稀疏索引(Sparse Indexes)
One quality that database indexes can have is that they can be dense or sparse. Each of these index qualities come with their own trade-offs. Let’s look at how each index type would work using the following user data.
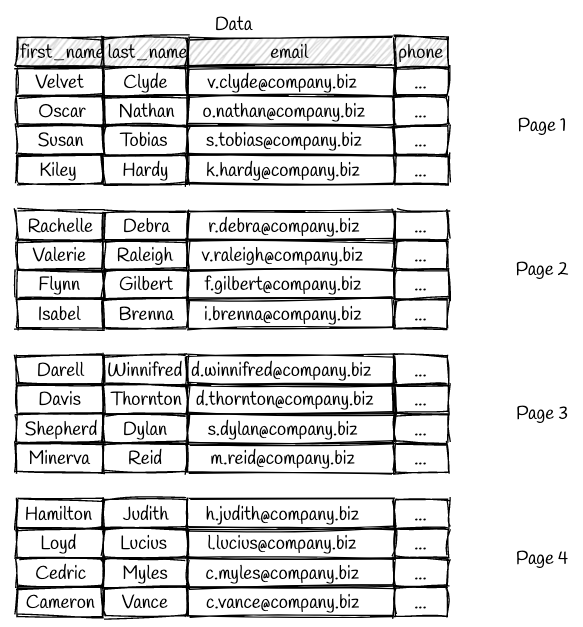
This is a pretty basic table with four columns. For this example, the table is spread across four pages that contain four rows each. We’ll demonstrate an index on the first_name column. Let’s look at the dense index first:
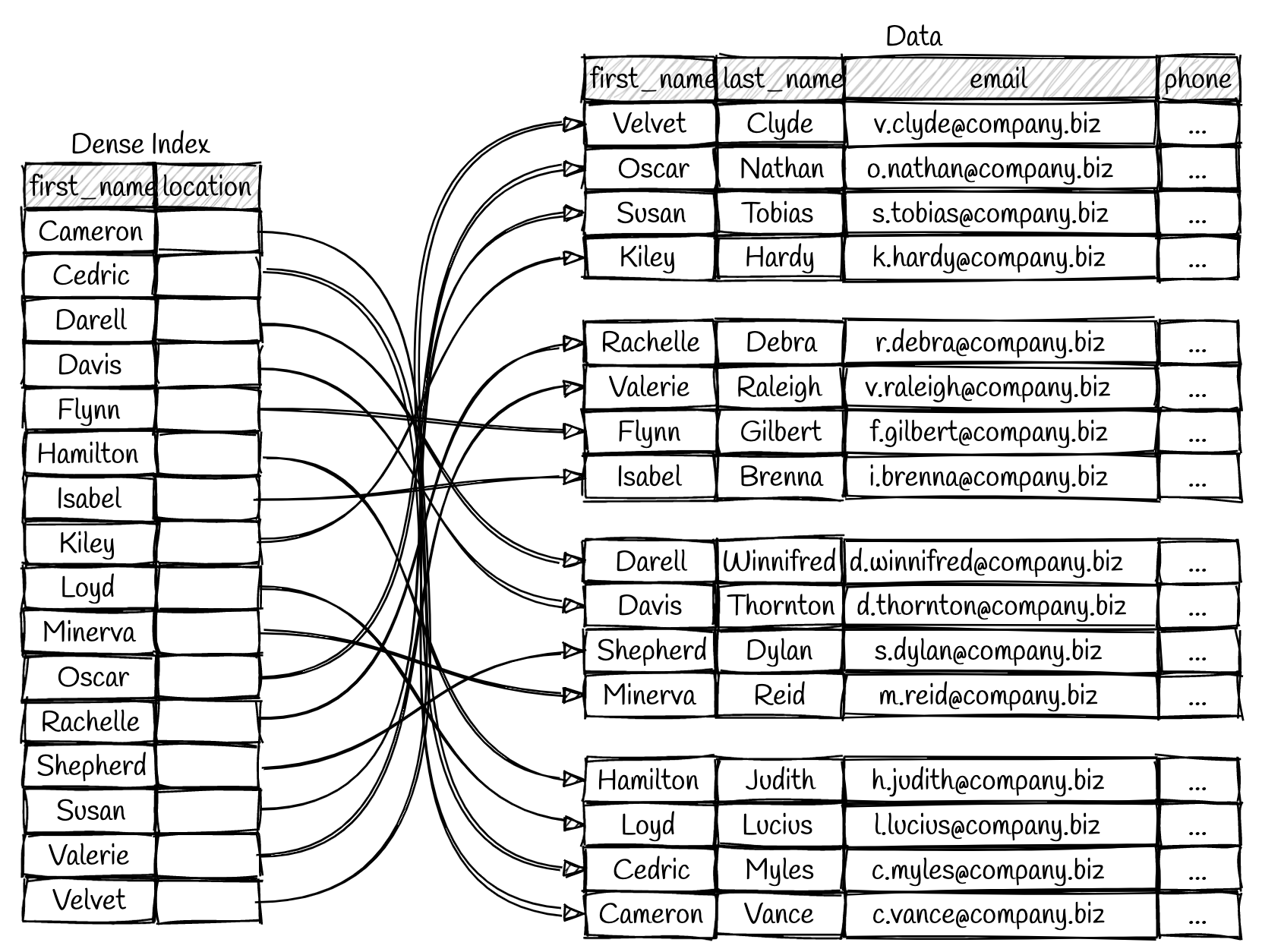
We can see that the index has an entry for every first name in the table. If we want to look up a user with the first name “Rachelle,” then we perform a binary search on the index and read the location of the data. In contrast, a sparse index only has entries for some of the table rows.
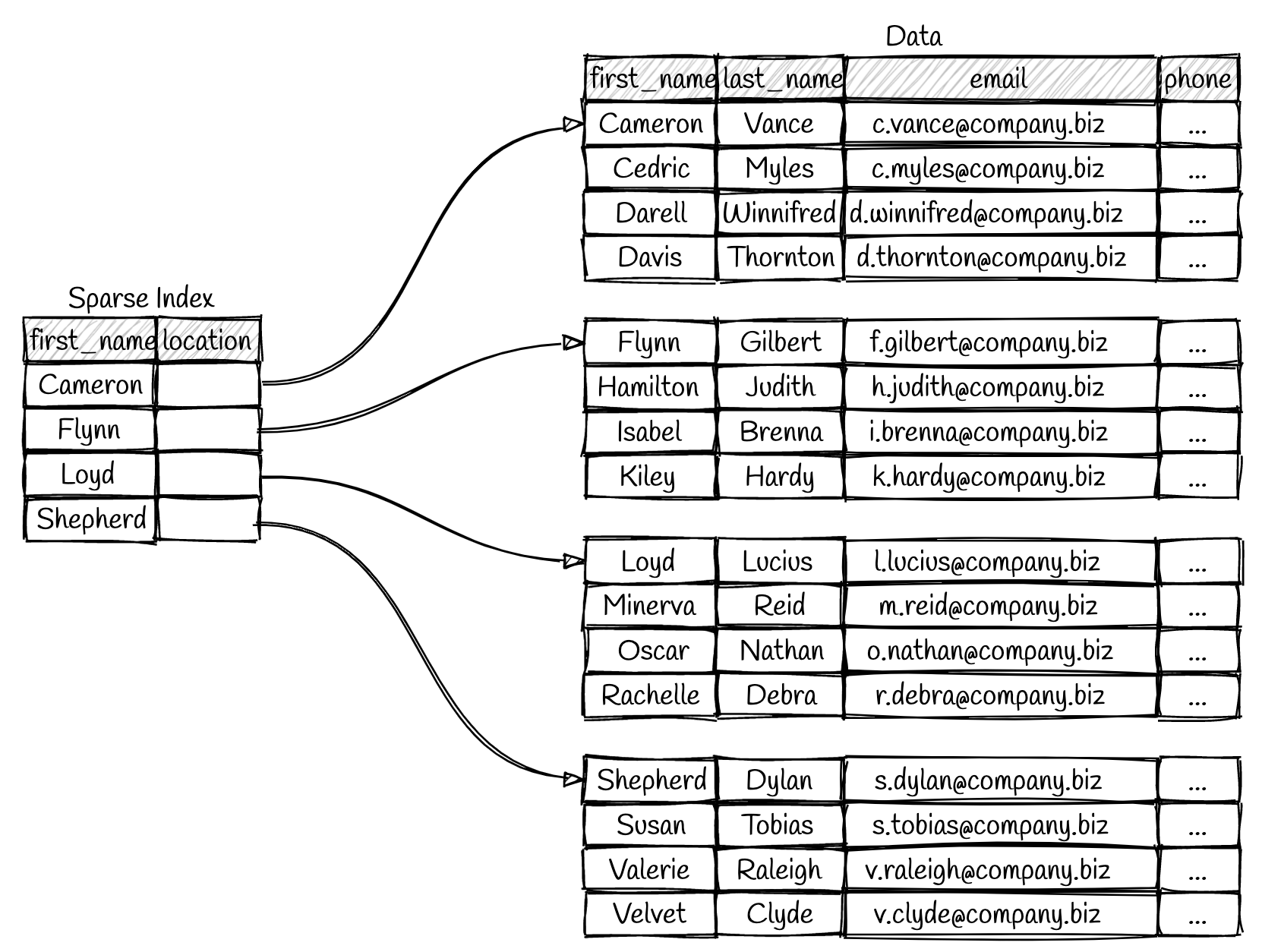
We can see that our sparse index only has four entries (one for each page). Now, if we want to find the row for “Rachelle,” we can perform a binary search on our index to find that it falls between “Loyd” and “Shepherd.” After discovering those bounds, we go to the page starting with “Loyd” and begin scanning for Rachelle’s row. Notice that the data is now sorted on the right side for this example. This sorting is a limitation of the sparse index. A sparse index requires ordered data; otherwise, the scanning step would be impossible.
Conclusion
Dense indexes require more maintenance than sparse indexes at write-time. Since every row must have an entry, the database must maintain the index on inserts, updates, and deletes. Having an entry for every row also means that dense indexes will require more memory. The benefit of a dense index is that values can be quickly found with just a binary search. Dense indexes also do not impose any ordering requirements on the data.
Sparse indexes require less maintenance than dense indexes at write-time since they only contain a subset of the values. This lighter maintenance burden means that inserts, updates, and deletes will be faster. Having fewer entries also means that the index will use less memory. Finding data is slower since a scan across the page typically follows the binary search. Sparse indexes are also only an option when working with ordered data.
| DENSE | SPARSE | |
|---|---|---|
| Maintenance | Requires maintenance on every insert, update, and delete | Only requires maintenance sometimes |
| Memory | Uses more memory | Uses less memory |
| Performance | Faster reads | Faster writes |
| Data Layout | No restriction | Requires ordering |
Use Cases
A Minor Case
Sparse indexes are useful for queries over a small subsection of a table. For example, suppose that you have a table where you store all your customer orders, with the following key attributes:
- Partition key:
CustomerId - Sort key:
OrderId
To track open orders, you can insert an attribute named isOpen in order items that have not already shipped. Then when the order ships, you can delete the attribute. If you then create an index on CustomerId (partition key) and isOpen (sort key), only those orders with isOpen defined appear in it. When you have thousands of orders of which only a small number are open, it’s faster and less expensive to query that index for open orders than to scan the entire table.
Instead of using a type of attribute like isOpen, you could use an attribute with a value that results in a useful sort order in the index. For example, you could use an OrderOpenDate attribute set to the date on which each order was placed, and then delete it after the order is fulfilled. That way, when you query the sparse index, the items are returned sorted by the date on which each order was placed.
Git
https://github.blog/2021-11-10-make-your-monorepo-feel-small-with-gits-sparse-index/
Reference
- https://yetanotherdevblog.com/dense-vs-sparse-indexes/
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-indexes-general-sparse-indexes.html
- https://www.mongodb.com/docs/manual/core/index-sparse/
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-indexes-general-sparse-indexes.html