关于Redis
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
- 数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 使用多路I/O复用模型,非阻塞IO。
Redis 单线程
我们需要注意的是,Redis 的单线程指的是 Redis 的网络 IO (6.x 版本后网络 IO 使用多线程)以及键值对指令读写是由一个线程来执行的。 对于 Redis 的持久化、集群数据同步、异步删除等都是其他线程执行。
千万别说 Redis 就只有一个线程。
单线程指的是 Redis 键值对读写指令的执行是单线程。
先说官方答案,让人觉得足够严谨,而不是人云亦云去背诵一些博客。
**官方答案:*因为 Redis 是基于内存的操作,CPU 不是 Redis 的瓶颈,Redis 的瓶颈最*有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章地采用单线程的方案了。原文地址:https://redis.io/topics/faq。
基本使用
启动
$ redis-server
停止
$ redis-cli SHUTDOWN
进入交互
$ redis-cli
多数据库
Redis是一个字典结构的存储服务器,而实际上一个Redis实例提供了多个用来存储数据的字典,客户端可以指定将数据存储在哪个字典中,这与我们熟知的在一个关系数据库实例中可以创建多个数据库类似,所以可以将其中的每个字典都理解成一个独立的数据库。
每个数据库对外都是以一个从0开始的递增数字命名,Redis默认支持16个数据库, 可以通过配置参数databases来修改这一数字。客户端与Redis建立连接后会自动选择0号数据。
redis> select 1
OK
redis [1]> GET foo
(nil)
Redis的事件
Redis服务器是一个事件驱动程序,服务器需要处理以下两类事件:
- 文件事件(file event): Redis服务器通过套接字与客户端(或者其他Redis服务器) 进行连接,而文件事件就是服务器对套接字操作的抽象。服务器与客户端(或者其他服务器)的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作。
- 时间事件(time event): Redis服务器中的一些操作(比如serverCron函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
文件事件
Redis基于Reactor模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler):
- 文件事件处理器使用I/O多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行,但通过使用I/O多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与Redis服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
文件事件处理器
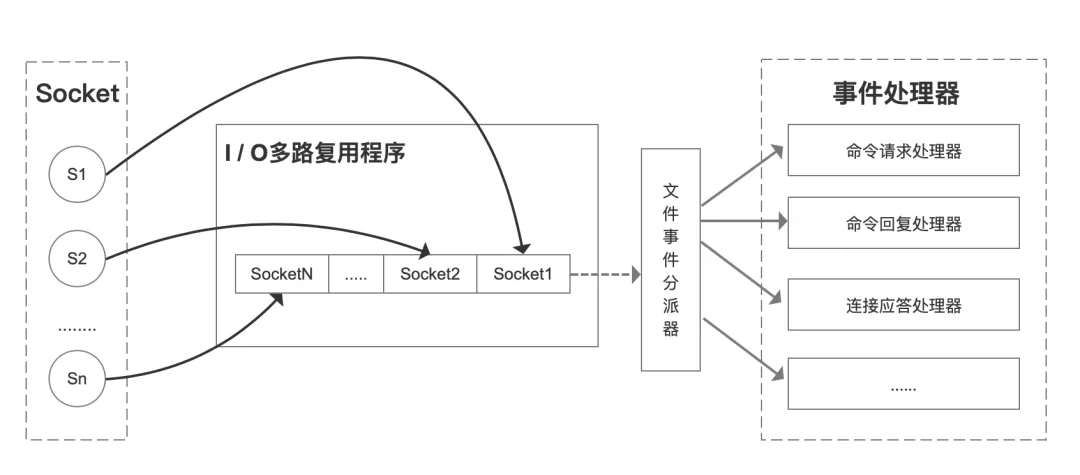
上图展示了文件事件处理器的四个组成部分:套接字、I/O多路复用程序、文件事件分派器(dispatcher),以及亊件处理器。
文件事件是对套接字操作的抽象,每当一个套接字准备好执行连接应答 (accept)、写人、读取、关闭等操作时,就会产生一个文件亊件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
I/O多路复用程序负责监听多个套接字,并向文件事件分派器传送那些产生了事件的套接字。
尽管多个文件事件可能会并发地出现,但I/O多路复用程序总是会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序(sequentially)、同步 (synchronously)、每次一个套接字的方式向文件事件分派器传送套接字。当上一个套接字产 生的事件被处理完毕之后(该套接字为事件所关联的亊件处理器执行完毕),I/O多路复用 程序才会继续向文件事件分派器传送下一个套接字,如下图所示。

文件事件分派器接收I/O多路复用程序传来的套接字,并根据套接宇产生的事件的类 型,调用相应的車件处理器。
服务器会为执行不同任务的套接宇关联不同的事件处理器,这些处理器是一个个函数, 它们定义了某个事件发生时,服务器应该执行的动作。
I/O多路复用程序的实现
Redis的I/O多路复用程序的所有功能都是通过包装常见的select、epoll、evport 和kqueue这些I/O多路复用函数库来实现的,每个I/O多路复用函数库在Redis源码中都 对应一个单独的文件,比如ae_select.c、ae epoll.c、ae_kqueue.c,诸如此类。
因为Redis为每个I/O多路复用函数库都实现了相同的API,所以I/O多路复用程序的底层实现是可以互换的。
支持的数据结构
- string
- list
- set
- hash
- sorted set
- sorted set 类型的排序功能便是通过「跳跃列表(skipList)」数据结构来实现。
//todo
Redis VS Memcached
- Nginx:多进程单线程模型
- Memcached:单进程多线程模型
两者都是非关系型内存键值数据库,主要有以下不同。
数据类型
Memcached 仅支持字符串类型,而 Redis 支持五种不同的数据类型,可以更灵活地解决问题。
数据持久化
Redis 支持两种持久化策略:RDB 快照和 AOF 日志,而 Memcached 不支持持久化。
分布式
Memcached 不支持分布式,只能通过在客户端使用一致性哈希来实现分布式存储,这种方式在存储和查询时都需要先在客户端计算一次数据所在的节点。
Redis Cluster 实现了分布式的支持。
内存管理机制
在 Redis 中,并不是所有数据都一直存储在内存中,可以将一些很久没用的 value 交换到磁盘,而 Memcached 的数据则会一直在内存中。
Memcached 将内存分割成特定长度的块来存储数据,以完全解决内存碎片的问题。但是这种方式会使得内存的利用率不高,例如块的大小为 128 bytes,只存储 100 bytes 的数据,那么剩下的 28 bytes 就浪费掉了。
一个简单的论坛系统分析
该论坛系统功能如下:
- 可以发布文章;
- 可以对文章进行点赞;
- 在首页可以按文章的发布时间或者文章的点赞数进行排序显示。
文章信息
文章包括标题、作者、赞数等信息,在关系型数据库中很容易构建一张表来存储这些信息,在 Redis 中可以使用 HASH 来存储每种信息以及其对应的值的映射。
Redis 没有关系型数据库中的表这一概念来将同种类型的数据存放在一起,而是使用命名空间的方式来实现这一功能。键名的前面部分存储命名空间,后面部分的内容存储 ID,通常使用 : 来进行分隔。例如下面的 HASH 的键名为 article:92617,其中 article 为命名空间,ID 为 92617。

点赞功能
当有用户为一篇文章点赞时,除了要对该文章的 votes 字段进行加 1 操作,还必须记录该用户已经对该文章进行了点赞,防止用户点赞次数超过 1。可以建立文章的已投票用户集合来进行记录。
为了节约内存,规定一篇文章发布满一周之后,就不能再对它进行投票,而文章的已投票集合也会被删除,可以为文章的已投票集合设置一个一周的过期时间就能实现这个规定。

对文章进行排序
为了按发布时间和点赞数进行排序,可以建立一个文章发布时间的有序集合和一个文章点赞数的有序集合。(下图中的 score 就是这里所说的点赞数;下面所示的有序集合分值并不直接是时间和点赞数,而是根据时间和点赞数间接计算出来的)

Reference
- 《Redis入门指南》
- 《Redis设计与实现》
- https://mp.weixin.qq.com/s/h9pM-3pMYMzs__6Emx7tqA
- 这可能是目前最全的Redis高可用技术解决方案总结 - https://mp.weixin.qq.com/s/r1ig-jO13YxbqrofJzmkfw
- Redis -https://cyc2018.github.io/CS-Notes/#/notes/Redis?id=%e5%85%ad%e3%80%81%e9%94%ae%e7%9a%84%e8%bf%87%e6%9c%9f%e6%97%b6%e9%97%b4