Cache Aside Pattern / Lazy-loading
This is the most commonly used cache update strategy in applications.
其具体逻辑如下:
-
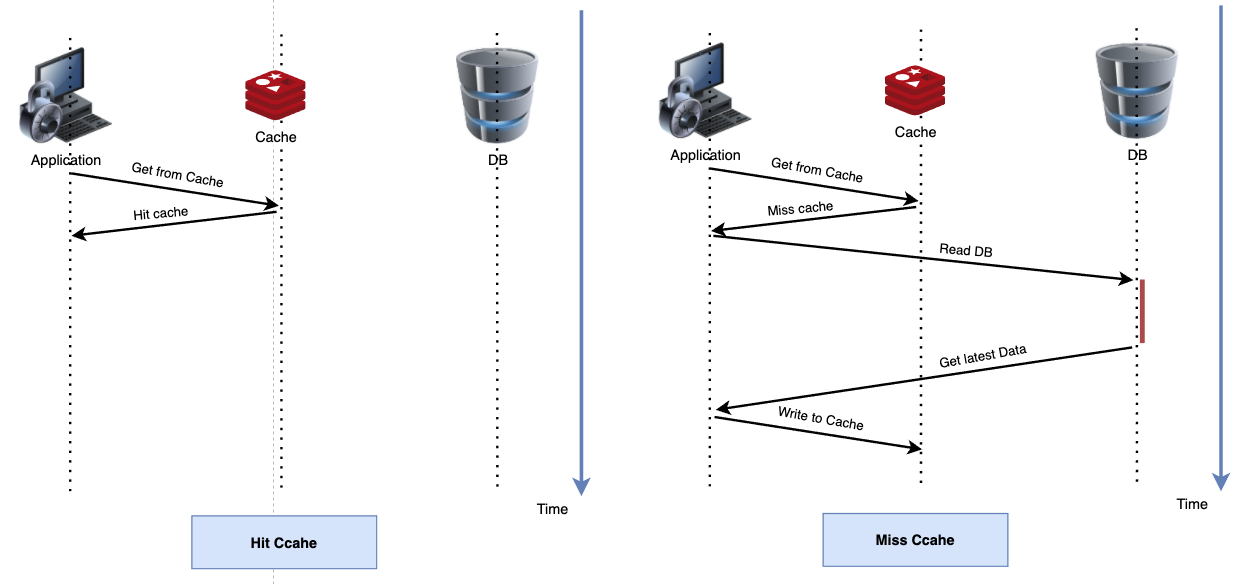
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
-
命中:应用程序从cache中取数据,取到后返回。
-
更新:先把数据存到数据库中,成功后,再让缓存失效。
Scenarios
缓存失效/命中
In this update strategy, cache sits aside and an application talks to cache and data store directly. It is also known as lazy-loading. Application logic first checks in the cache before hitting the database. It is mostly used with an application with read-heavy workloads.
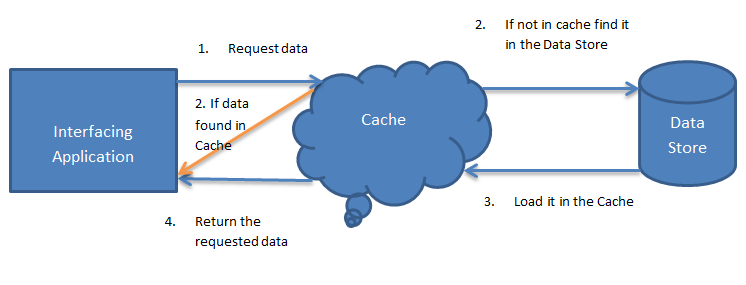
An application retrieves data by referencing the cache. If the data isn’t in the cache, it’s retrieved from the data store and added to the cache. Any modifications to data held in the cache are automatically written back to the data store as well.
For caches that don’t provide this functionality, it’s the responsibility of the applications that use the cache to maintain the data.
缓存更新
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
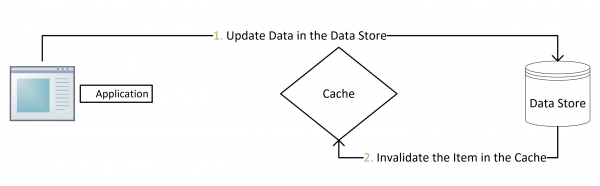
Discussion - 缓存更新时,Delete Cache First or Update DB First
结论是,一定要 Update DB First ,且必须要等 Update 成功后,再 Delete Cache。
要不然,可以想象,如果 update DB成功了,如果这时候QPS 很高,delete cache已经完成了,这时,另外一个request发现 cache中没有数据,因此从还没有被update 的 DB 中读到未更新的数据,并写入到cache中,这样就产生了stale data,且即使在update DB之后,这个stale data仍然会一直存在,直到再次发生delte cache。
Potential Problem
那么,是不是Cache Aside就一定不会有并发问题了?
Scenario 1
不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让 cache 失效。
然后,由于某些原因(比如网络拥塞了),读操作读到的旧数据被写入到了 cache。
这时,仍然出现了脏数据。
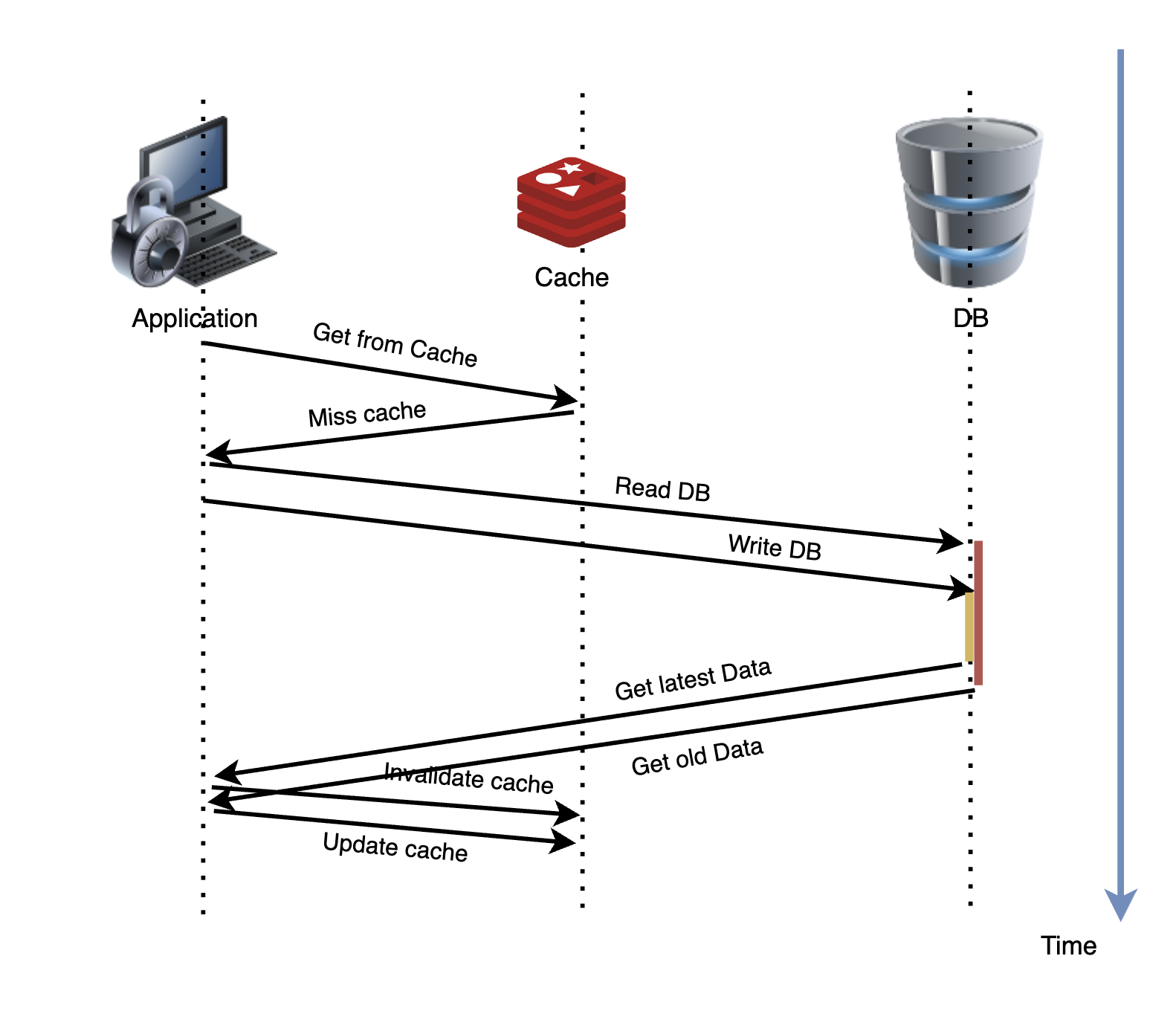
但,这个case理论上会出现。不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时,出现缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还可能锁表,而读操作必需在写操作前进行数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
Scenario 2
当然,还有其他的可能也会导致脏数据,比如:
如果使用了MySQL Master-Slave,当出现DB delay的时候,当完成写操作且触发 invalidate cache 操作后,从Slave DB读取数据,且读取到的数据是更新前的旧数据(由于 DB delay),从而使得重新写入 cache 中的数据仍然是旧数据。
由于 Master-Slave architecture被比较广泛地使用,出现这种场景的概率可能会远远的高于 Scenario 1。
Solution
Solution 1
如果把 invalidate cache 改成用master的数据 update cache,则可以避免这个问题。
Solution 2
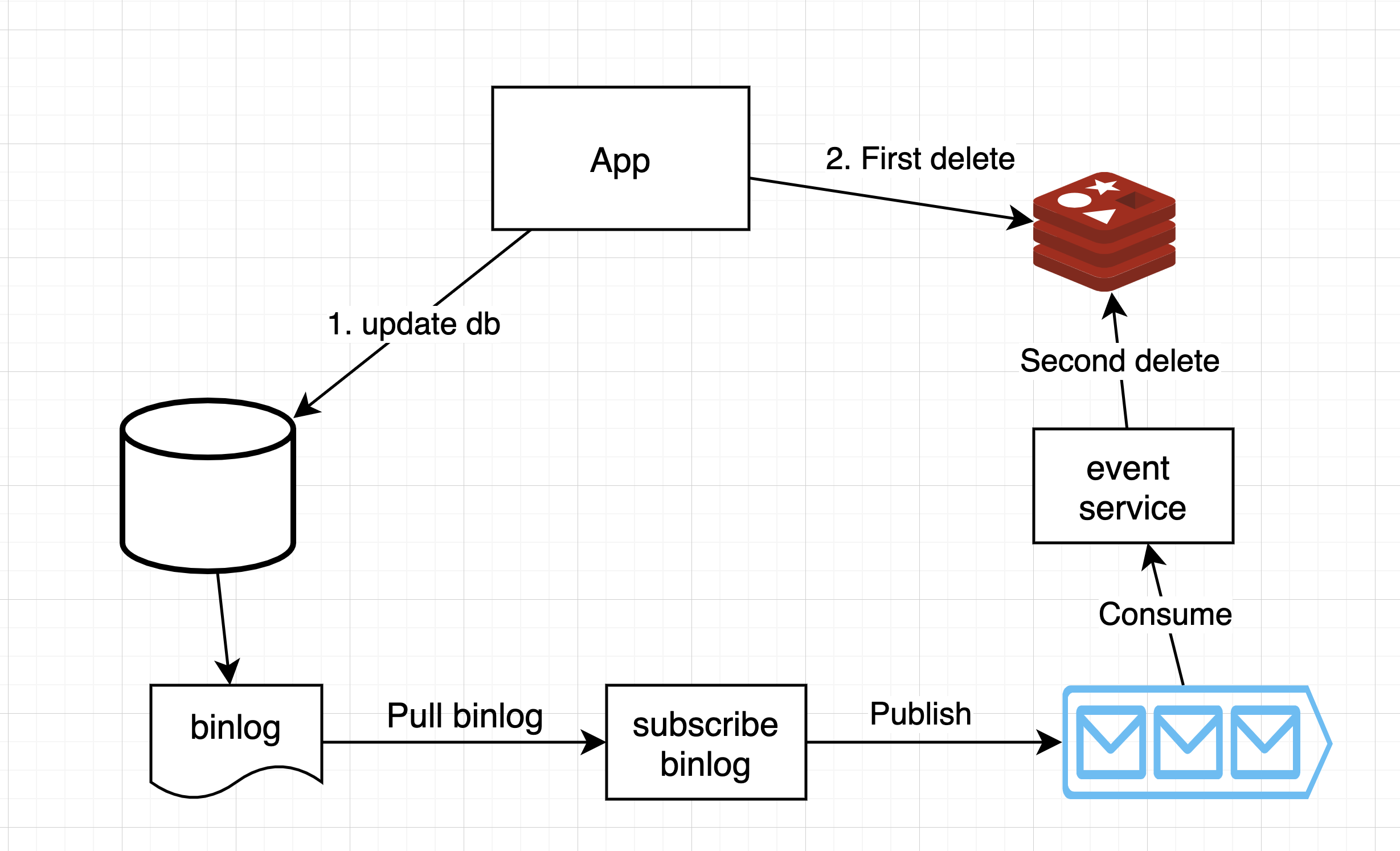
采用延时双删策略(缓存双淘汰法,Delayed Double Eviction Strategy),可以将前面所造成的缓存脏数据,再次删除,即:
-
先写数据库
-
删除缓存
-
休眠1秒,再次删除缓存
-
这一步可以通过以下方式实现
- Solution 1:在第一次删除缓存后,开启一个线程,并让这个线程在1s后,执行再次删除
- Solution 2:通过读取DB的binlog和一个消息队列来实现再次删除
-
Analysis
- single source of truth 为 DB
- 这里具体休眠多久要结合业务情况考虑
- 如果考虑到删除可能失败,再增加删除失败时的重试机制
结论
所以,我们还是需要回到CAP,即要么通过2PC或是Paxos协议保证一致性(通过牺牲可用性来避免上面问题的出现),要么牺牲一致性来保证可用性。
Example
The following is a pseudocode example of lazy loading logic.
// *****************************************
// function that returns a customer's record.
// Attempts to retrieve the record from the cache.
// If it is retrieved, the record is returned to the application.
// If the record is not retrieved from the cache, it is
// retrieved from the database,
// added to the cache, and
// returned to the application
// *****************************************
get_customer(customer_id)
customer_record = cache.get(customer_id)
if (customer_record == null)
customer_record = db.query("SELECT * FROM Customers WHERE id = {0}", customer_id)
cache.set(customer_id, customer_record)
return customer_record
For this example, the application code that gets the data is the following.
customer_record = get_customer(12345)
Analysis
Advantages
Load Data on Demand
- It does not load or hold all the data together, it’s on demand. Suitable for cases when you know that your application might not need to cache all data from data source in a particular category.
Node failures aren’t fatal for your application
- When a node fails and is replaced by a new, empty node, your application continues to function, though with increased latency.
- As requests are made to the new node, each cache miss results in a query of the database. At the same time, the data copy is added to the cache so that subsequent requests are retrieved from the cache.
Disadvantages
The disadvantages of lazy loading are as follows
Cache Miss Penalty
Each cache miss results in three trips:
- Initial request for data from the cache
- Query of the database for the data
- Writing the data to the cache
- These misses can cause a noticeable delay in data getting to the application.
How to solve
- Developers deal with this by warming (pre-heating) the cache or invalidating the cache (instead of emptying cache) or Refresh Ahead Caching.
Stale Data
- Since data is written to the cache only when there is a cache miss, data in the cache can become stale. This result occurs because there are no updates to the cache when data is changed in the database.
- To address this issue, you can use cache update mechanisms (e.g., Write-through), update invalidation mechanisms, or Adding TTL.
Possible Low Cache Hit Rate
- Because most data is never requested, lazy loading avoids filling up the cache with data that isn’t requested.
Read-through VS cache-aside
While read-through and cache-aside are very similar, there are at least two key differences:
- In cache-aside, the application is responsible for fetching data from the database and populating the cache. In read-through, this logic is usually supported by the library or stand-alone cache provider (which means that the internal storage components are transparent to the clients/callers and what they can perceive is one single storage).
- Unlike cache-aside, the data model in read-through cache cannot be different than that of the database.
Reference
- https://en.wikipedia.org/wiki/Cache_(computing)
- https://en.wikipedia.org/wiki/Cache_coherence
- https://coolshell.cn/articles/17416.html
- https://dzone.com/articles/cache-aside-pattern
- https://www.quora.com/Why-does-Facebook-use-delete-to-remove-the-key-value-pair-in-Memcached-instead-of-updating-the-Memcached-during-write-request-to-the-backend
- https://docs.microsoft.com/en-us/azure/architecture/patterns/cache-aside
- https://medium.com/system-design-blog/what-is-caching-1492abb92143
- https://www.ehcache.org/documentation/3.3/caching-patterns.html
- https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
- https://docs.aws.amazon.com/AmazonElastiCache/latest/mem-ug/Strategies.html
- https://medium.datadriveninvestor.com/all-things-caching-use-cases-benefits-strategies-choosing-a-caching-technology-exploring-fa6c1f2e93aa