Write Back / Write Behind / Lazy Write Pattern
一些了解Linux操作系统内核的同学对write back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?是的,你看基础这玩意全都是相通的。
Initially, writing is done only to the cache. The write to the backing store is postponed until the modified content is about to be replaced by another cache block.
Write Back 的套路,一句说就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(则无法保证一致性,甚至是最终一致性也无法保证)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性性是有冲突的。软件设计从来都是取舍Trade-Off。
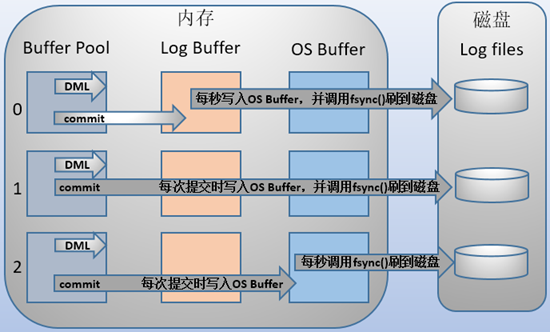
在 MySQL 中,其实也有类似的思想,即:
- 当我们想要修改 DB 上某一行数据的时候(执行一条
DML语句),InnoDB 是对位于从磁盘读取到内存的 Buffer Pool 的数据进行修改(我们这里假设这个数据已经存在于 Buffer Pool,在一般情况中,当然可能出现 cache miss,因而不在 Buffer Pool 中),即这个时候数据的更新只在内存中被存储,因而和磁盘中数据就存在了差异,我们称这种有差异的数据为脏页(dirty page)。 - 而为了解决这种差异可能导致的因宕机带来的数据不一致性,就引入了 Redo Logs
- Refer to https://swsmile.info/post/mysql-redo-logs/
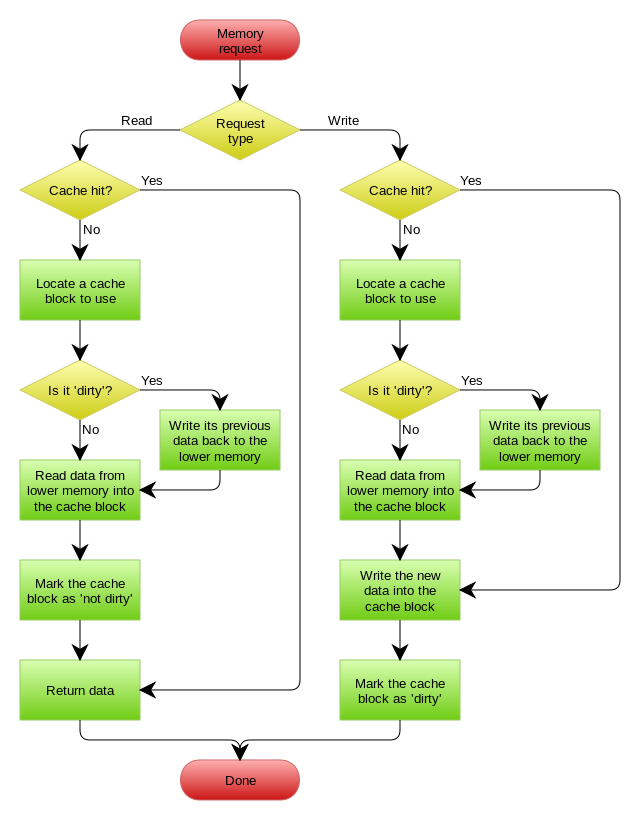
A write-back cache is more complex to implement, since it needs to track which of its locations have been written over, and mark them as dirty for later writing to the backing store.
The data in these locations are written back to the backing store only when they are evicted from the cache, an effect referred to as a lazy write.
For this reason, a read miss in a write-back cache (which requires a block to be replaced by another) will often require two memory accesses to service: one to write the replaced data from the cache back to the store, and then one to retrieve the needed data.
Analysis
Advantages
Extremely High Read/Write Performance
Since we could just directly read the latest data from cache, the read performance is extremely high.
And similarly, since cache is much faster than DB, thus the write performance is extremely high as well.
Data in the cache is never stale
- Because the data in the cache is updated every time it’s written to the database, the data in the cache is always current.
- Suitable for read heavy systems which can’t much tolerate staleness.
Disadvantages
Stale Data in DB
- Eventual consistency between database & caching system. So any direct operation on database or joining operation may use stale data.
- But normally it won’t be an issue, since we always know the data in cache is up-of-date, and thus we access DB to get the latest data
Possible to Lost Data (Consistent Issue)
- If cache is suddenly down, may not be able to bring back to the eventual consistency state, and even not able to bring back to a consistent state.
Reference
- https://en.wikipedia.org/wiki/Cache_(computing)
- https://en.wikipedia.org/wiki/Cache_coherence
- https://coolshell.cn/articles/17416.html
- https://dzone.com/articles/cache-aside-pattern
- https://www.quora.com/Why-does-Facebook-use-delete-to-remove-the-key-value-pair-in-Memcached-instead-of-updating-the-Memcached-during-write-request-to-the-backend
- https://docs.microsoft.com/en-us/azure/architecture/patterns/cache-aside
- https://medium.com/system-design-blog/what-is-caching-1492abb92143
- https://www.ehcache.org/documentation/3.3/caching-patterns.html
- https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
- https://docs.aws.amazon.com/AmazonElastiCache/latest/mem-ug/Strategies.html
- https://medium.datadriveninvestor.com/all-things-caching-use-cases-benefits-strategies-choosing-a-caching-technology-exploring-fa6c1f2e93aa