Basic Knowledge
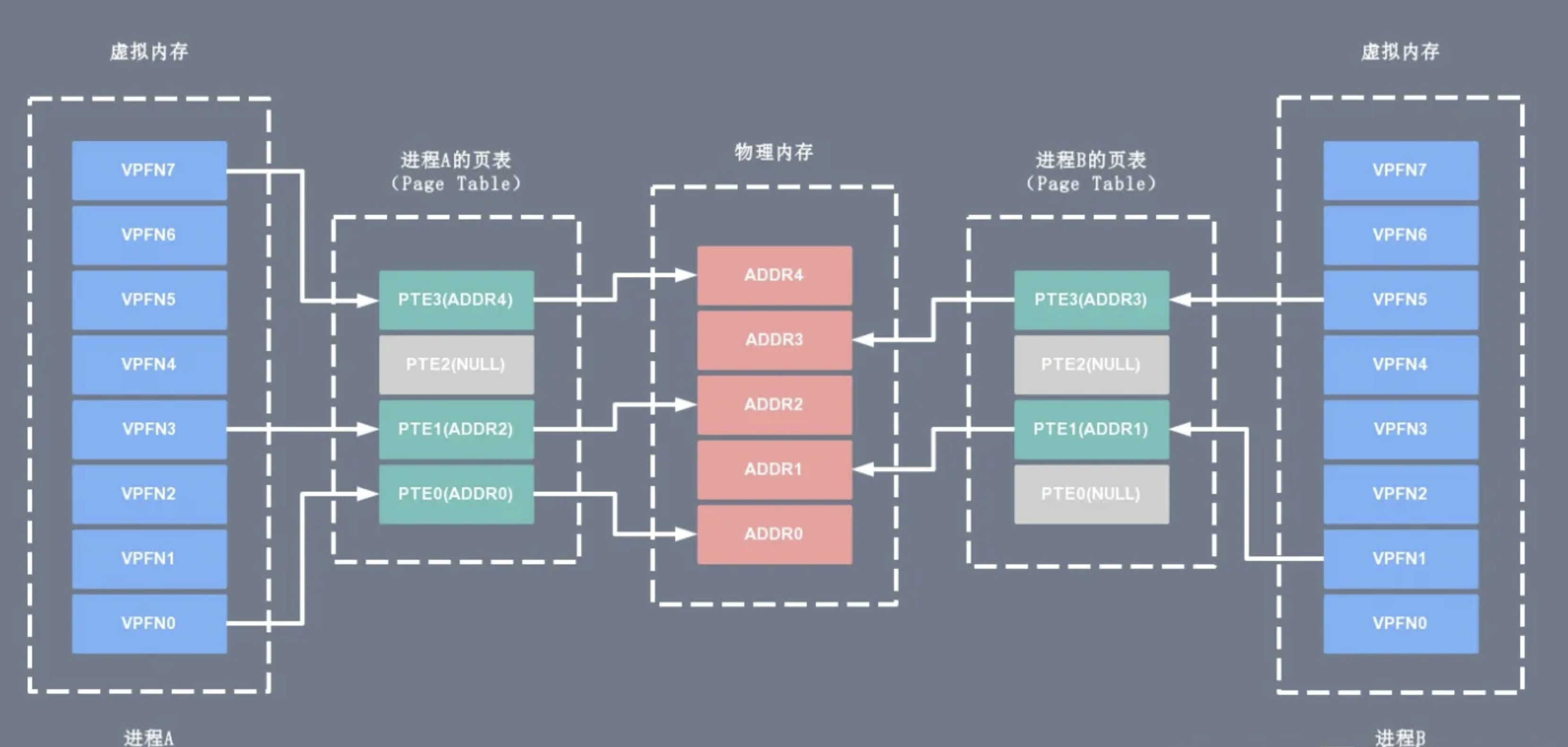
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的权限。为了避免用户进程直接操作内核,保证内核安全,操作系统将虚拟内存划分为两部分,一部分是内核空间(Kernel-space),一部分是用户空间(User-space)。 在 Linux 系统中,内核模块运行在内核空间,对应的进程处于内核态;而用户程序运行在用户空间,对应的进程处于用户态。
内核进程和用户进程所占的虚拟内存比例是 1:3,而 Linux x86_32 系统的寻址空间(虚拟存储空间)为 4G(2的32次方),将最高的 1G 的字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF)供内核进程使用,称为内核空间;而较低的 3G 的字节(从虚拟地址 0x00000000 到 0xBFFFFFFF),供各个用户进程使用,称为用户空间。下图是一个进程的用户空间和内核空间的内存布局(memory layout):
Linux I/O读写方式
Linux 提供了轮询、I/O 中断以及 DMA 传输这 3 种磁盘与主存之间的数据传输机制。其中轮询方式是基于死循环对 I/O 端口进行不断检测。I/O 中断方式是指当数据到达时,磁盘主动向 CPU 发起中断请求,由 CPU 自身负责数据的传输过程。 DMA 传输则在 I/O 中断的基础上引入了 DMA 磁盘控制器,由 DMA 磁盘控制器负责数据的传输,降低了 I/O 中断操作对 CPU 资源的大量消耗。
I/O中断原理
在 DMA 技术出现之前,应用程序与磁盘之间的 I/O 操作都是通过 CPU 的中断完成的。每次用户进程读取磁盘数据时,都需要 CPU 中断,然后发起 I/O 请求等待数据读取和拷贝完成,每次的 I/O 中断都导致 CPU 的上下文切换。
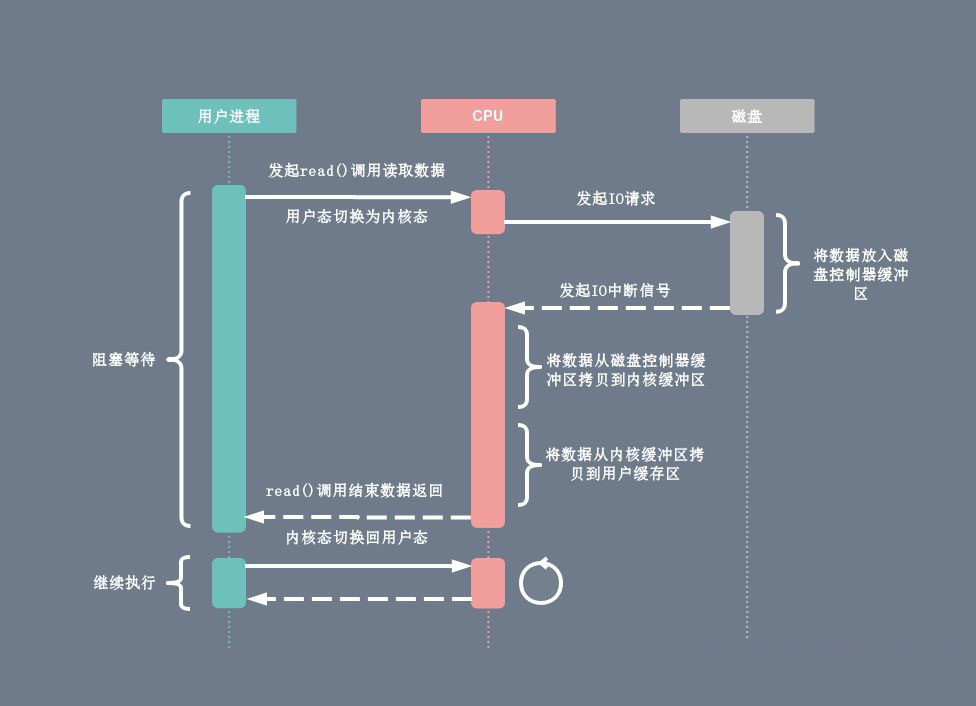
- 用户进程向 CPU 发起 read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回。
- CPU 在接收到指令以后对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区。
- 数据准备完成以后,磁盘向 CPU 发起 I/O 中断。
- CPU 收到 I/O 中断以后将磁盘缓冲区中的数据拷贝到内核缓冲区,然后再从内核缓冲区拷贝到用户缓冲区。
- 用户进程由内核态切换回用户态,解除阻塞状态,然后等待 CPU 的下一个执行时间钟。
DMA (Direct Memory Access)传输原理
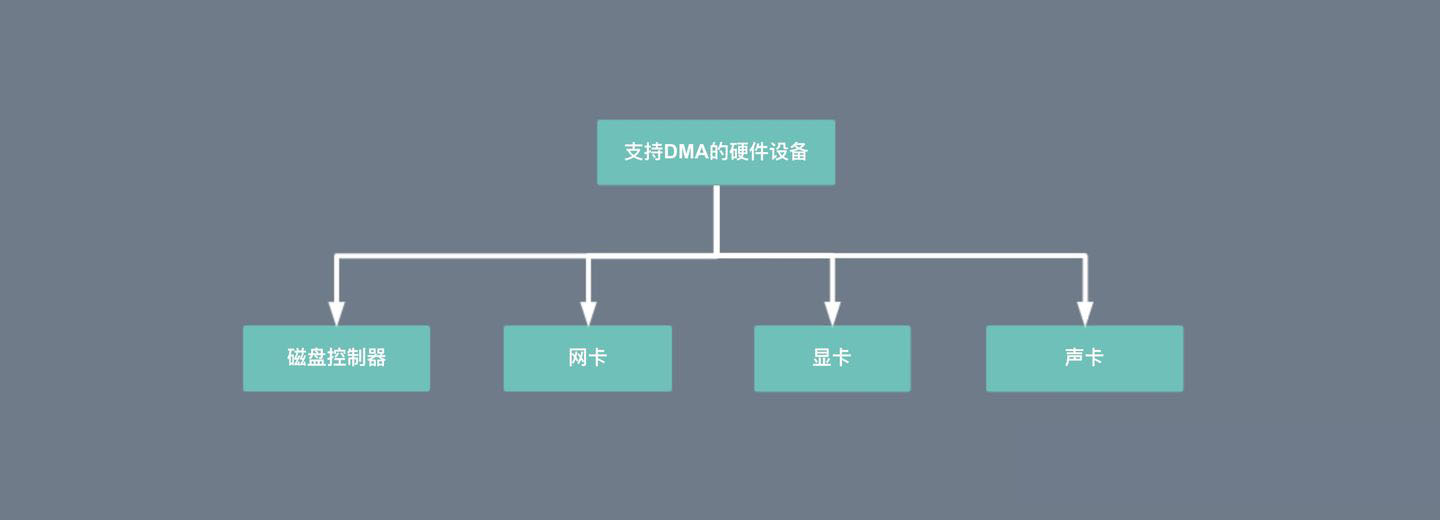
DMA 的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制。也就是说,基于 DMA 访问方式,系统主内存与硬盘或网卡之间的数据传输可以绕开 CPU 的全程调度。目前大多数的硬件设备,包括磁盘控制器、网卡、显卡以及声卡等都支持 DMA 技术。
整个数据传输操作在一个 DMA 控制器的控制下进行的。CPU 除了在数据传输开始和结束时做一点处理外(开始和结束时候要做中断处理),在传输过程中 CPU 可以继续进行其他的工作。这样在大部分时间里,CPU 计算和 I/O 操作都处于并行操作,使整个计算机系统的效率大大提高。
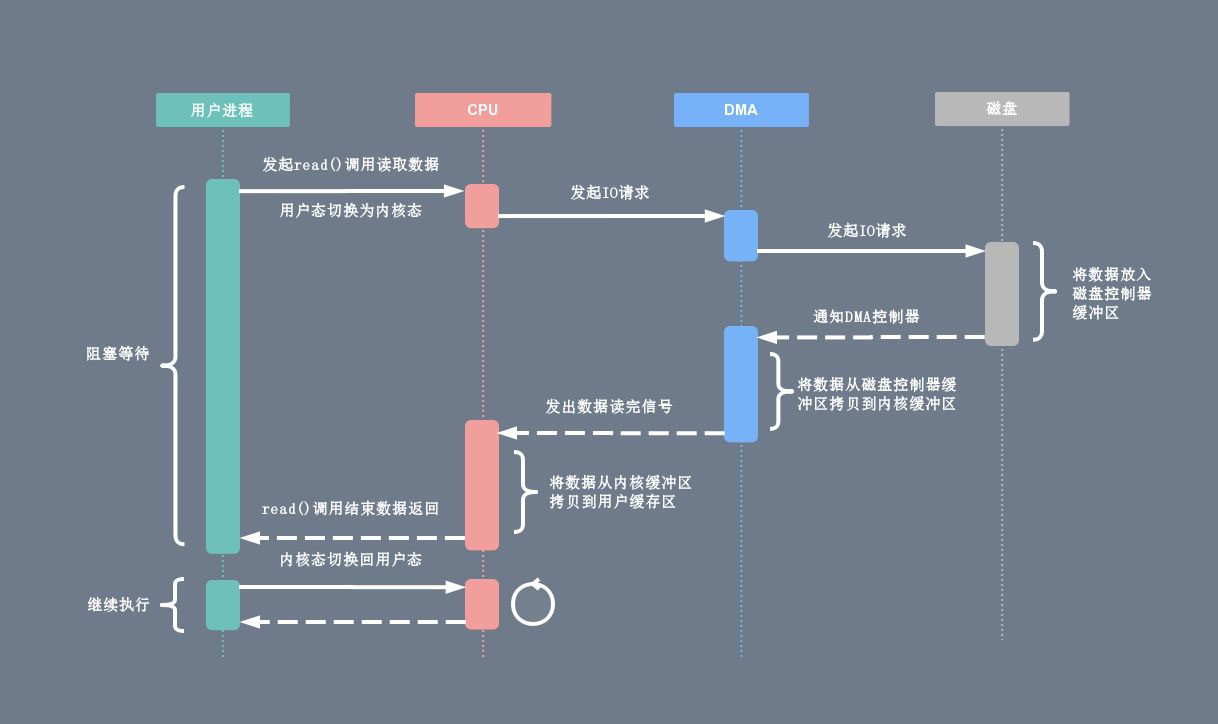
有了 DMA 磁盘控制器接管数据读写请求以后,CPU 从繁重的 I/O 操作中解脱,数据读取操作的流程如下:
- 用户进程向 CPU 发起 read 系统调用读取数据,由用户态切换为内核态,然后一直阻塞等待数据的返回。
- CPU 在接收到指令以后对 DMA 磁盘控制器发起调度指令。
- DMA 磁盘控制器对磁盘发起 I/O 请求,将磁盘数据先放入磁盘控制器缓冲区,CPU 全程不参与此过程。
- 数据读取完成后,DMA 磁盘控制器会接受到磁盘的通知,将数据从磁盘控制器缓冲区拷贝到内核缓冲区。
- DMA 磁盘控制器向 CPU 发出数据读完的信号,由 CPU 负责将数据从内核缓冲区拷贝到用户缓冲区。
- 用户进程由内核态切换回用户态,解除阻塞状态,然后等待 CPU 的下一个执行时间钟。
传统I/O方式
在写一个服务端程序时(Web Server或者文件服务器),文件下载是一个基本功能。这时候服务端的任务是:将服务端主机磁盘中的文件不做修改地从已连接的socket发出去,我们通常用下面的代码完成:
while((n = read(diskfd, buf, BUF_SIZE)) > 0)
write(sockfd, buf , n);
基本操作就是循环的从磁盘读入文件内容到缓冲区,再将缓冲区的内容发送到socket。但是由于Linux的I/O操作默认是缓冲I/O。这里面主要使用的也就是read和write两个系统调用,我们并不知道操作系统在其中做了什么。实际上在以上I/O操作中,发生了多次的数据拷贝。
当应用程序访问某块数据时,操作系统首先会检查,是不是最近访问过此文件,文件内容是否缓存在内核缓冲区,如果是,操作系统则直接根据read系统调用提供的buf地址,将内核缓冲区的内容拷贝到buf所指定的用户空间缓冲区中去。如果不是,操作系统则首先将磁盘上的数据拷贝的内核缓冲区,这一步目前主要依靠DMA来传输,然后再把内核缓冲区上的内容拷贝到用户缓冲区中。
接下来,write系统调用再把用户缓冲区的内容拷贝到网络堆栈相关的内核缓冲区中,最后socket再把内核缓冲区的内容发送到网卡上。
说了这么多,不如看图清楚:
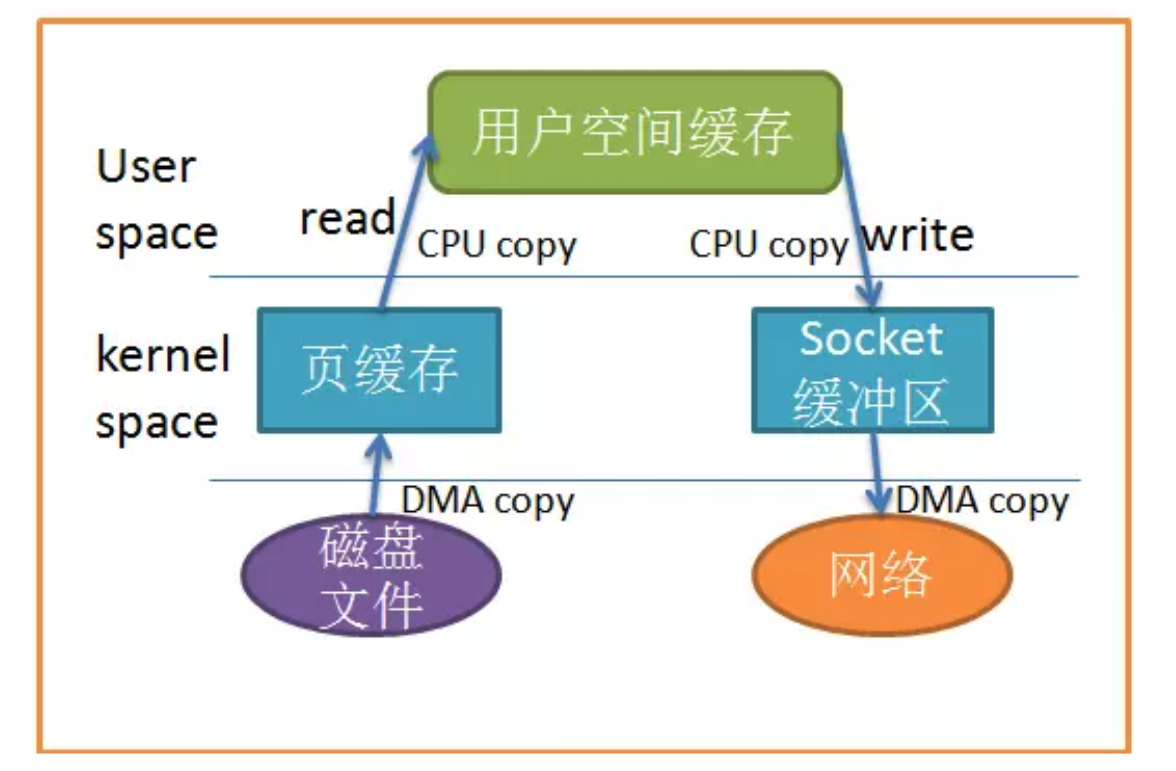
从上图中可以看出,共产生了四次数据拷贝,即使使用了 DMA 来处理了与硬件的通讯,CPU仍然需要处理两次数据拷贝,与此同时,在用户态与内核态也发生了多次上下文切换,无疑也加重了CPU负担。
在此过程中,我们没有对文件内容做任何修改,那么在内核空间和用户空间来回拷贝数据无疑就是一种浪费,而零拷贝主要就是为了解决这种低效性。
传统读操作
当应用程序执行 read 系统调用读取一块数据的时候,如果这块数据已经存在于用户进程的页内存中,就直接从内存中读取数据;如果数据不存在,则先将数据从磁盘加载数据到内核空间的读缓存(read buffer)中,再从读缓存拷贝到用户进程的页内存中。
read(file_fd, tmp_buf, len);
基于传统的 I/O 读取方式,read 系统调用会触发 2 次上下文切换,1 次 DMA 拷贝和 1 次 CPU 拷贝,发起数据读取的流程如下:
- 用户进程通过
read()函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。 - CPU利用DMA控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer),即 page cache。
- CPU将读缓冲区(read buffer)中的数据拷贝到用户空间(user space)的用户缓冲区(user buffer)。
- 上下文从内核态(kernel space)切换回用户态(user space),read 调用执行返回。
传统写操作
当应用程序准备好数据,执行 write 系统调用发送网络数据时,先将数据从用户空间的 PageCache 拷贝到内核空间的网络缓冲区(socket buffer)中,然后再将写缓存中的数据拷贝到网卡设备完成数据发送。
write(socket_fd, tmp_buf, len);
基于传统的 I/O 写入方式,write() 系统调用会触发 2 次上下文切换,1 次 CPU 拷贝和 1 次 DMA 拷贝。
用户程序发送网络数据的流程如下:
- 用户进程通过
write()函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。 - CPU 将用户缓冲区(user buffer)中的数据拷贝到内核空间(kernel space)的网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),
write()系统调用执行返回。
零拷贝(Zero-copy)
零拷贝主要的任务就是避免CPU将数据从一块存储拷贝到另外一块存储,主要就是利用各种零拷贝技术,避免让CPU做大量的数据拷贝任务,减少不必要的拷贝,或者让别的组件来做这一类简单的数据传输任务,让CPU解脱出来专注于别的任务。这样就可以让系统资源的利用更加有效。
我们继续回到下载的例子,我们如何减少数据拷贝的次数呢?一个很明显的着力点就是减少数据在内核空间和用户空间之间的来回拷贝。
mmap + write
我们减少拷贝次数的一种方法是调用 mmap()来代替 read() 调用:
buf = mmap(diskfd, len);
write(sockfd, buf, len);
-
应用程序调用
mmap(),磁盘上的数据会通过DMA被拷贝到内核缓冲区,当拷贝完成,mmap系统调用就返回了- 在这个过程中,操作系统会将用户空间的虚拟地址和内核空间的虚拟地址映射成同一个物理地址这样可以减少内核空间和内核空间的数据拷贝。
-
应用程序再调用
write(),操作系统直接将内核缓冲区的内容拷贝到socket缓冲区中,这一切都发生在内核态 -
最后,DMA将数据从
socket缓冲区发到网卡。
同样的,看图很简单:
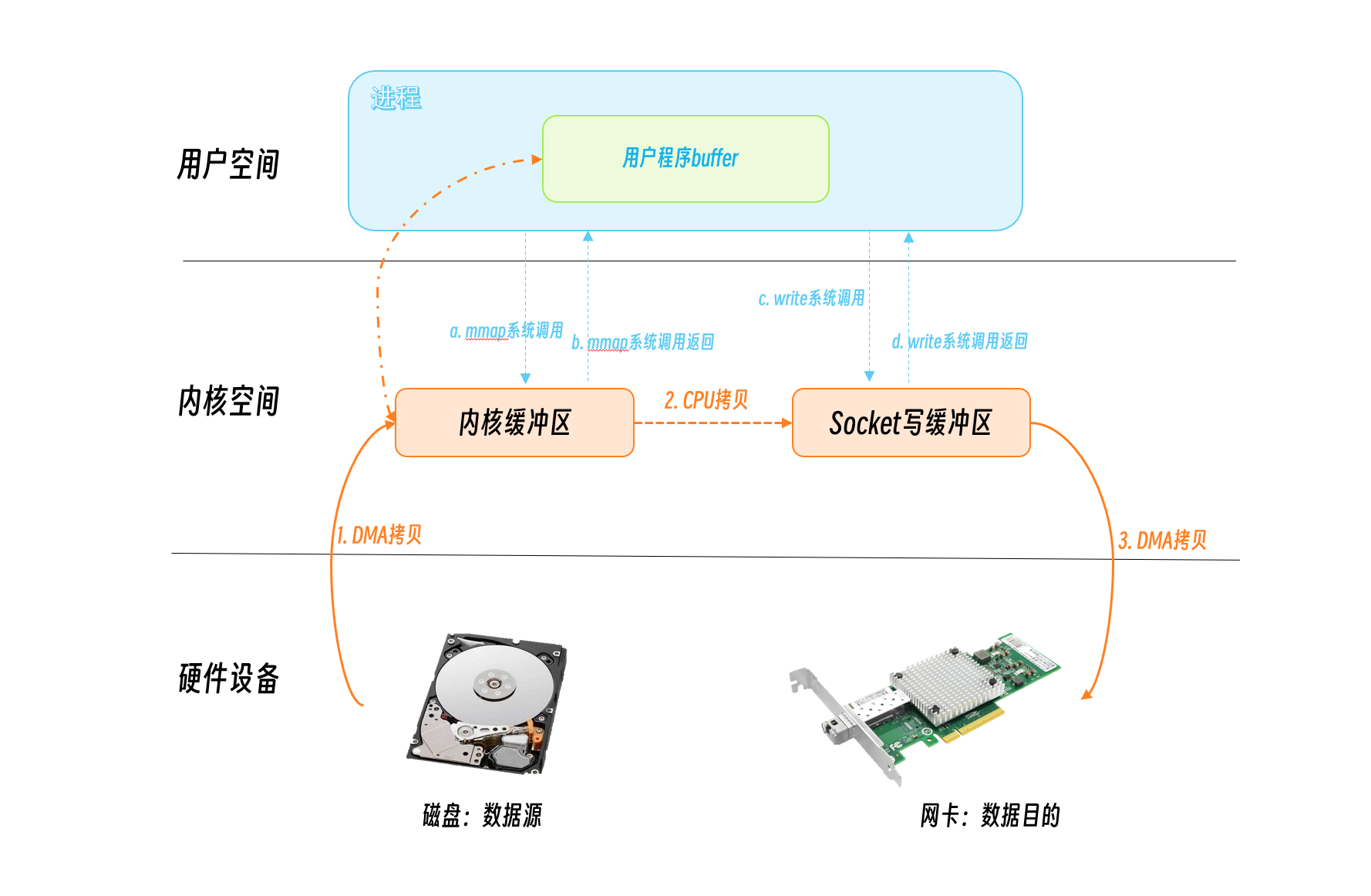
可以看到,mmap+write方式有两次系统调用,发生四次用户态/内核态的切换,三次数据拷贝。
相对传统的IO方式,减少了一次数据拷贝,但是应该还有优化的空间。
使用mmap替代read很明显减少了一次拷贝,当拷贝数据量很大时,无疑提升了效率。但是使用mmap是有代价的。当你使用mmap时,你可能会遇到一些隐藏的陷阱。例如,当你的程序mmap了一个文件,但是当这个文件被另一个进程截断(truncate)时,write() 系统调用会因为访问非法地址而被SIGBUS信号终止。SIGBUS信号默认会杀死你的进程并产生一个coredump,如果你的服务器这样被中止了,那会产生一笔损失。
通常我们使用以下解决方案避免这种问题:
- 为SIGBUS信号建立信号处理程序
- 当遇到
SIGBUS信号时,信号处理程序简单地返回,write系统调用在被中断之前会返回已经写入的字节数,并且errno会被设置成success,但是这是一种糟糕的处理办法,因为你并没有解决问题的实质核心。
- 当遇到
- 使用文件租借锁
- 通常我们使用这种方法,在文件描述符上使用租借锁,我们为文件向内核申请一个租借锁,当其它进程想要截断这个文件时,内核会向我们发送一个实时的
RT_SIGNAL_LEASE信号,告诉我们内核正在破坏你加持在文件上的读写锁。这样在程序访问非法内存并且被SIGBUS杀死之前,你的write系统调用会被中断。write会返回已经写入的字节数,并且置errno为success。
- 通常我们使用这种方法,在文件描述符上使用租借锁,我们为文件向内核申请一个租借锁,当其它进程想要截断这个文件时,内核会向我们发送一个实时的
我们应该在mmap文件之前加锁,并且在操作完文件后解锁:
if(fcntl(diskfd, F_SETSIG, RT_SIGNAL_LEASE) == -1) {
perror("kernel lease set signal");
return -1;
}
/* l_type can be F_RDLCK F_WRLCK 加锁*/
/* l_type can be F_UNLCK 解锁*/
if(fcntl(diskfd, F_SETLEASE, l_type)){
perror("kernel lease set type");
return -1;
}
sendfile
从2.1版内核开始,Linux引入了sendfile来简化操作:
#include<sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
系统调用sendfile()在代表输入文件的描述符in_fd和代表输出文件的描述符out_fd之间传送字节。
但是源文件描述符(in_fd)要求必须是支持mmap操作的文件描述符,普通的文件可以,但是socket就不行了。所以sendfile适合从文件读取数据写socket场景,所以sendfile这个名字还是很贴切的,发送文件。
用户调用sendfile系统调用,数据通过DMA拷贝到内核缓冲区,CPU将数据从内核缓冲区再写入到socket缓冲区,DMA将socket缓冲区数据写入到网卡,然后sendfile系统调用返回。
可以看到,这里只有一次系统调用,也就是两次用户态/内核态的切换,三次数据拷贝。
相对来说,这种方式对性能已经有所提升。
如下图:
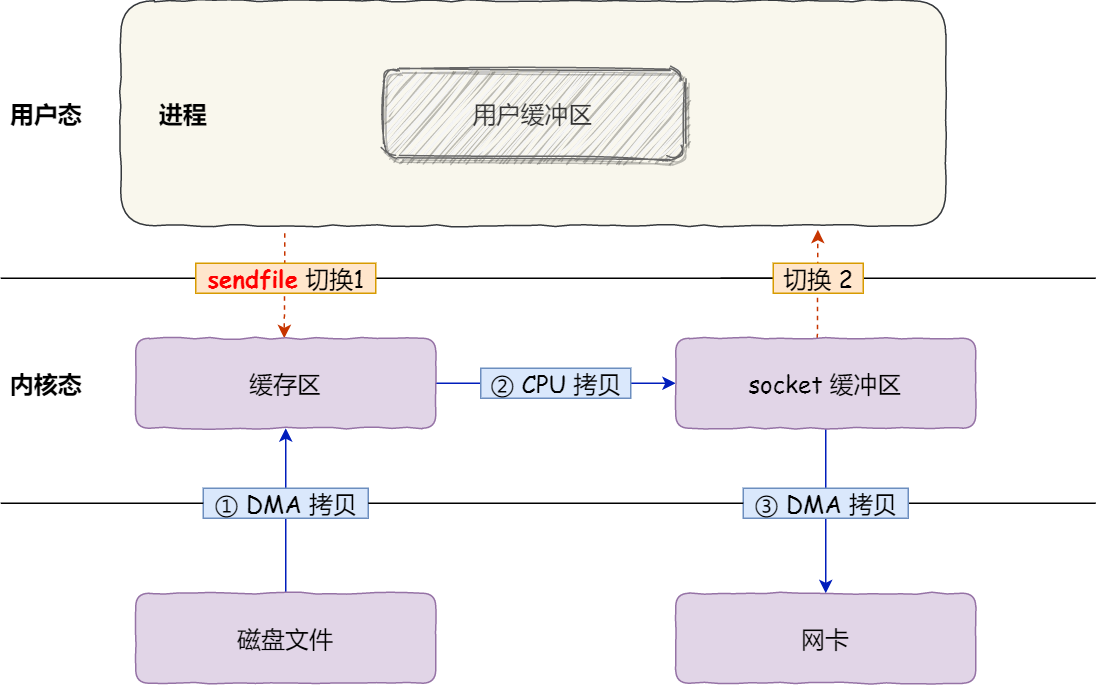
在我们调用sendfile时,如果有其它进程截断了文件会发生什么呢?假设我们没有设置任何信号处理程序,sendfile调用仅仅返回它在被中断之前已经传输的字节数,errno会被置为success。如果我们在调用sendfile之前给文件加了锁,sendfile的行为仍然和之前相同,我们还会收到RT_SIGNAL_LEASE的信号。
sendfile + DMA gather copy
目前为止,我们已经减少了数据拷贝的次数了,但是仍然存在一次拷贝,就是内核缓存区到socket缓存的拷贝。那么能不能把这个拷贝也省略呢?
如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术(和普通的 DMA 有所不同),我们可以把内核缓冲区里的数据拷贝到网卡的缓冲区。
你可以在你的 Linux 系统通过下面这个命令,查看网卡是否支持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on
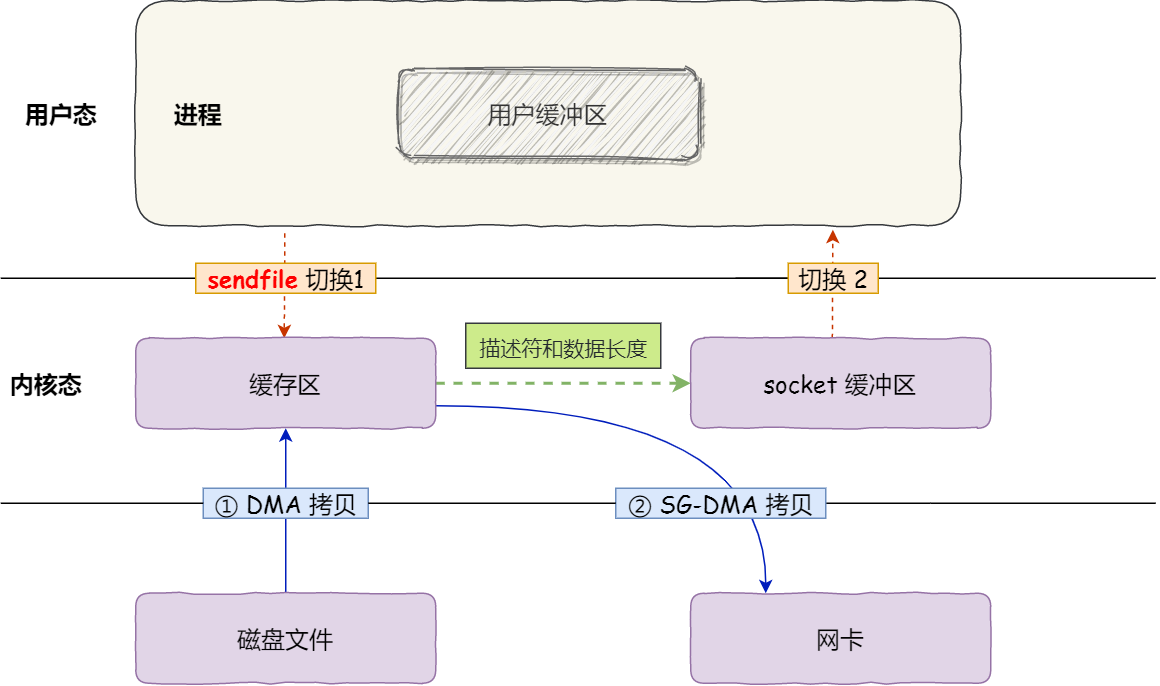
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
splice
sendfile只适用于将数据从文件拷贝到套接字上,限定了它的使用范围。比如我们想做一个socket proxy,源和目的都是socket,就不能直接使用sendfile了。
Linux在2.6.17版本引入splice系统调用,用于在两个文件描述符中移动数据:
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <fcntl.h>
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
splice调用在两个文件描述符之间移动数据,而不需要数据在内核空间和用户空间来回拷贝。
fd_in 和 fd_out 也是分别代表了输入端和输出端的文件描述符,这两个文件描述符必须有一个是指向管道设备的,这算是一个不太友好的限制。 off_in 和 off_out 则分别是 fd_in 和 fd_out 的偏移量指针,指示内核从哪里读取和写入数据,len 则指示了此次调用希望传输的字节数,最后的 flags 是系统调用的标记选项位掩码,用来设置系统调用的行为属性的,由以下 0 个或者多个值通过『或』操作组合而成:
- SPLICE_F_MOVE :尝试去移动数据而不是拷贝数据。这仅仅是对内核的一个小提示:如果内核不能从
pipe移动数据或者pipe的缓存不是一个整页面,仍然需要拷贝数据。 - SPLICE_F_NONBLOCK :
splice操作不会被阻塞。然而,如果文件描述符没有被设置为不可被阻塞方式的 I/O ,那么调用 splice 有可能仍然被阻塞。 - SPLICE_F_MORE: 后面的
splice调用会有更多的数据。
splice() 是基于 Linux 的管道缓冲区 (pipe buffer) 机制实现的,所以 splice() 的两个入参文件描述符才要求必须有一个是管道设备,
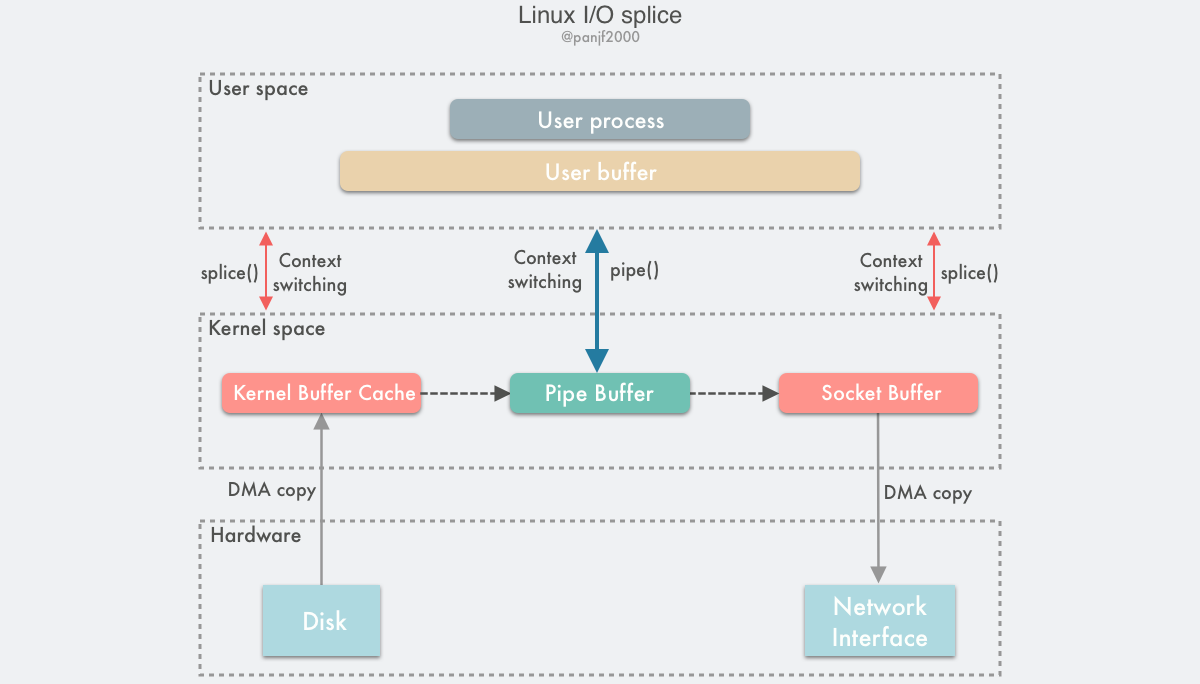
使用 splice() 完成一次磁盘文件到网卡的读写过程如下:
- 用户进程调用 pipe(),从用户态陷入内核态,创建匿名单向管道,pipe() 返回,上下文从内核态切换回用户态;
- 用户进程调用 splice(),从用户态陷入内核态;
- DMA 控制器将数据从硬盘拷贝到内核缓冲区,从管道的写入端"拷贝"进管道,splice() 返回,上下文从内核态回到用户态;
- 用户进程再次调用 splice(),从用户态陷入内核态;
- 内核把数据从管道的读取端"拷贝"到套接字缓冲区,DMA 控制器将数据从套接字缓冲区拷贝到网卡;
- splice() 返回,上下文从内核态切换回用户态。
当然,如果我们处理的源和目的不是管道的话,我们可以先建立一个管道,这样就可以使用splice系统调用来实现零拷贝了。
但是,如果每次都创建一个管道,你会发现每次都会多一次系统调用,也就是两次用户态/内核态的切换,所以你如果频繁的拷贝数据,那么可以建立一个管道池就像潘建给Go的标准库提供的一个补丁一样,利用pipe pool对Go语言中的splice做了优化。
MSG_ZEROCOPY
Linux v4.14 版本接受了在TCP send系统调用中实现的支持零拷贝(MSG_ZEROCOPY)的patch,通过这个patch,用户进程就能够把用户缓冲区的数据通过零拷贝的方式经过内核空间发送到网络套接字中去,在5.0中支持UDP。Willem de Bruijn 在他的论文里给出的压测数据是:采用 netperf 大包发送测试,性能提升 39%,而线上环境的数据发送性能则提升了 5%~8%,官方文档陈述说这个特性通常只在发送 10KB 左右大包的场景下才会有显著的性能提升。一开始这个特性只支持 TCP,到内核 v5.0 版本之后才支持 UDP。这里也有一篇官方文档介绍:Zero-copy networking
首先你需要设置socket选项:
if (setsockopt(fd, SOL_SOCKET, SO_ZEROCOPY, &one, sizeof(one)))
error(1, errno, "setsockopt zerocopy");
然后调用send系统调用是传入MSG_ZEROCOPY参数:
ret = send(fd, buf, sizeof(buf), MSG_ZEROCOPY);
这里我们传入了buf,但是啥时候buf可以重用呢?这个内核会通知程序进程。它将完成通知放在socket error队列中,所以你需要读取这个队列,知道拷贝啥时候完成buf可释放或者重用了:
pfd.fd = fd;
pfd.events = 0;
if (poll(&pfd, 1, -1) != 1 || pfd.revents & POLLERR == 0)
error(1, errno, "poll");
ret = recvmsg(fd, &msg, MSG_ERRQUEUE);
if (ret == -1)
error(1, errno, "recvmsg");
read_notification(msg);
因为它可能异步发送数据,你需要检查buf啥时候释放,增加代码复杂度,以及会导致多次用户态和内核态的上下文切换;
copy_file_range
Linux 4.5 增加了一个新的API: copy_file_range, 它在内核态进行文件的拷贝,不再切换用户空间,所以会比cp少块一些,在一些场景下会提升性能。
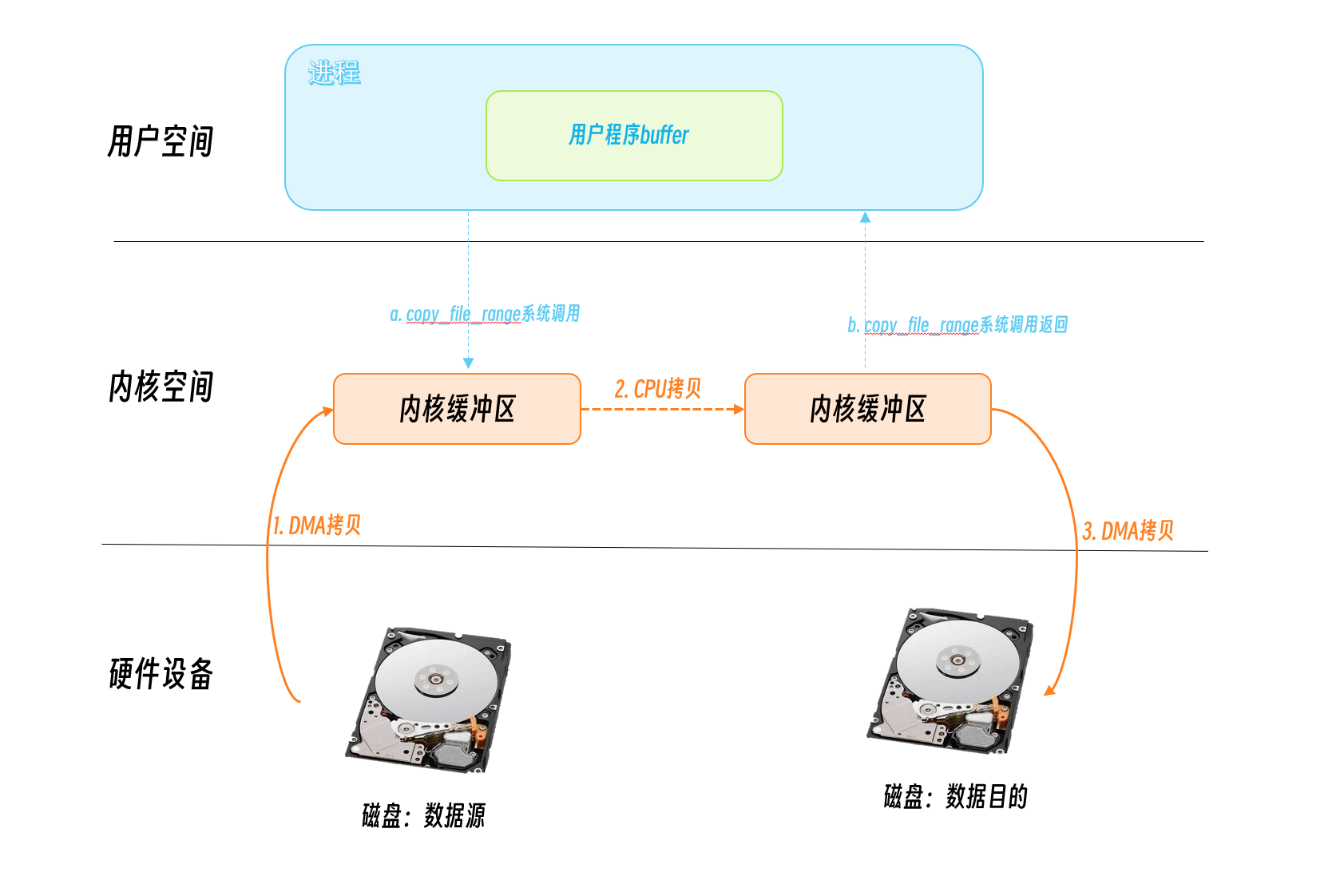
Summary
以上几种零拷贝技术都是减少数据在用户空间和内核空间拷贝技术实现的,但是有些时候,数据必须在用户空间和内核空间之间拷贝。这时候,我们只能针对数据在用户空间和内核空间拷贝的时机上下功夫了。
Linux通常利用**写时复制(copy on write)**来减少系统开销,即多线程对保护对象进行读写操作时,执行写操作的线程在写的之前,会把该对象复制一份(并对复制后的对象实例进行写修改操作),最终就可以做到写操作进行的同时,不阻塞其他线程的读操作。
这是相对于在传统的使用读写锁以保证互斥操作的实现中,通常会在进行写操作时加锁,因而在写线程操作的时候,其他的读线程都必须等待。
写时复制适合读多写少的应用场景,比如白名单,黑名单,商品类目的访问和更新场景,而不适合内存敏感以及对实时性要求很高的场景。
使用零拷贝的例子
事实上,Kafka 这个开源项目,就利用了「零拷贝」技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
如果你追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo 方法:
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
如果 Linux 系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
另外,Nginx 也支持零拷贝技术,一般默认是开启零拷贝技术,这样有利于提高文件传输的效率,是否开启零拷贝技术的配置如下:
http {
...
sendfile on
...
}
sendfile 配置的具体意思:
- 设置为 on 表示,使用零拷贝技术来传输文件:sendfile ,这样只需要 2 次上下文切换,和 2 次数据拷贝。
- 设置为 off 表示,使用传统的文件传输技术:read + write,这时就需要 4 次上下文切换,和 4 次数据拷贝。
Reference
- https://en.wikipedia.org/wiki/Zero-copy
- https://developer.ibm.com/articles/j-zerocopy/
- https://www.cnblogs.com/xiaolincoding/p/13719610.html
- 浅析Linux中的零拷贝技术 - https://www.jianshu.com/p/fad3339e3448
- https://zhuanlan.zhihu.com/p/83398714
- https://colobu.com/2022/11/19/zero-copy-and-how-to-use-it-in-go/