希尔排序(Shell Sort)
希尔排序(Shell Sort),又Shell在1959年发明,是第一个突破$O(n^2)$的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序(diminishing increment sort)。
插入排序(Insertion Sort)的一个重要的特点是,如果原始数据的大部分元素已经排序,那么插入排序的速度很快(因为需要移动的元素很少)。从这个事实我们可以想到,如果原始数据只有很少元素,那么排序的速度也很快。
希尔排序就是基于这两点对插入排序作出了改进。
插入排序与希尔排序
插入排序很循规蹈矩,不管数组分布是怎么样的,依然一步一步的对元素进行比较,移动,插入,比如[5,4,3,2,1,0]这种倒序序列,数组末端的0要回到首位置很是费劲(比较和移动元素均需n-1次)。
而希尔排序在数组中采用跳跃式分组的策略,通过某个增量将数组元素划分为若干组(每组包含数量相同的元素),然后以每个分组作为一个集合单元,并对这个集合单元内的数据元素(每个分组中的数据元素)进行插入排序,随后逐步缩小增量(并得到新的组),继续以组作为一个集合单元,进行插入排序操作,直至增量为1。
希尔排序通过这种策略使得整个数组在初始阶段达到从宏观上看基本有序(即小的基本在前,大的基本在后)。然后逐渐缩小增量,到增量为1时,其实多数情况下只需微调即可,不会涉及过多的数据移动。
希尔排序(Shell Sort)
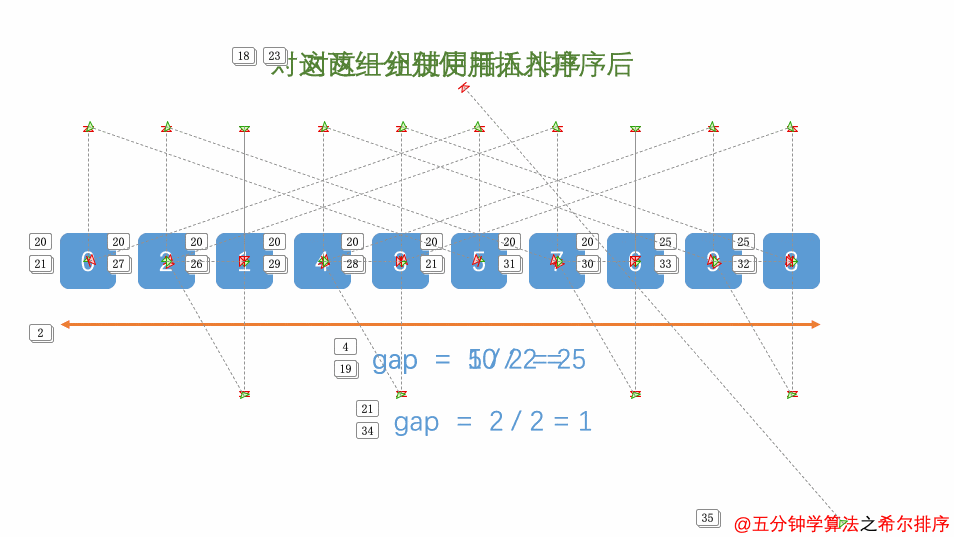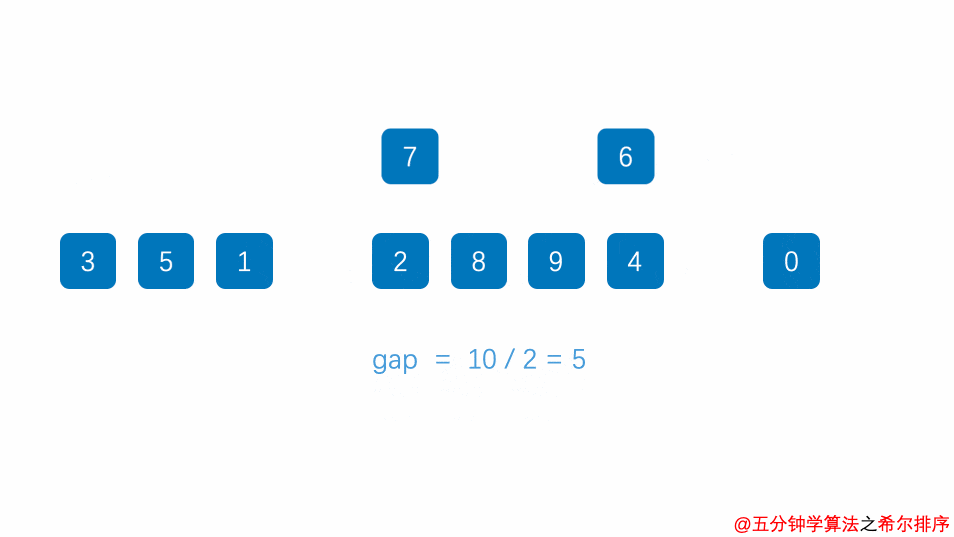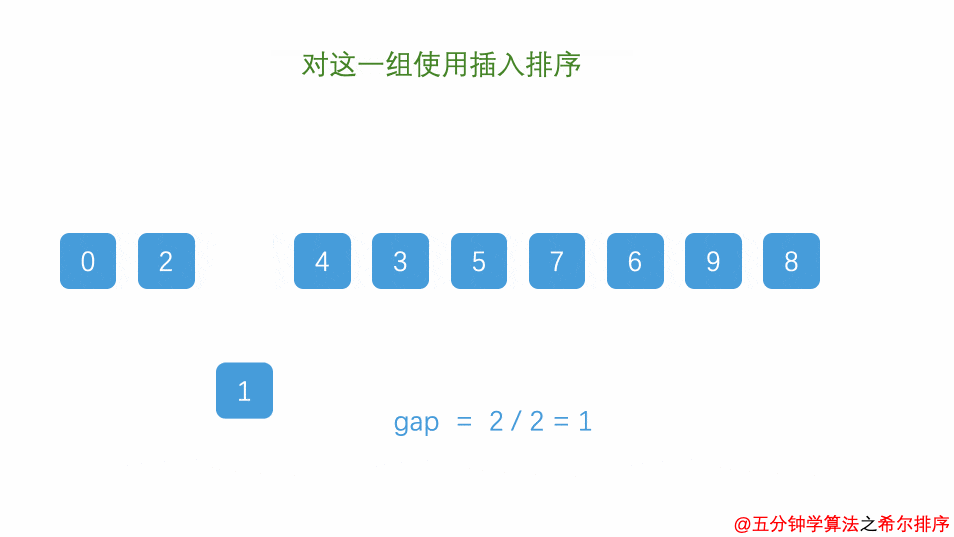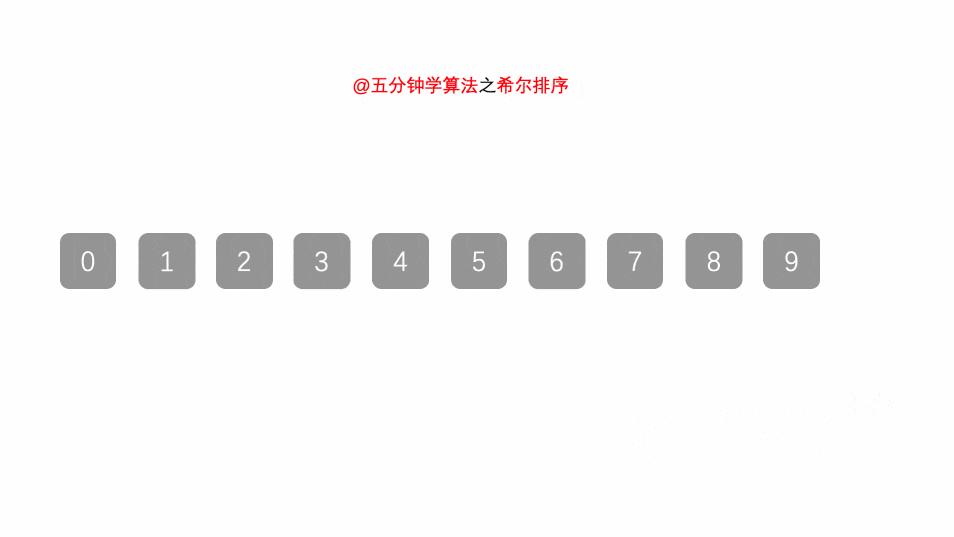
我们来看下希尔排序的基本步骤,在此我们选择增量(gap)等于当前待排序数组的长度的一半(即,gap=length/2),缩小增量继续以gap = gap/2的方式,这种增量选择我们可以用一个序列来表示,{n/2,(n/2)/2…1},称为增量序列。增量值等于一个小组中元素的数量。
希尔排序的增量序列的选择与证明是个数学难题,我们选择的这个增量序列是比较常用的,也是希尔建议的增量,称为希尔增量,但其实这个增量序列不是最优的。
在希尔排序中,首先,把相对较大的待排序的数据集合分割成若干个小组,然后对每一个小组(中的数据)分别进行插入排序,此时,插入排序所作用的数据量比较小(仅作用于一个小组),因此插入的效率比较高。
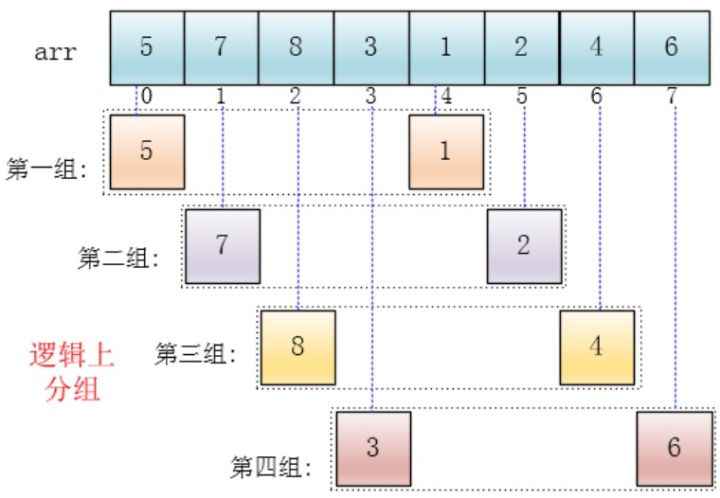
可以看出,上图中,数组的长度为 8,因此在第一轮时,增量为 4(即当前待排序数组的长度的一半)。这意味着,将数组中元素分为 4 组,继而每组包含 2 个元素。
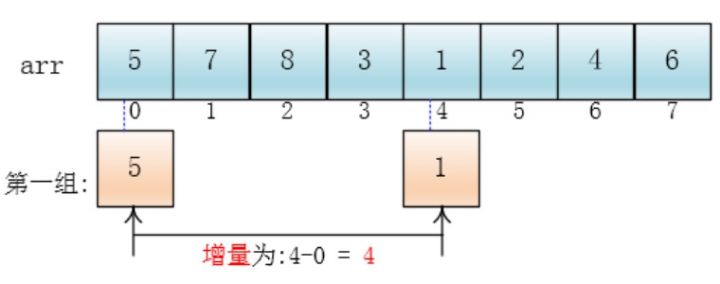
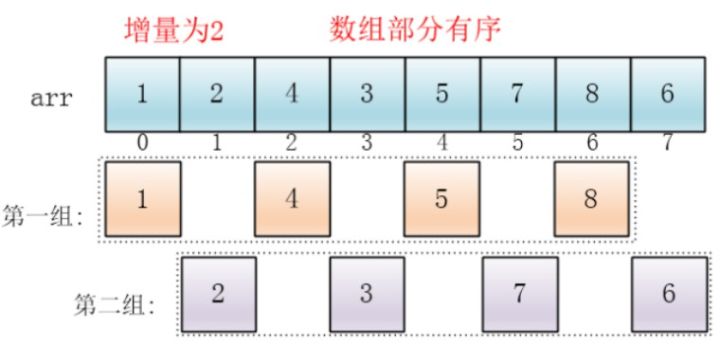
那么,如果将元素归到这 4 组呢?下标相隔 4 的元素互为一组,比如这个例子中a[0]与a[4]是一组、a[1]与a[5]是一组…,这里的差值(距离)被称为增量:
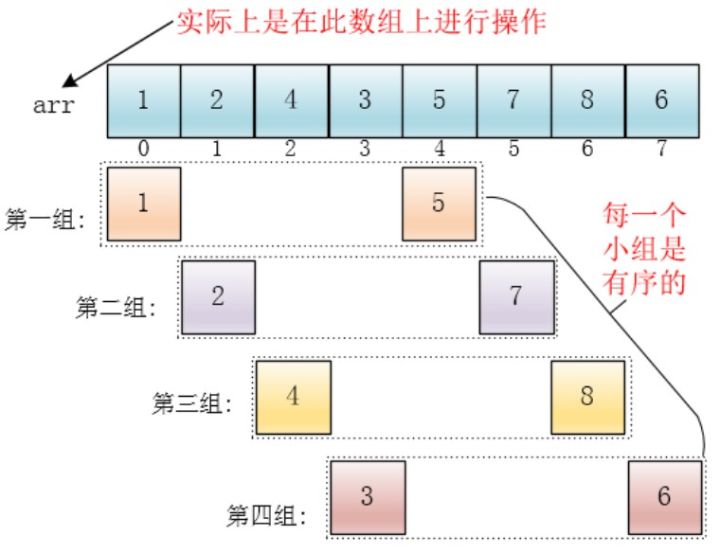
对每个分组进行插入排序后,各个分组就变成有序的了(在任意一个组中,数据元素的大小从左向右递增):
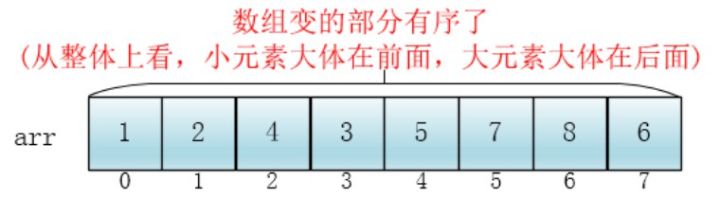
注意,这时候,整个数组变得部分有序了(即,从整体上看,小元素大体在前面,大元素大体在后面。虽然有序程度可能不是很高):
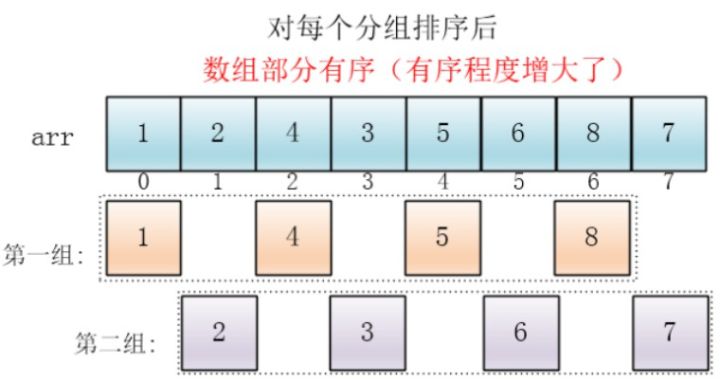
然后缩小增量(即增量变为当前增量的一半),此后继续划分分组。此时,每个分组元素个数就相对增多了,但是,数组变的部分有序了,插入排序效率同样比高:
同理对每个分组进行排序(插入排序),使其每个分组各自有序:
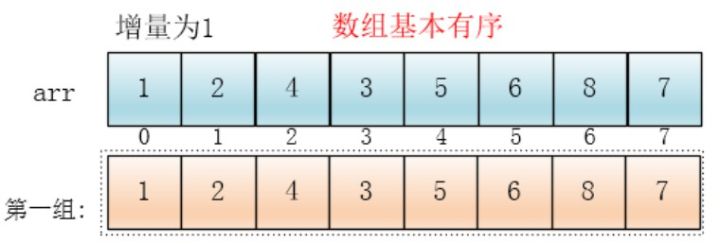
最后再设置增量为当前增量的一半,这使得则整个数组被分为一组,此时,整个数组已经接近有序了,插入排序效率高。
图解
待排序数组长度为 10 ,假设计算出的排序区间为 4 ,那么我们第一次比较应该是用第 5 个数据与第 1 个数据相比较。
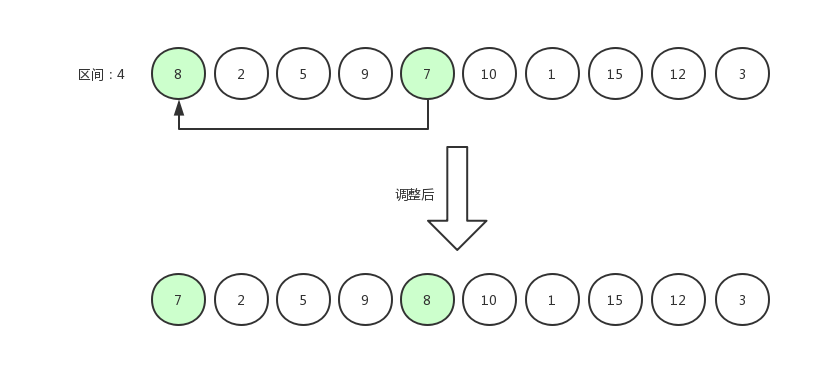
调换后的数据为[ 7,2,5,9,8,10,1,15,12,3 ],然后指针右移,第 6 个数据与第 2 个数据相比较。
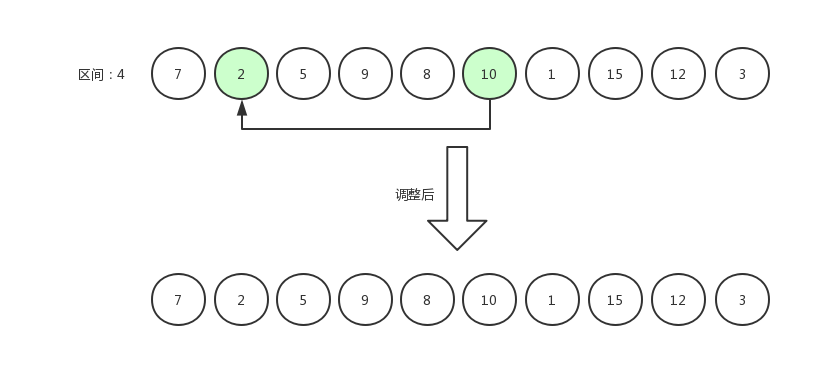
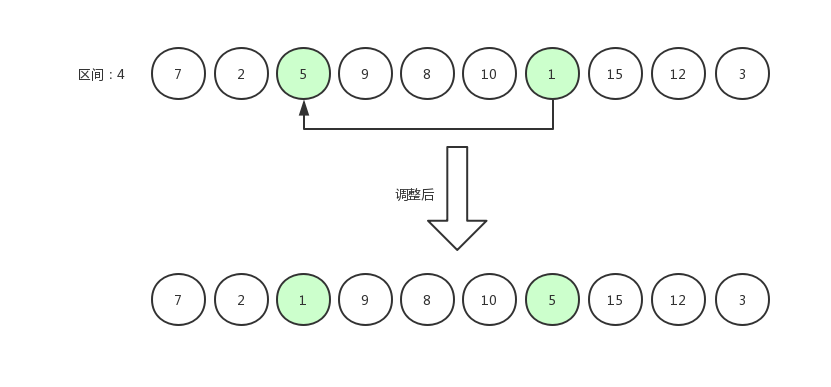
指针右移,继续比较。
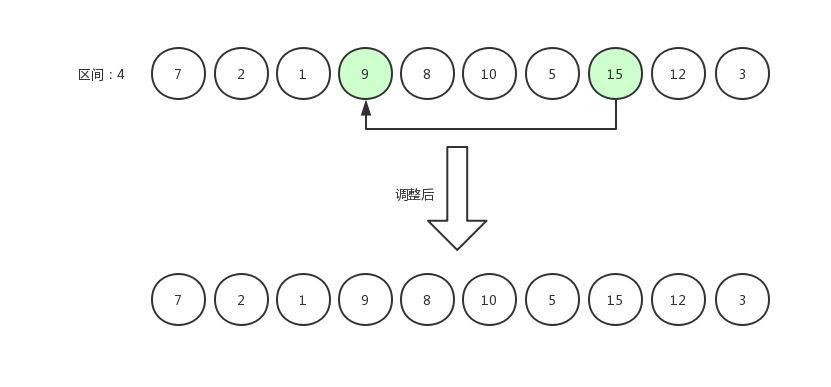
如果交换数据后,发现"当前索引值减去当前区间值">0(这说明前面存在数据),那么继续比较。比如下面这张图中描述的场景,则需要12 和 8 相比较,原地不动后,指针从 12 跳到 8 身上,继续减去当前区间值后,值仍大于 0,因此 8 和 7 相比较。
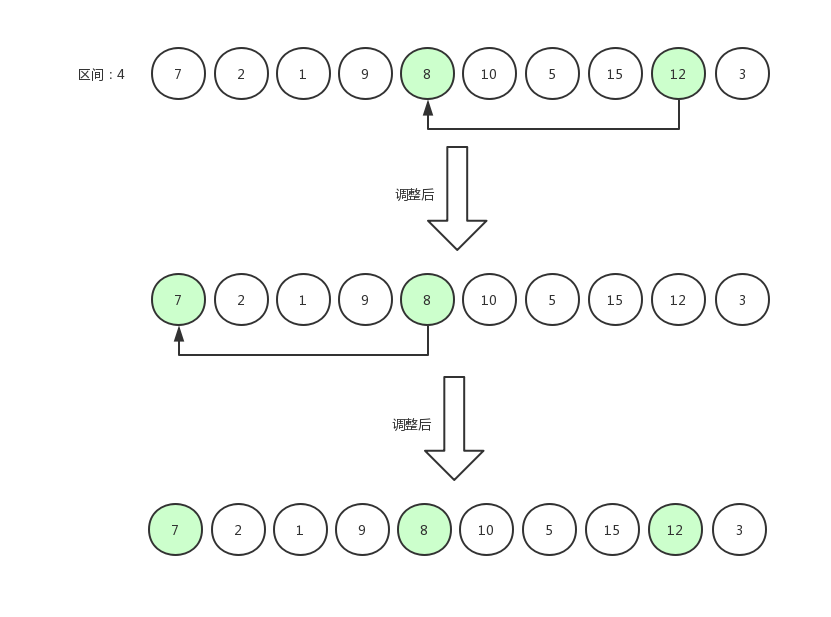
比较完之后的效果是 7,8,12 三个数为有序排列。
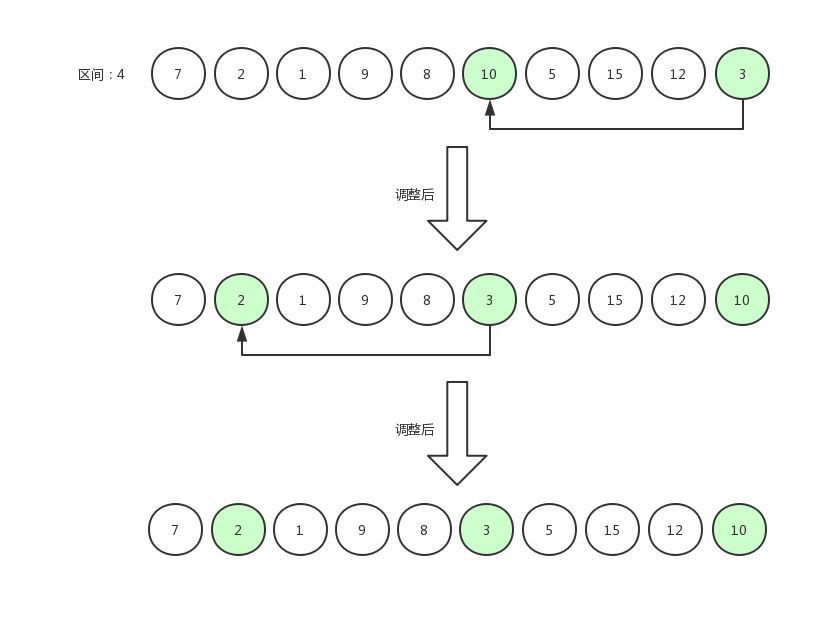
当最后一个元素比较完之后,我们会发现大部分值比较大的数据都似乎调整到数组的中后部分了。
假设整个数组比较长的话,比如有 100 个数据,那么区间值肯定是四五十,调整后区间值再缩小成一二十还会重新调整一轮,直到最后区间值缩小为 1,就是真正的排序来了。
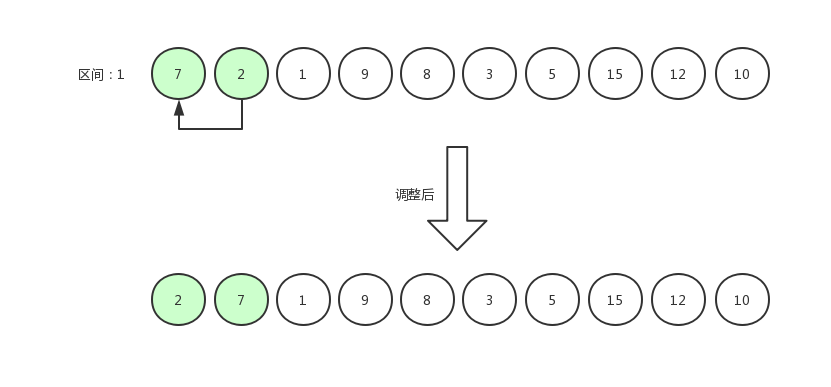
指针右移,继续比较:
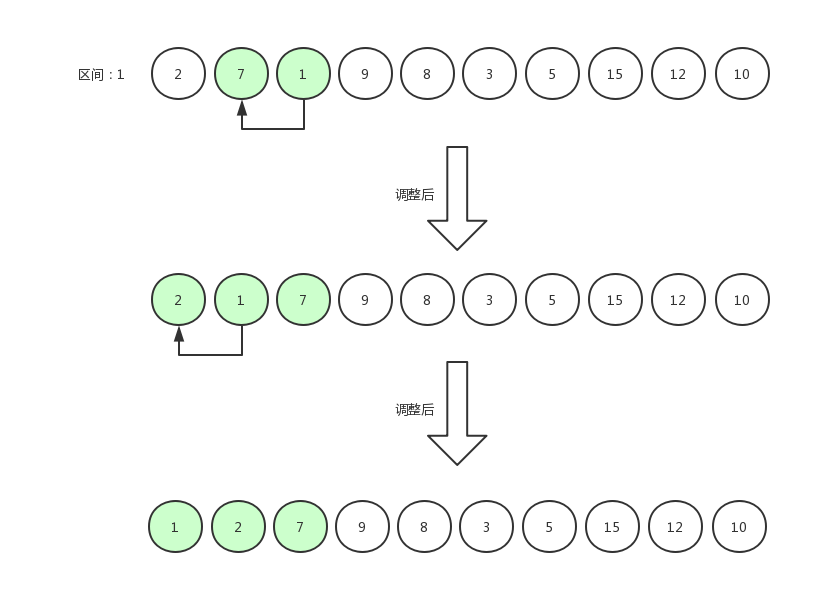
重复步骤,即可完成排序,重复的图就不多画了。
我们可以发现,当区间值为 1 的时候,它使用的排序方式就是插入排序。
Solution
private static int[] shellSort(int[] array) {
if (array == null || array.length < 2)
return array;
for (int gap = array.length / 2; gap >= 1; gap = gap / 2) {
for (int i = gap;i<array.length;i++){
int temp = array[i];
int j;
for (j = i;j >gap && array[j - gap] >temp;j = j- gap)
array[j] = array[j - gap];
array[j]= temp;
}
}
return array;
}
性能分析
希尔排序平均时间复杂度是$O(nlog_2n)$,最坏情况下为$O(n^2)$。其中分组的合理性会对算法产生重要的影响。现在多用D.E.Knuth的分组方法。
希尔排序稳定性
希尔排序是不稳定的算法,它满足稳定算法的定义。对于相同的两个数,可能由于分在不同的组中而导致它们的顺序发生变化。
算法稳定性 :假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
Reference
- 十大经典排序算法(动图演示)- https://www.cnblogs.com/onepixel/p/7674659.html
- 希尔排序 - https://zhuanlan.zhihu.com/p/36297994
- 图解排序算法(二)之希尔排序 - https://www.cnblogs.com/chengxiao/p/6104371.html
- 图解希尔排序 - https://www.itcodemonkey.com/article/3286.html
- 数据结构基础 希尔排序 之 算法复杂度浅析 - https://blog.csdn.net/u013630349/article/details/48250109
- 希尔排序 - https://www.cnblogs.com/skywang12345/p/3597597.html
- GeeksforGeeks Shell Sort - https://www.geeksforgeeks.org/shellsort/