Causes
The hotkey issue can have the following two causes:
-
The size of data consumed by users is much greater than that of produced data, as in the cases of hot sale items, hot news, hot comments, and celebrity live streaming.
- The hotkey issue tends to occur unexpectedly, for example, the sales price promotion of popular commodities during Double 11. When one of these commodities is browsed or purchased tens of thousands of times, a large number of requests are processed, which causes the hotkey issue. Similarly, the hotkey issue tends to occur in scenarios where more read requests are processed than write requests. For example, hot news, hot comments, and celebrity live streaming.
-
In these cases, hotkeys are accessed much more frequently than other keys. Therefore, most of the user traffic is centralized to a specific Redis instance, and the Redis instance may reach a performance bottleneck.
- When a piece of data is accessed on the server, the data is partitioning. During this process, the corresponding key is accessed on the server. When the load exceeds the performance threshold of the server, the hotkey issue occurs.
还有一种很特殊的情况,一个key作为lock,而这个key本身是hot key。在这种情况下,以下的solution就不能使用了。
Impacts
- The traffic is aggregated and reaches the upper limit of the physical network adapter.
- Excessive requests queue up, and the partitioning service stops responding.
- The database is overloaded and the service is interrupted.
When the number of hotkey requests on a server exceeds the upper limit of the network adapter on the server, the server stops providing other services due to the concentrated traffic. If hotkeys are densely distributed, a large number of hotkeys are cached. When the cache capacity is exhausted, the partitioning service stops responding. After the caching service stops responding, the newly generated requests are cached on the backend database. Due to its poor performance, this database is prone to exhaustion when the database handles a large number of requests. The exhaustion of the database leads to service interruption and a dramatic downgrading of the performance.
hot key 会导致 Redis node imbalance,甚至出现雪崩(Redis node 被打到100% CPU,挂了)。
How to Detect Hot Key
Method 1 - Predict which hot keys are based on business experience
In fact, this method is quite feasible. For example, Flashsale items are normally hot keys.
The disadvantage is obvious. Not all businesses can predict which keys are hot keys.
Method 2 - Collect on the client side
This way is to add a line of code to the data statistics before operating redis. There are many ways to count this data, or to send a notification message to an external communication system.
The disadvantage is that the client code is invaded.
Method 3 - Collect in Proxy layer
Some cluster architectures are as follows: Proxy can be Twemproxy, which is a unified entry point. Collection reporting can be done at the Proxy layer, but the drawback is obvious. Not all redis cluster architectures have proxy.
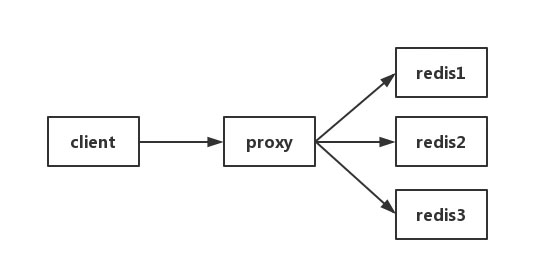
Method 4 - Use redis with commands
- Monitor command, which can capture commands received by redis server in real time, and then write code to count hot keys. Of course, there are ready-made analytical tools for you to use, such as redis-faina. However, under the condition of high concurrency, this command has the hidden danger of memory explosion, and also reduces the performance of redis.
- The hotkeys parameter, redis 4.0.3, provides the hot key discovery function of redis-cli, and the hotkeys option is added when redis-cli is executed. But when this parameter is executed, if there are more keys, it will be executed slowly.
Method 5 - Self-assessment
Redis client uses TCP protocol to interact with server, and the communication protocol is RESP. Write your own program to listen on the port, parse the data according to RESP protocol rules, and analyze. The disadvantage is that the development cost is high, the maintenance is difficult, and there is the possibility of losing the package.
Each of the five schemes has its advantages and disadvantages. Choose according to your business scenario. So how to solve the problem after hot key is found?
Solution
Approach 1 - Shard hot key
- Manual replication: Add hot key suffix to the hot key.
- Example: if hot key is itemA, create itemA_1, itemA_2, .. itemA_10 etc, which will be distributed in different redis nodes.
- Read query goes to a random replicated key, which help to spread the traffic
Cons
- Writes need to be updated to all replicated keys => Amplification of writes
- Possible data inconsistency due to network issues
Approach 2 - Read from slave / Increase number of slaves
Pros
- Configure cluster on space to also read from slave.
- Can request to cache cloud team to add slaves.
- Safe infra-only solution
Cons
- Inefficient solution as traffic is low on other non-hot redis instances.
Approach 2 - 增加in-memory cache
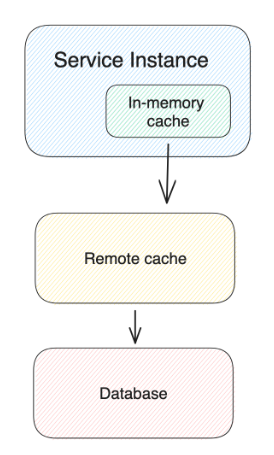
- Add another caching layer at the application layer
Request Flow:
- Fetch data from local cache. If missed, fetch from remote cache and set data in local cache.
Disadvantages:
- Data inconsistency between different application instances
- Hard to invalidate local cache
- Local cache has limitations on memory size
Approach 3 - Ad-hoc Whitelist
设置一个whitelist,对于特别hot的shop或者promotion,增加expire time。
Approach 4 - In-process Lock
A in-process lock is applied to reduce the stress to remote cache service when multiple requests meet cache miss of in memory cache store and need to fetch data from remote cache concurrently.
For Get operation, there will be a in process lock (key level) to protect our remote cache service. Therefore, when concurrent requests want to fetch data from remote cache at the same time, only one can guarantee the in process lock and set it back to the in memory cache. For the other requests which did not get the lock, they will retry to fetch data from in memory cache with total wait time 50ms and retry interval 5ms.
Approach 5 - Distributed Lock
每次去 Remote Cache读之前,需要先拿到lock。
这样做会有以下的问题:
- service 的 throughhput 会降低,因为concurrent level 降低了
- distributed lock本身可能会成为hot key,继而引发新的问题
Reference
- https://www.alibabacloud.com/help/doc-detail/67252.htm
- https://alibaba-cloud.medium.com/redis-hotspot-key-discovery-and-common-solutions-95474d27e0f8