Consumer Models
通常来讲,消息模型可以分为两种, 队列和发布-订阅式。
- 队列(queue)的处理方式是 一组消费者从服务器读取消息,一条消息只有其中的一个消费者来处理。
- 在发布-订阅模型中,消息被广播给所有订阅该消息的消费者,接收到消息的消费者都可以处理此消息。
Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组(consumer group)。
消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。
- 假如所有的消费者都在一个组中,那么这就变成了queue模型。
- 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。
- 更通用的, 我们可以创建一些消费者组作为逻辑上的订阅者。每个组包含数目不等的消费者, 一个组内多个消费者可以用来扩展性能和容错。正如下图所示:
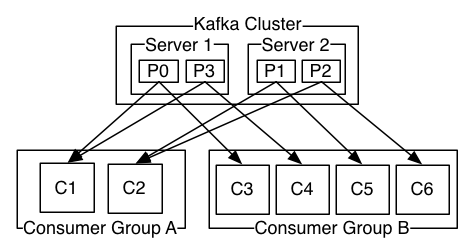
正像传统的消息系统一样,Kafka保证消息的顺序不变。
再详细扯几句。传统的队列模型保持消息,并且保证它们的先后顺序不变。但是, 尽管服务器保证了消息的顺序,消息还是异步的发送给各个消费者,消费者收到消息的先后顺序不能保证了。这也意味着并行消费将不能保证消息的先后顺序。用过传统的消息系统的同学肯定清楚,消息的顺序处理很让人头痛。如果只让一个消费者处理消息,又违背了并行处理的初衷。
在这一点上Kafka做的更好,尽管并没有完全解决上述问题。 Kafka采用了一种分而治之的策略:分区。 因为一个Topic的一个分区中的所有消息只能由一个消费者组中的一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。
所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
顺序问题
正像传统的消息系统一样,Kafka保证消息的顺序不变。
再详细扯几句。传统的队列模型保持消息,并且保证它们的先后顺序不变。但是, 尽管服务器保证了消息的顺序,消息还是异步的发送给各个消费者,消费者收到消息的先后顺序不能保证了。这也意味着并行消费将不能保证消息的先后顺序。用过传统的消息系统的同学肯定清楚,消息的顺序处理很让人头痛。如果只让一个消费者处理消息,又违背了并行处理的初衷。
在这一点上Kafka做的更好,尽管并没有完全解决上述问题。 Kafka采用了一种分而治之的策略:partition。 因为Topic partition中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个partition顺序处理,不能保证跨partition的消息先后处理顺序。
所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个partition。
Consumer Group
Kafka has the concept of consumer groups where several consumers are grouped to consume a given topic. Consumers in the same consumer group are assigned the same group-id value.
The consumer group concept ensures that a message under one topic is only ever read by a single consumer in the consumer group.
When a consumer group consumes the partitions of a topic, Kafka makes sure that each partition is consumed by exactly one consumer in the group.
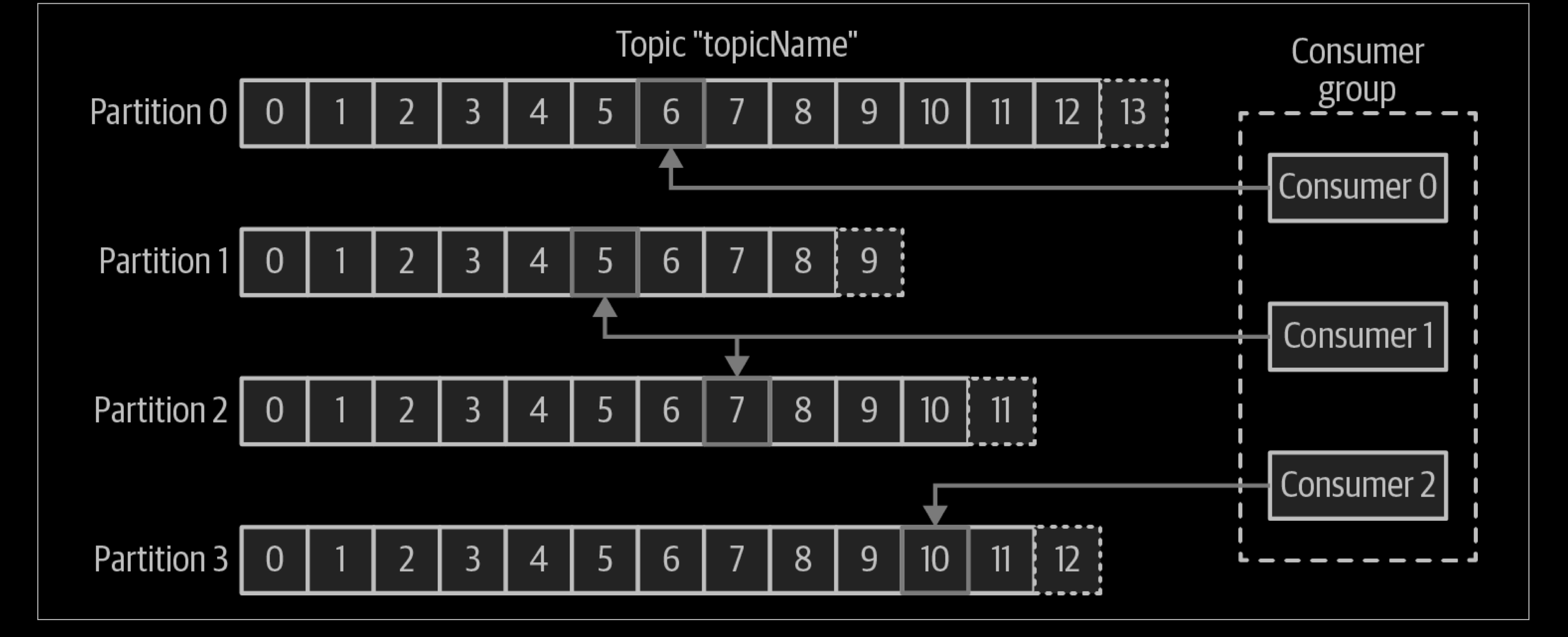
The main way we scale data consumption from a Kafka topic is by adding more consumers to a consumer group. It is common for Kafka consumers to do high-latency operations such as write to a database or a time-consuming computation on the data. In these cases, a single consumer can’t possibly keep up with the rate data flows into a topic, and adding more consumers that share the load by having each consumer own just a subset of the partitions and messages is our main method of scaling. This is a good reason to create topics with a large number of partitions—it allows adding more consumers when the load increases. Keep in mind that there is no point in adding more consumers than you have partitions in a topic—some of the consumers will just be idle.
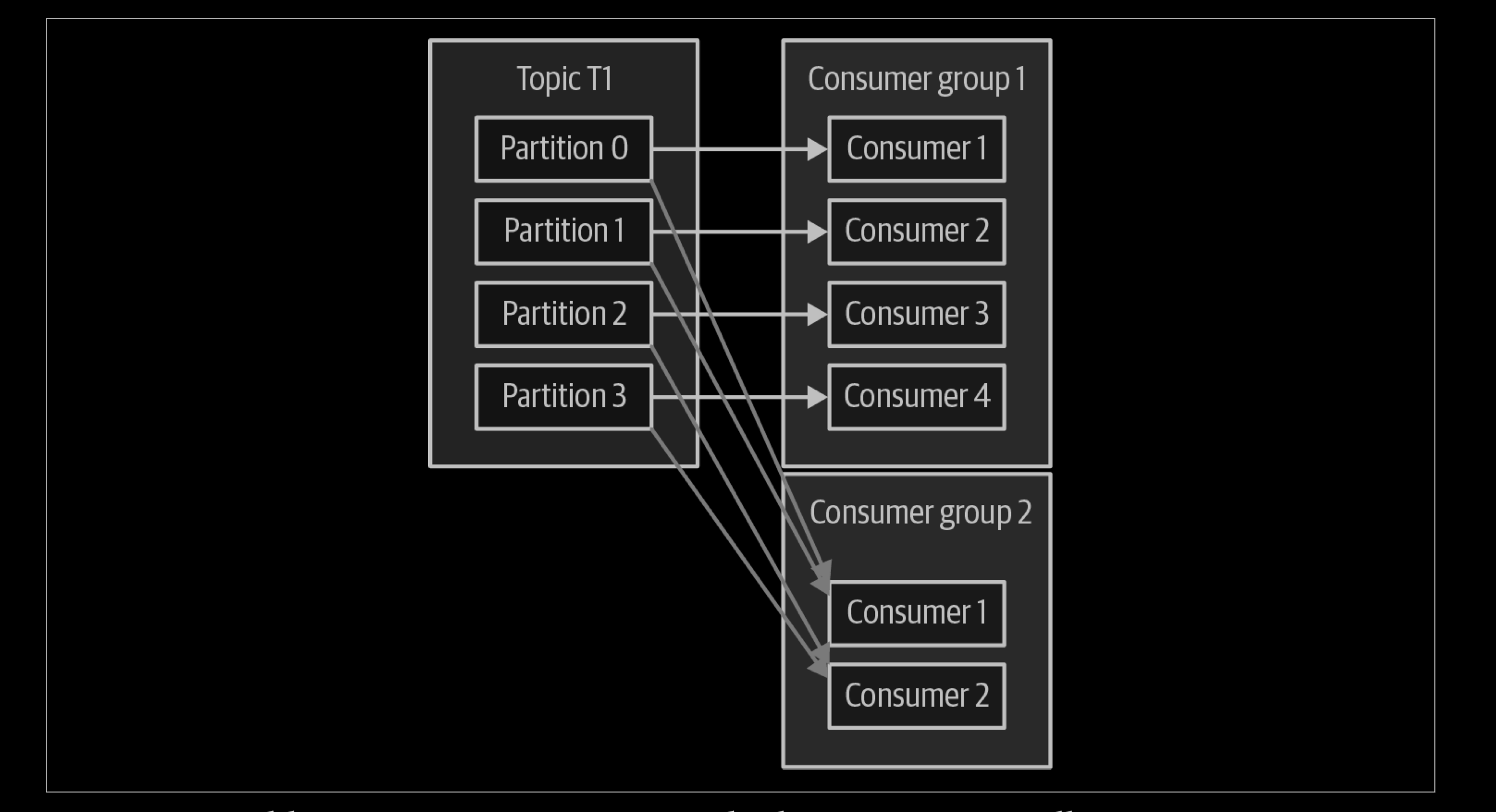
If we add a new consumer group (G2) with a single con‐sumer, this consumer will get all the messages in topic T1 independent of what G1 is doing. G2 can have more than a single consumer, in which case they will each get a subset of partitions, just like we showed for G1, but G2 as a whole will still get all the messages regardless of other consumer groups.
To summarize, you create a new consumer group for each application that needs all the messages from one or more topics. You add consumers to an existing consumer group to scale the reading and processing of messages from the topics, so each additional consumer in a group will only get a subset of the messages.
Consumer Groups and Partition Rebalance
As we saw in the previous section, consumers in a consumer group share ownership of the partitions in the topics they subscribe to. When we add a new consumer to the group, it starts consuming messages from partitions previously consumed by another consumer. The same thing happens when a consumer shuts down or crashes; it leaves the group, and the partitions it used to consume will be consumed by one of the remaining consumers. Reassignment of partitions to consumers also happens when the topics the consumer group is consuming are modified (e.g., if an administrator adds new partitions).
Moving partition ownership from one consumer to another is called a rebalance. Rebalances are important because they provide the consumer group with high availability and scalability (allowing us to easily and safely add and remove consumers), but in the normal course of events they can be fairly undesirable.
There are two types of rebalances, depending on the partition assignment strategy that the consumer group uses:
Eager rebalances
During an eager rebalance, all consumers stop consuming, give up their ownership of all partitions, rejoin the consumer group, and get a brand-new partition assignment. This is essentially a short window of unavailability of the entire consumer group. The length of the window depends on the size of the consumer group as well as on several configuration parameters. Figure 4-6 shows how eager rebalances have two distinct phases: first, all consumers give up their partition assigning, and second, after they all complete this and rejoin the group, they get new partition assignments and can resume consuming.
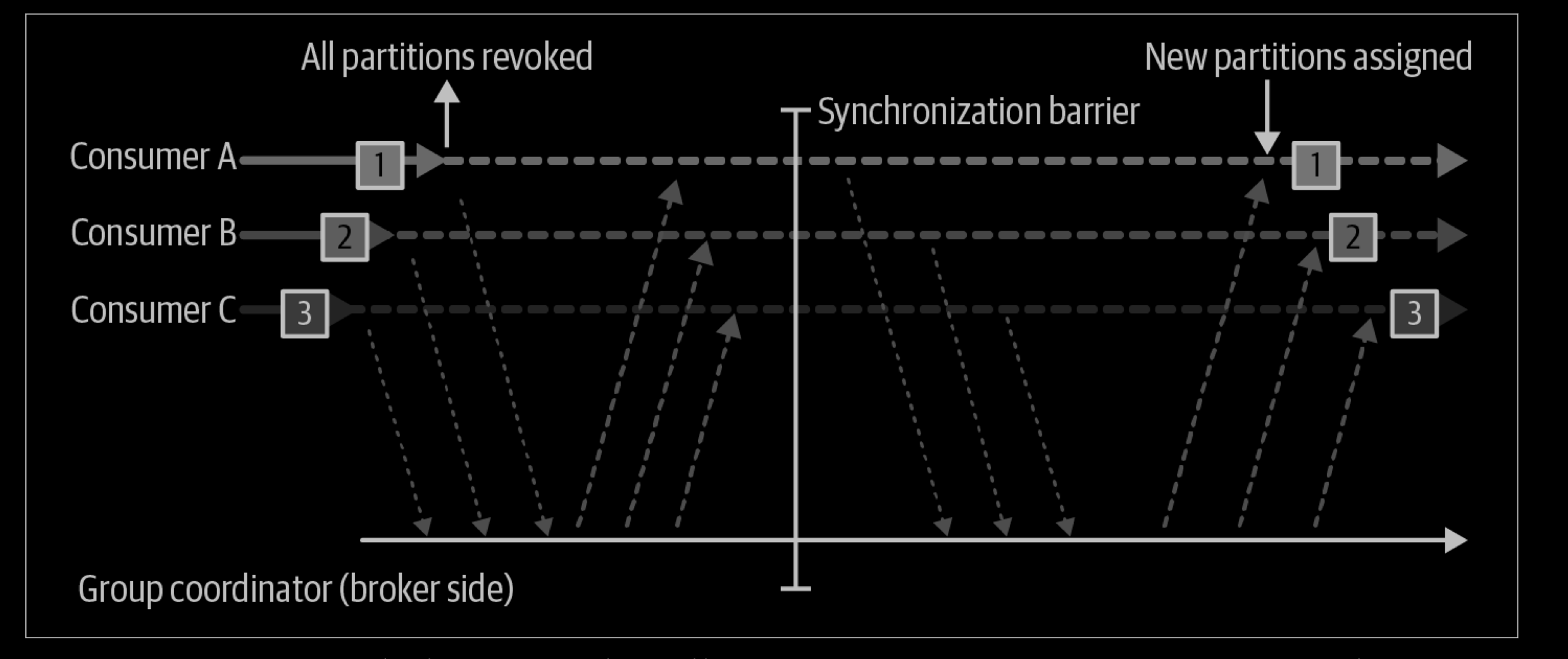
Cooperative rebalances
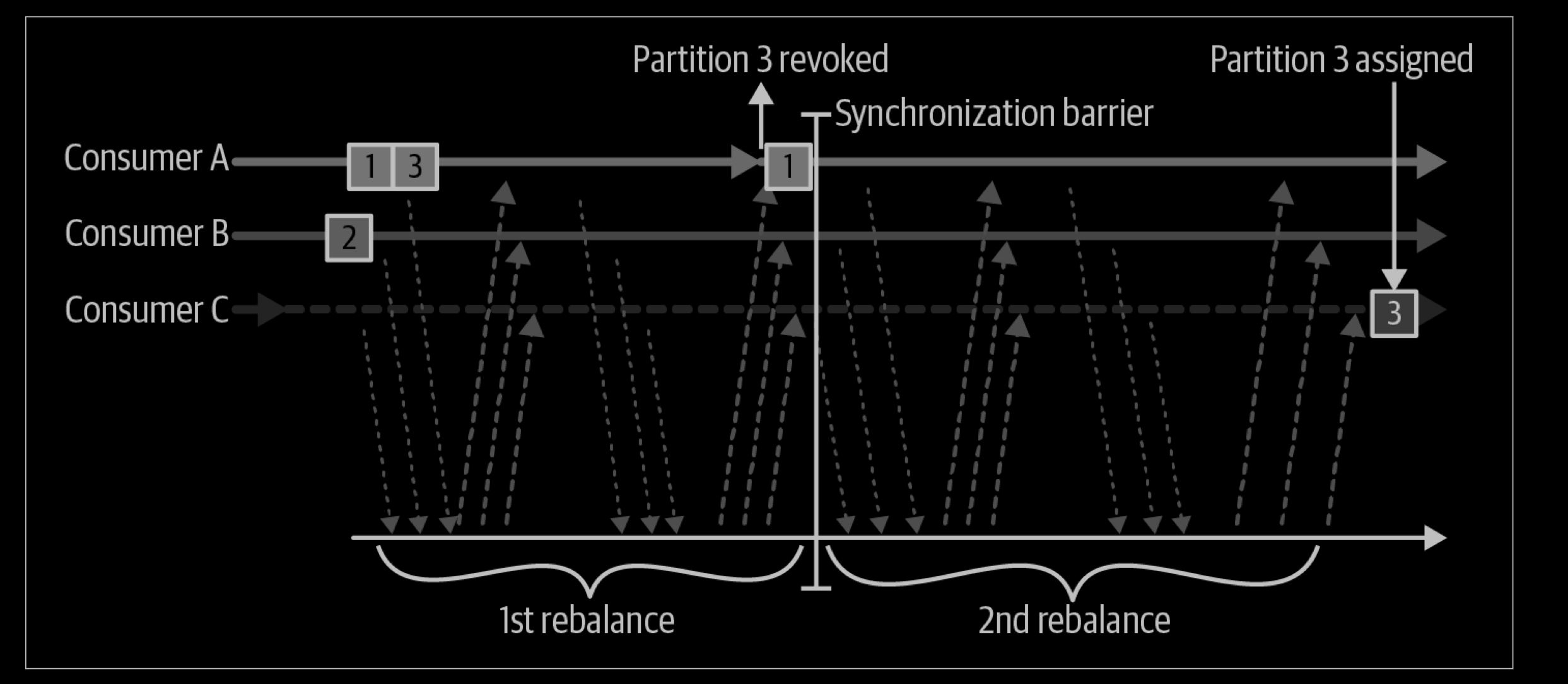
Cooperative rebalances (also called incremental rebalances) typically involve reassigning only a small subset of the partitions from one consumer to another, and allowing consumers to continue processing records from all the partitions that are not reassigned. This is achieved by rebalancing in two or more phases.
Initially, the consumer group leader informs all the consumers that they will lose ownership of a subset of their partitions, then the consumers stop consuming from these partitions and give up their ownership in them. In the second phase, the consumer group leader assigns these now orphaned partitions to their new owners. This incremental approach may take a few iterations until a stable partition assignment is achieved, but it avoids the complete “stop the world” unavailability that occurs with the eager approach. This is especially important in large consumer groups where rebalances can take a significant amount of time. The diagram belowshows how cooperative rebalances are incremental and that only a subset of the consumers and partitions are involved.
Commits and Offsets
Unlike the other pub/sub implementations, Kafka doesn’t push messages to consumers. Instead, consumers have to pull messages off Kafka topic partitions. A consumer connects to a partition in a broker, reads the messages in the order in which they were written.
The offset of a message works as a consumer side cursor at this point. The consumer keeps track of which messages it has already consumed by keeping track of the offset of messages. After reading a message, the consumer advances its cursor to the next offset in the partition and continues. Advancing and remembering the last read offset within a partition is the responsibility of the consumer. Kafka has nothing to do with it.
By remembering the offset of the last consumed message for each partition, a consumer can join a partition at the point in time they choose and resume from there. That is particularly useful for a consumer to resume reading after recovering from a crash.

A partition can be consumed by one or more consumers, each reading at different offsets.
Analysis
Whenever we call poll(), it returns records written to Kafka that consumers in our group have not read yet. This means that we have a way of tracking which records were read by a consumer of the group. As discussed before, one of Kafka’s unique characteristics is that it does not track acknowledgments from consumers the way many JMS queues do. Instead, it allows consumers to use Kafka to track their position (offset) in each partition.
We call the action of updating the current position in the partition an offset commit. Unlike traditional message queues, Kafka does not commit records individually. Instead, consumers commit the last message they’ve successfully processed from a partition and implicitly assume that every message before the last was also successfully processed.
How does a consumer commit an offset? It sends a message to Kafka, which updates a special __consumer_offsets topic with the committed offset for each partition. As long as all your consumers are up, running, and churning away, this will have no impact. However, if a consumer crashes or a new consumer joins the consumer group, this will trigger a rebalance. After a rebalance, each consumer may be assigned a new set of partitions than the one it processed before. In order to know where to pick up the work, the consumer will read the latest committed offset of each partition and continue from there.
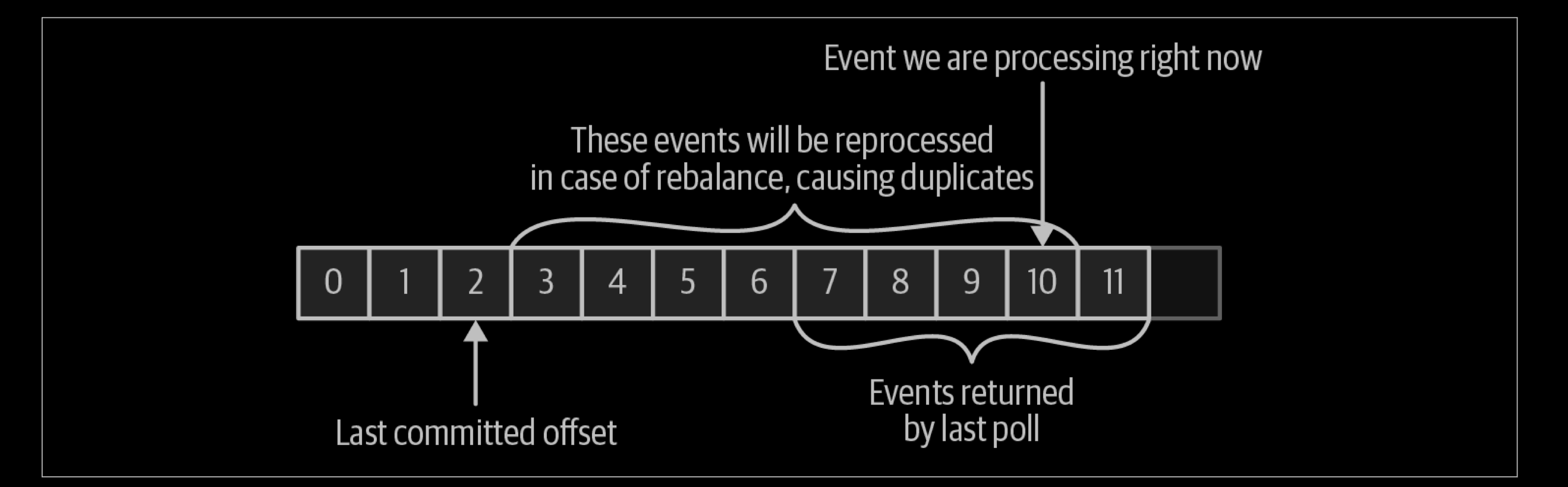
If the committed offset is smaller than the offset of the last message the client pro‐cessed, the messages between the last processed offset and the committed offset will be processed twice. See below:
Automatic Commit
The easiest way to commit offsets is to allow the consumer to do it for you. If you configure enable.auto.commit=true, then every five seconds the consumer will commit the latest offset that your client received from poll(). The five-second interval is the default and is controlled by setting auto.commit.interval.ms. Just like everything else in the consumer, the automatic commits are driven by the poll loop. Whenever you poll, the consumer checks if it is time to commit, and if it is, it will commit the offsets it returned in the last poll.
Before using this convenient option, however, it is important to understand the consequences.
Consider that, by default, automatic commits occur every five seconds. Suppose that we are three seconds after the most recent commit our consumer crashed. After the rebalancing, the surviving consumers will start consuming the partitions that were previously owned by the crashed broker. But they will start from the last offset com‐mitted. In this case, the offset is three seconds old, so all the events that arrived in those three seconds will be processed twice. It is possible to configure the commit interval to commit more frequently and reduce the window in which records will be duplicated, but it is impossible to completely eliminate them.
With autocommit enabled, when it is time to commit offsets, the next poll will commit the last offset returned by the previous poll. It doesn’t know which events were actually processed, so it is critical to always process all the events returned by poll() before calling poll() again. (Just like poll(), close() also commits offsets automati‐cally.) This is usually not an issue, but pay attention when you handle exceptions or exit the poll loop prematurely.
Automatic commits are convenient, but they don’t give developers enough control to avoid duplicate messages.
Commit Current Offset(手动提交)
Most developers exercise more control over the time at which offsets are committed—both to eliminate the possibility of missing messages and to reduce the number of messages duplicated during rebalancing. The Consumer API has the option of committing the current offset at a point that makes sense to the application developer rather than based on a timer.
By setting enable.auto.commit=false, offsets will only be committed when the application explicitly chooses to do so. The simplest and most reliable of the commit APIs is commitSync(). This API will commit the latest offset returned by poll() and return once the offset is committed, throwing an exception if the commit fails for some reason.
It is important to remember that commitSync() will commit the latest offset returned by poll(), so if you call commitSync() before you are done processing all the records in the collection, you risk missing the messages that were committed but not processed, in case the application crashes. If the application crashes while it is still processing records in the collection, all the messages from the beginning of the most recent batch until the time of the rebalance will be processed twice—this may or may not be preferable to missing messages.
Push vs Pull
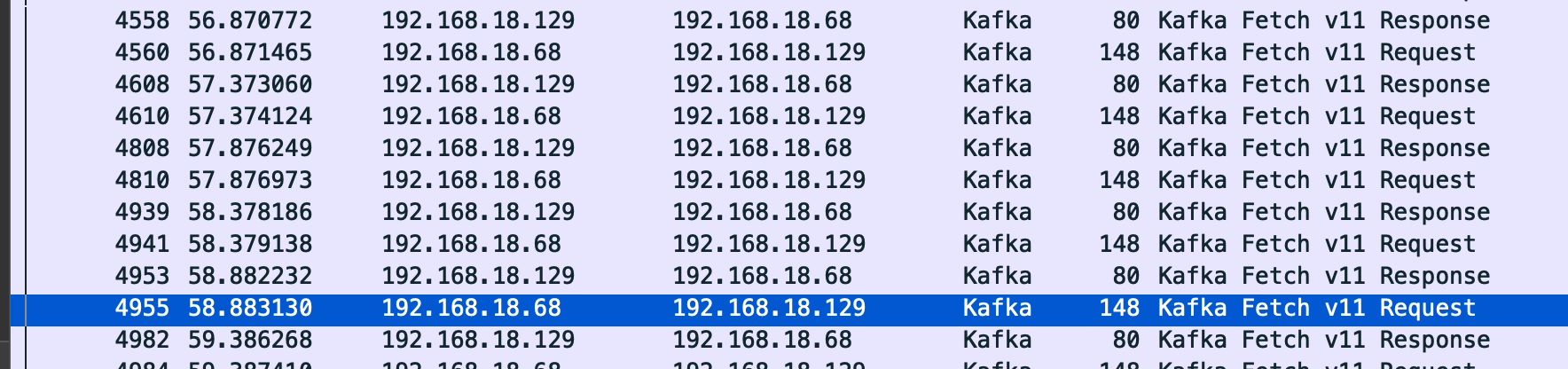
可以看到,当运行下面的consumer之后
$ /usr/local/opt/kafka/bin/kafka-console-consumer --bootstrap-server 192.168.18.129:9092 --topic demo_topic
192.168.18.68 会每500ms去 kafka broker(192.168.18.129) pull/fetch 一次:
An initial question we considered is whether consumers should pull data from brokers or brokers should push data to the consumer. In this respect Kafka follows a more traditional design, shared by most messaging systems, where data is pushed to the broker from the producer and pulled from the broker by the consumer. Some logging-centric systems, such as Scribe and Apache Flume, follow a very different push-based path where data is pushed downstream. There are pros and cons to both approaches. However, a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal is generally for the consumer to be able to consume at the maximum possible rate; unfortunately, in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can. This can be mitigated with some kind of backoff protocol by which the consumer can indicate it is overwhelmed, but getting the rate of transfer to fully utilize (but never over-utilize) the consumer is trickier than it seems. Previous attempts at building systems in this fashion led us to go with a more traditional pull model.
Another advantage of a pull-based system is that it lends itself to aggressive batching of data sent to the consumer. A push-based system must choose to either send a request immediately or accumulate more data and then send it later without knowledge of whether the downstream consumer will be able to immediately process it. If tuned for low latency, this will result in sending a single message at a time only for the transfer to end up being buffered anyway, which is wasteful. A pull-based design fixes this as the consumer always pulls all available messages after its current position in the log (or up to some configurable max size). So one gets optimal batching without introducing unnecessary latency.
The deficiency of a naive pull-based system is that if the broker has no data the consumer may end up polling in a tight loop, effectively busy-waiting for data to arrive. To avoid this we have parameters in our pull request that allow the consumer request to block in a “long poll” waiting until data arrives (and optionally waiting until a given number of bytes is available to ensure large transfer sizes).
You could imagine other possible designs which would be only pull, end-to-end. The producer would locally write to a local log, and brokers would pull from that with consumers pulling from them. A similar type of “store-and-forward” producer is often proposed. This is intriguing but we felt not very suitable for our target use cases which have thousands of producers. Our experience running persistent data systems at scale led us to feel that involving thousands of disks in the system across many applications would not actually make things more reliable and would be a nightmare to operate. And in practice we have found that we can run a pipeline with strong SLAs at large scale without a need for producer persistence.
Partition 分配策略机制
我们知道一个 Consumer Group 中有多个 Consumer,一个 Topic 也有多个 Partition,所以必然会涉及到 Partition 的分配问题: 确定哪个 Partition 由哪个 Consumer 来消费的问题。
Kafka 客户端提供了3 种分区分配策略:RangeAssignor、RoundRobinAssignor 和 StickyAssignor,前两种分配方案相对简单一些StickyAssignor 分配方案相对复杂一些。
RangeAssignor
RangeAssignor 是 Kafka 默认的分区分配算法,它是按照 Topic 的维度进行分配的,对于每个 Topic,首先对 Partition 按照分区ID进行排序,然后对订阅这个 Topic 的 Consumer Group 的 Consumer 再进行排序,之后尽量均衡的按照范围区段将分区分配给 Consumer。此时可能会造成先分配分区的 Consumer 进程的任务过重(分区数无法被消费者数量整除)。
结论:这种分配方式明显的问题就是随着消费者订阅的Topic的数量的增加,不均衡的问题会越来越严重。
RoundRobinAssignor
RoundRobinAssignor 的分区分配策略是将 Consumer Group 内订阅的所有 Topic 的 Partition 及所有 Consumer 进行排序后按照顺序尽量均衡的一个一个进行分配。如果 Consumer Group 内,每个 Consumer 订阅都订阅了相同的Topic,那么分配结果是均衡的。如果订阅 Topic 是不同的,那么分配结果是不保证“尽量均衡”的,因为某些 Consumer 可能不参与一些 Topic 的分配。
StickyAssignor
StickyAssignor 分区分配算法是 Kafka Java 客户端提供的分配策略中最复杂的一种,可以通过 partition.assignment.strategy 参数去设置,从 0.11 版本开始引入,目的就是在执行新分配时,尽量在上一次分配结果上少做调整,其主要实现了以下2个目标:
- Topic Partition 的分配要尽量均衡。
- 当 Rebalance(重分配,后面会详细分析) 发生时,尽量与上一次分配结果保持一致。
**注意:**当两个目标发生冲突的时候,优先保证第一个目标,这样可以使分配更加均匀,其中第一个目标是3种分配策略都尽量去尝试完成的, 而第二个目标才是该算法的精髓所在。
Reference
- Kafka The definition Guide
- https://kafka.apache.org/documentation/