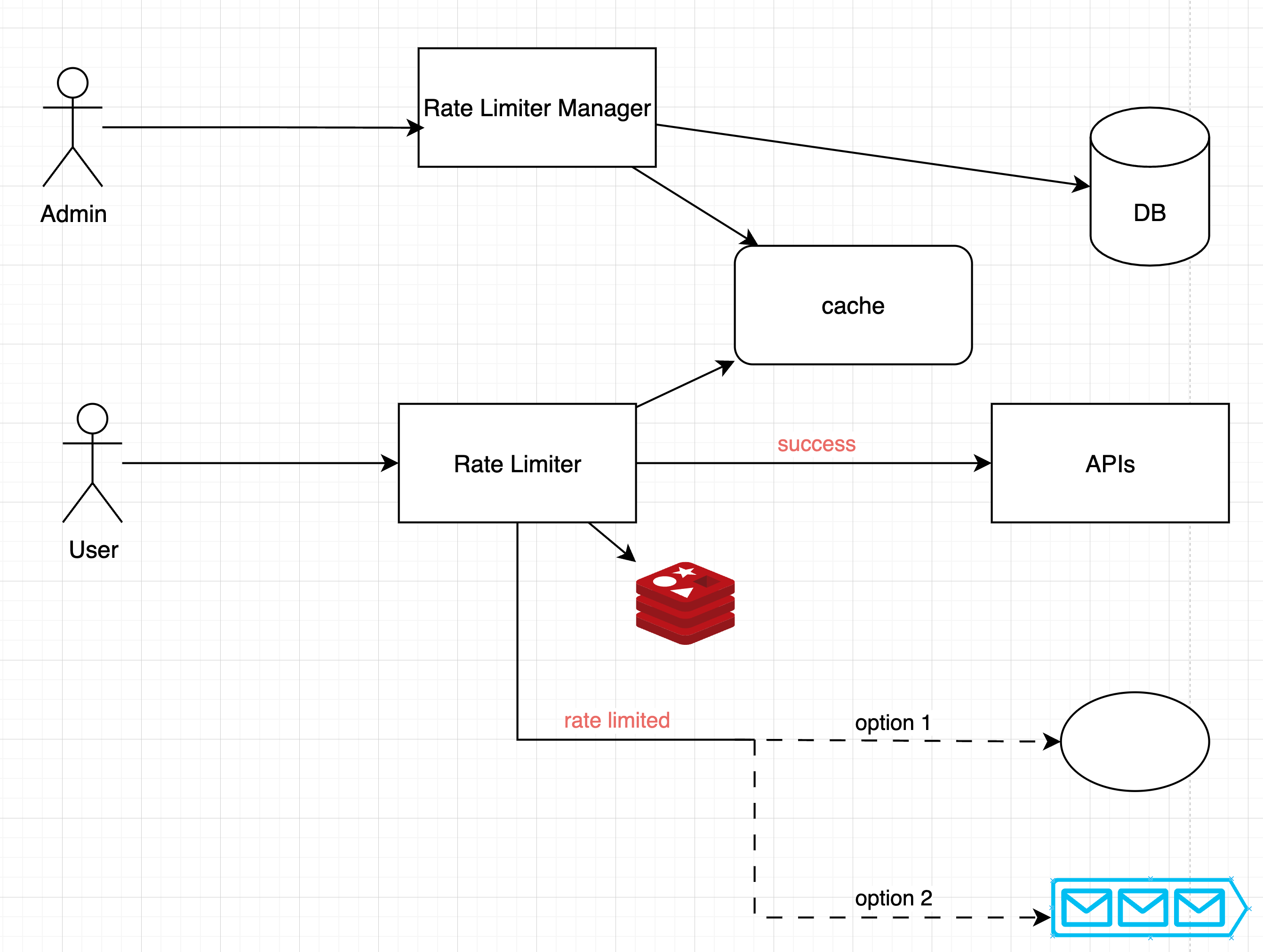
Locks are the most obvious solution for solving race condition. However, locks will significantly slow down the system.
Two strategies are commonly used to solve the problem: Lua script and sorted sets data structure in Redis.
Synchronization issue
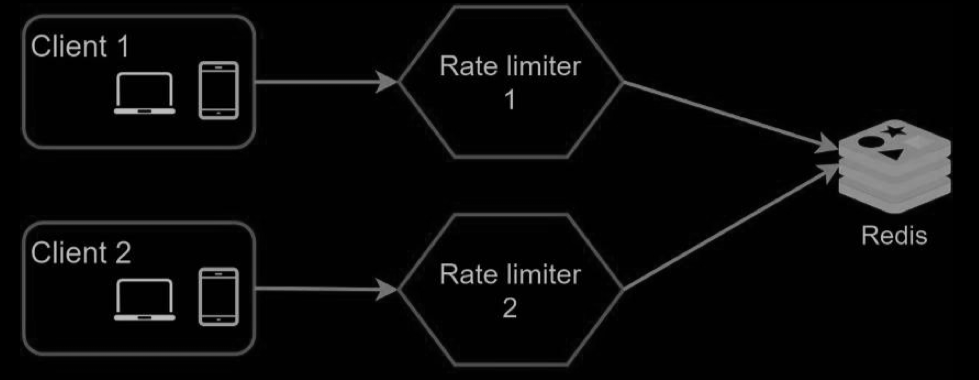
As the web tier is stateless, clients can send requests to a different rate limiter as shown below If no synchronization happens, rate limiter 1 does not contain any data about client 2. Thus, the rate limiter cannot work properly.
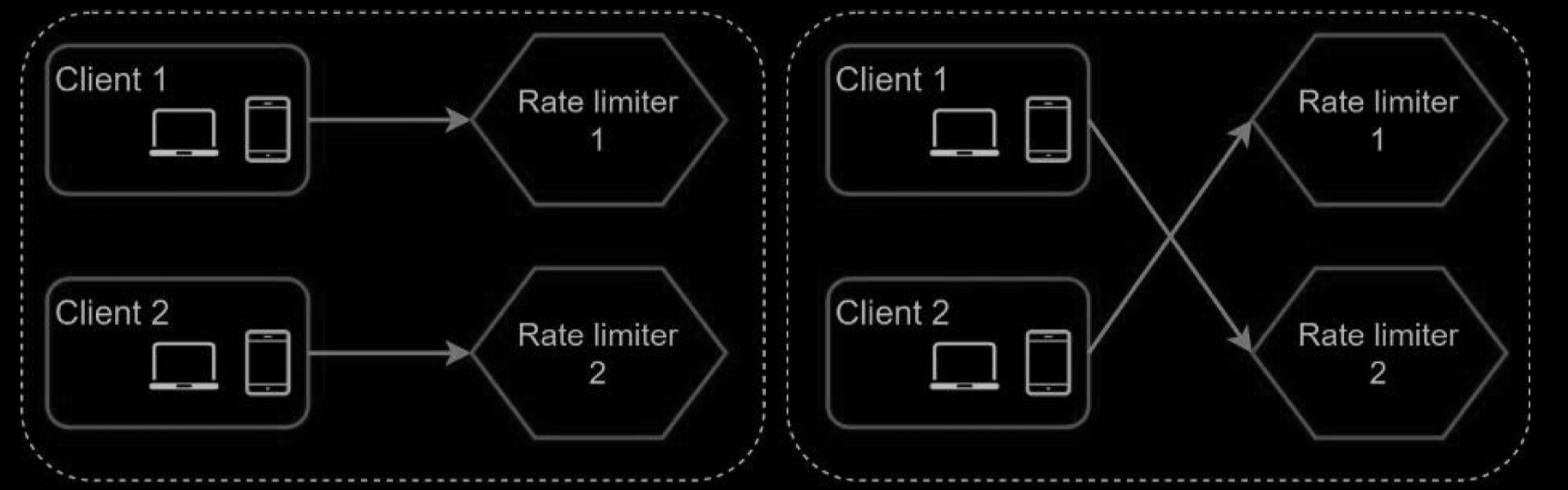
One possible solution is to use sticky sessions that allow a client to send traffic to the same rate limiter. This solution is not advisable because it is neither scalable nor flexible. A better approach is to use centralized data stores like Redis. The design is shown below.
Performance optimization
First, multi-data center setup is crucial for a rate limiter because latency is high for users located far away from the data center. Most cloud service providers build many edge server locations around the world. For example, as of 5/20 2020, Cloudflare has 194 geographically distributed edge servers. Traffic is automatically routed to the closest edge server to reduce latency.
Monitoring
After the rate limiter is put in place, it is important to gather analytics data to check whether the rate limiter is effective. Primarily, we want to make sure:
- The rate limiting algorithm is effective.
- The rate limiting rules are effective.
For example, if rate limiting rules are too strict, many valid requests are dropped. In this case, we want to relax the rules a little bit. In another example, we notice our rate limiter becomes ineffective when there is a sudden increase in traffic like flash sales. In this scenario, we may replace the algorithm to support burst traffic. Token bucket is a good fit here.
Consideration
-
限流级别
-
整个服务
-
distributed rate limit
-
by API
- distributed rate limit
-
-
一个容器
-
单个容器 + 单个 API
-
Customised Level, e.g., API + user_id
-
Extension
分布式限流器
- 集中式限流:所有请求都通过一个中心点进行限流,这个中心点跟踪并控制整个系统的流量。虽然这种方法简单,但可能成为性能瓶颈和单点故障。
- 分布式协调限流:使用分布式协调系统(如ZooKeeper或etcd)来同步不同节点上的限流策略。这种方法可以减轻单点故障的风险,但可能会增加网络通信开销。
开源
最著名的应该就是Hystrix,还有一个轻量级的resilience4j,还有个人开发者弄的SnowJena。
Reference
- System Design Interview – An insider’s guide