Isolation Levels
Transaction isolation is one of the foundations of database processing. Isolation is the I in the acronym ACID; the isolation level is the setting that fine-tunes the balance between performance and reliability, consistency, and reproducibility of results when multiple transactions are making changes and performing queries at the same time.
Although some database management systems offer MVCC, usually concurrency control is achieved through locking. But as we all know, locking increases the serializable portion of the executed code, affecting parallelization.
The SQL standard defines four Isolation levels:
- READ_UNCOMMITTED
- READ_COMMITTED
- REPEATABLE_READ
- SERIALIZABLE
All but the SERIALIZABLE level are subject to data anomalies (phenomena) that might occur according to the following pattern:
| Isolation Level | Lost updates | Dirty read | Non-repeatable read | Phantom read |
|---|---|---|---|---|
| READ_UNCOMMITTED | prevented | allowed | allowed | allowed |
| READ_COMMITTED | prevented | prevented | allowed | allowed |
| REPEATABLE_READ | prevented | prevented | prevented | allowed |
| SERIALIZABLE | prevented | prevented | prevented | prevented |
以上顺序是从松到严(即从更多不一致到更少不一致)
Default Isolation Levels
Even if the SOL standard mandates the use of the SERIALIZABLE isolation level, most database management systems use a different default level.
| Database | Default isolation Level |
|---|---|
| Oracle | READ_COMMITTED |
| MySQL | REPEATABLE_READ |
| Microsoft SQL Server | READ_COMMITTED |
| PostgreSQL | READ_COMMITTED |
| DB2 | CURSOR STABILITY |
Usually, READ_COMMITED is the right choice, since not even SERIALIZABLE can protect you from a lost update where the reads/writes happen in different transactions (and web requests). You should take into consideration your enterprise system requirements and set up tests for deciding which isolation level best suits your needs.
READ UNCOMMITTED
SELECT statements are performed in a nonlocking fashion, but a possible earlier version of a row might be used. Thus, using this isolation level, such reads are not consistent. This is also called a dirty read. Otherwise, this isolation level works like READ COMMITTED.
READ COMMITTED
The most basic level of transaction isolation is read committed. It makes two guarantees:
-
When reading from the database, you will only see data that has been committed (no dirty reads).
-
When writing to the database, you will only overwrite data that has been committed (no dirty writes).
Let’s discuss these two guarantees in more detail.
No dirty reads
Imagine a transaction has written some data to the database, but the transaction has not yet committed or aborted. Can another transaction see that uncommitted data? If yes, that is called a dirty read.
Transactions running at the read committed isolation level must prevent dirty reads. This means that any writes by a transaction only become visible to others when that transaction commits (and then all of its writes become visible at once). This is illustrated below, where user 1 has set x = 3, but user 2’s get x still returns the old value, 2, while user 1 has not yet committed.
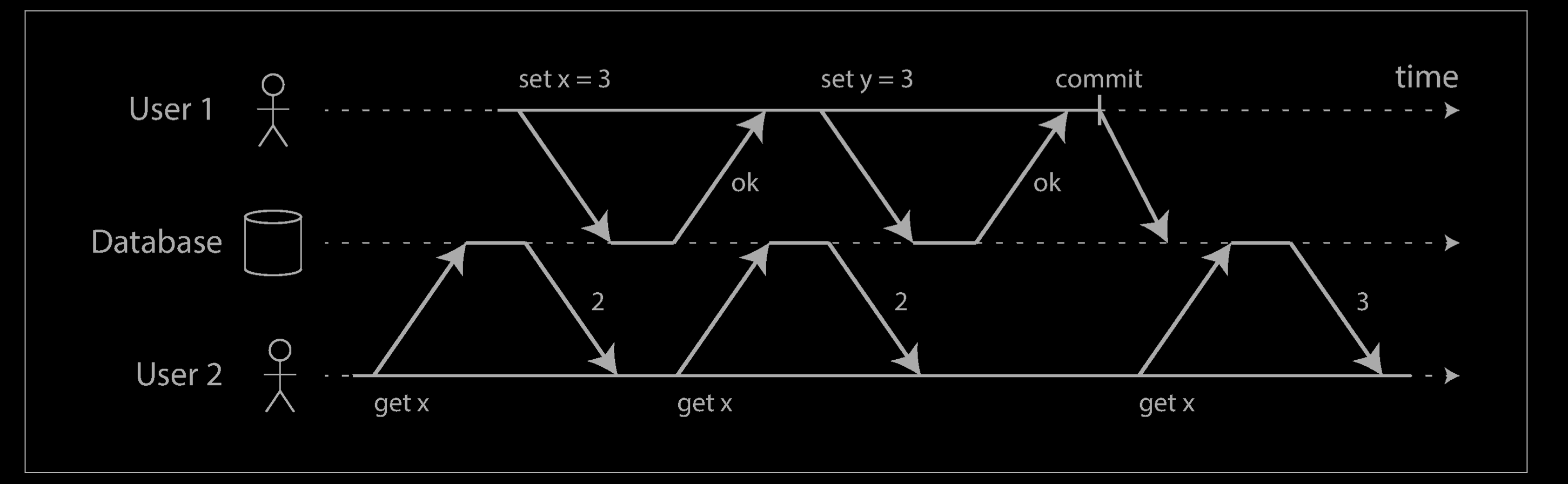
There are a few reasons why it’s useful to prevent dirty reads:
- If a transaction needs to update several objects, a dirty read means that another transaction may see some of the updates but not others. For example, in the example above, the user sees the new unread email but not the updated counter. This is a dirty read of the email. Seeing the database in a partially updated state is confusing to users and may cause other transactions to take incorrect decisions.
- If a transaction aborts, any writes it has made need to be rolled back. If the database allows dirty reads, that means a transaction may see data that is later rolled back—i.e., which is never actually committed to the data‐base. Reasoning about the consequences quickly becomes mind-bending.
No dirty writes
What happens if two transactions concurrently try to update the same object in a database? We don’t know in which order the writes will happen, but we normally assume that the later write overwrites the earlier write.
However, what happens if the earlier write is part of a transaction that has not yet committed, so the later write overwrites an uncommitted value? This is called a dirty write. Transactions running at the read committed isolation level must prevent dirty writes, usually by delaying the second write until the first write’s transaction has committed or aborted.
By preventing dirty writes, this isolation level avoids some kinds of concurrency problems:
- If transactions update multiple objects, dirty writes can lead to a bad outcome. For example, consider the example below, which illustrates a used car sales website on which two people, Alice and Bob, are simultaneously trying to buy the same car. Buying a car requires two database writes: the listing on the website needs to be updated to reflect the buyer, and the sales invoice needs to be sent to the buyer. In the case of this example, the sale is awarded to Bob (because he performs the winning update to the listings table), but the invoice is sent to Alice (because she performs the winning update to the invoices table). Read committed prevents such mishaps.
- However, read committed does not prevent the race condition between two counter increments. In this case, the second write happens after the first transaction has committed, so it’s not a dirty write. It’s still incorrect, but for a different reason.
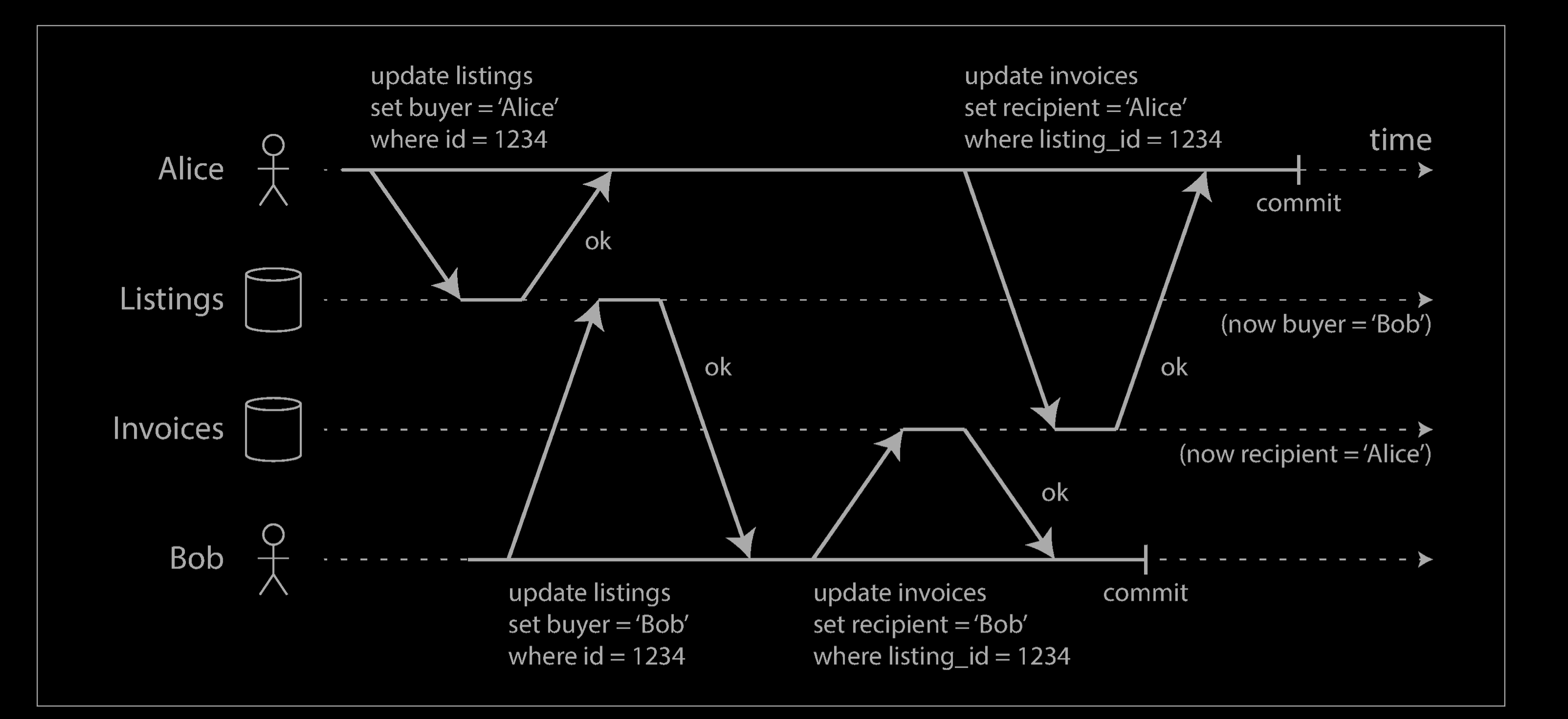
Implementing read committed
Read committed is a very popular isolation level. It is the default setting in Oracle 11g, PostgreSQL, SQL Server 2012, MemSQL, and many other databases.
Most commonly, databases prevent dirty writes by using row-level locks: when a transaction wants to modify a particular object (row or document), it must first acquire a lock on that object. It must then hold that lock until the transaction is committed or aborted. Only one transaction can hold the lock for any given object; if another transaction wants to write to the same object, it must wait until the first transaction is committed or aborted before it can acquire the lock and continue. This locking is done automatically by databases in read committed mode (or stronger isolation levels).
How do we prevent dirty reads? One option would be to use the same lock, and to require any transaction that wants to read an object to briefly acquire the lock and then release it again immediately after reading. This would ensure that a read couldn’t happen while an object has a dirty, uncommitted value (because during that time the lock would be held by the transaction that has made the write).
However, the approach of requiring read locks does not work well in practice, because one long-running write transaction can force many read-only transactions to wait until the long-running transaction has completed. This harms the response time of read-only transactions and is bad for operability: a slowdown in one part of an application can have a knock-on effect in a completely different part of the application, due to waiting for locks.
For that reason, most databases prevent dirty reads using this approach: for every object that is written, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock. While the transaction is ongoing, any other transactions that read the object are simply given the old value. Only when the new value is committed do transactions switch over to reading the new value.
REPEATABLE READ / Snapshot Isolation
This is the default isolation level for InnoDB. Consistent reads within the same transaction read the snapshot established by the first read. This means that if you issue several plain (nonlocking) SELECT statements within the same transaction, these SELECT statements are consistent also with respect to each other. See Section 15.7.2.3, “Consistent Nonlocking Reads”.
For locking reads (SELECT with FOR UPDATE or FOR SHARE), UPDATE, and DELETE statements, locking depends on whether the statement uses a unique index with a unique search condition, or a range-type search condition.
- For a unique index with a unique search condition,
InnoDBlocks only the index record found, not the gap before it. - For other search conditions,
InnoDBlocks the index range scanned, using gap locks or next-key locks to block insertions by other sessions into the gaps covered by the range. For information about gap locks and next-key locks, see Section 15.7.1, “InnoDB Locking”.
Implementing snapshot isolation
Like read committed isolation, implementations of snapshot isolation typically use write locks to prevent dirty writes, which means that a transaction that makes a write can block the progress of another transaction that writes to the same object. However, reads do not require any locks. From a performance point of view, a key principle of snapshot isolation is readers never block writers, and writers never block readers. This allows a database to handle long-running read queries on a consistent snapshot at the same time as processing writes normally, without any lock contention between the two.
To implement snapshot isolation, databases use a generalization of the mechanism we saw for preventing dirty reads. The database must potentially keep several different committed versions of an object, because various in-progress transactions may need to see the state of the database at different points in time. Because it maintains several versions of an object side by side, this technique is known as multi-version concurrency control (MVCC).
If a database only needed to provide read committed isolation, but not snapshot iso‐lation, it would be sufficient to keep two versions of an object: the committed version and the overwritten-but-not-yet-committed version. However, storage engines that support snapshot isolation typically use MVCC for their read committed isolation level as well. A typical approach is that read committed uses a separate snapshot for each query, while snapshot isolation uses the same snapshot for an entire transaction.
The example below illustrates how MVCC-based snapshot isolation is implemented in Post‐greSQL (other implementations are similar). When a transaction is started, it is given a unique, always-increasing vii transaction ID (txid). Whenever a transaction writes anything to the database, the data it writes is tagged with the transaction ID of the writer.
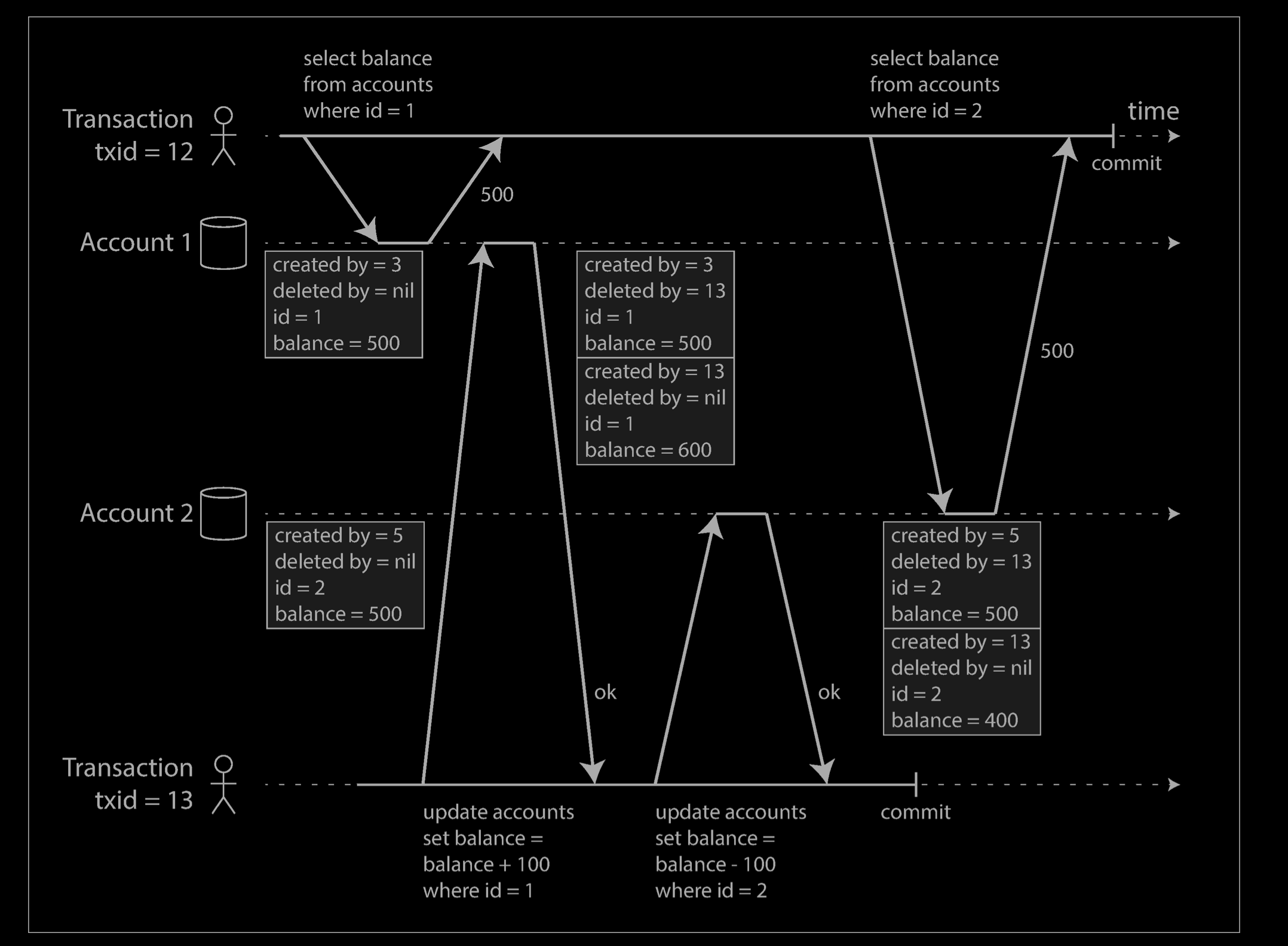
Each row in a table has a created_by field, containing the ID of the transaction that inserted this row into the table. Moreover, each row has a deleted_by field, which is initially empty. If a transaction deletes a row, the row isn’t actually deleted from the database, but it is marked for deletion by setting the deleted_by field to the ID of the transaction that requested the deletion. At some later time, when it is certain that no transaction can any longer access the deleted data, a garbage collection process in the database removes any rows marked for deletion and frees their space.
SERIALIZABLE
Serializable isolation is usually regarded as the strongest isolation level. It guarantees that even though transactions may execute in parallel, the end result is the same as if they had executed one at a time, serially, without any concurrency. Thus, the database guarantees that if the transactions behave correctly when run individually, they continue to be correct when run concurrently—in other words, the database prevents all possible race conditions.
How to achieve SERIALIZABLE
But if serializable isolation is so much better than the mess of weak isolation levels, then why isn’t everyone using it? To answer this question, we need to look at the options for implementing serializability, and how they perform. Most databases that provide serializability today use one of three techniques:
- Literally executing transactions in a serial order
- Two-phase locking (see “Two-Phase Locking (2PL)”), which for several decades was the only viable option
- Optimistic concurrency control techniques such as serializable snapshot isolation
Actual Serial Execution
The simplest way of avoiding concurrency problems is to remove the concurrency entirely: to execute only one transaction at a time, in serial order, on a single thread. By doing so, we completely sidestep the problem of detecting and preventing conflicts between transactions: the resulting isolation is by definition serializable.
Summary of serial execution
Serial execution of transactions has become a viable way of achieving serializable isolation within certain constraints:
- Every transaction must be small and fast, because it takes only one slow transaction to stall all transaction processing.
- It is limited to use cases where the active dataset can fit in memory. Rarely accessed data could potentially be moved to disk, but if it needed to be accessed in a single-threaded transaction, the system would get very slow. x
- Write throughput must be low enough to be handled on a single CPU core, or else transactions need to be partitioned without requiring cross-partition coordi‐nation.
- Cross-partition transactions are possible, but there is a hard limit to the extent to which they can be used.
Two-Phase Locking (2PL)
For around 30 years, there was only one widely used algorithm for serializability in databases: two-phase locking (2PL).
Several transactions are allowed to concurrently read the same object as long as nobody is writing to it. But as soon as anyone wants to write (modify or delete) an object, exclusive access is required:
- If transaction A has read an object and transaction B wants to write to that object, B must wait until A commits or aborts before it can continue. (This ensures that B can’t change the object unexpectedly behind A’s back.)
- If transaction A has written an object and transaction B wants to read that object, B must wait until A commits or aborts before it can continue. (Reading an old version of the object is not acceptable under 2PL.)
In 2PL, writers don’t just block other writers; they also block readers and vice versa. Snapshot isolation has the mantra readers never block writers, and writers never block readers, which captures this key difference between snapshot isolation and two-phase locking. On the other hand, because 2PL provides serializability, it protects against all the race conditions discussed earlier, including lost updates and write skew.
Implementation of two-phase locking
Performance of two-phase locking
Serializable Snapshot Isolation (SSI)
Reference
- https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
- A beginner’s guide to ACID and database transactions - https://vladmihalcea.com/a-beginners-guide-to-acid-and-database-transactions/