Replication
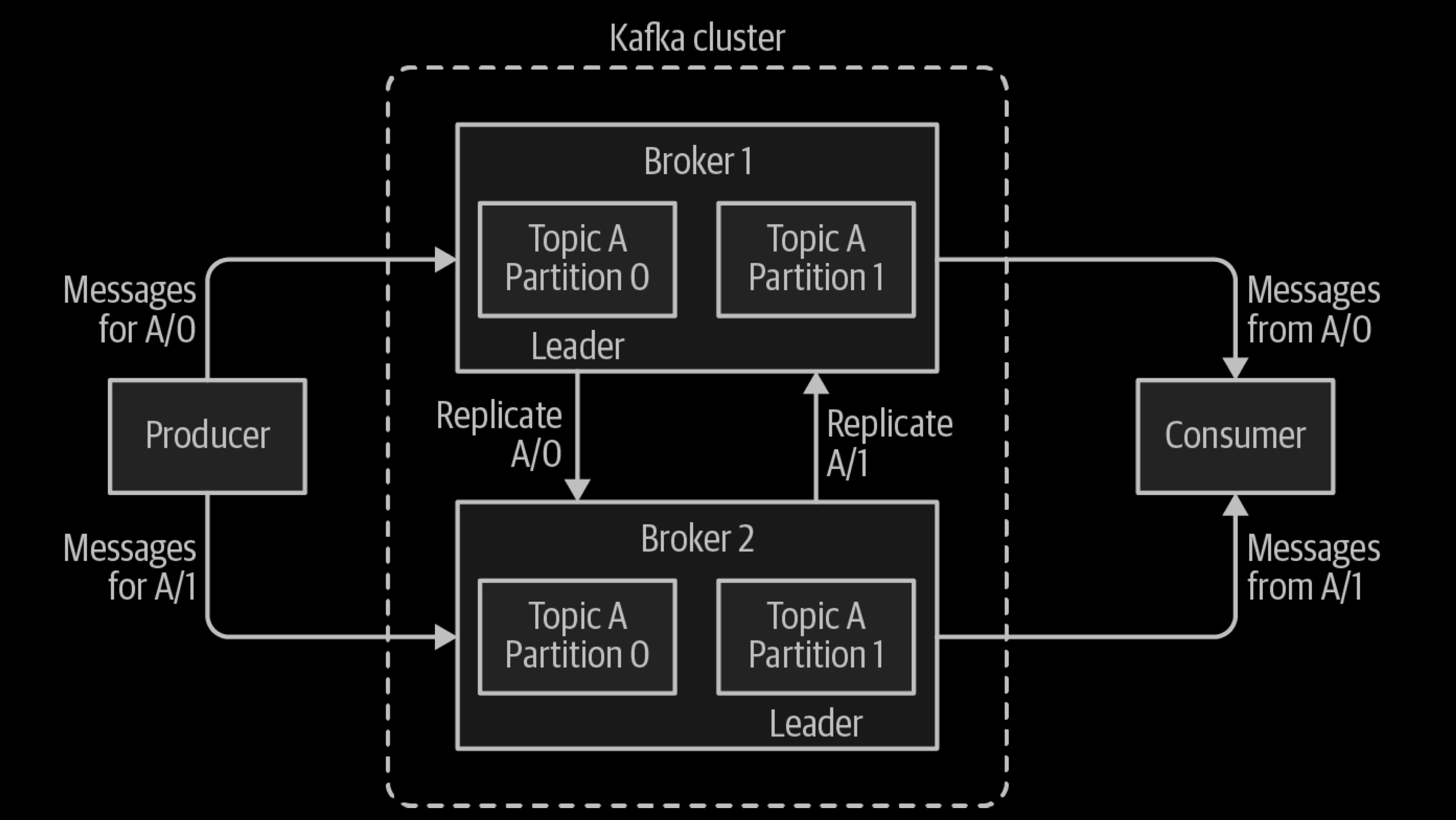
To make your data fault-tolerant and highly-available, every topic can be replicated, even across geo-regions or datacenters, so that there are always multiple brokers that have a copy of the data just in case things go wrong, you want to do maintenance on the brokers, and so on. A common production setting is a replication factor of 3, i.e., there will always be three copies of your data. This replication is performed at the level of topic-partitions.
Ref
Partitions are the way that Kafka provides redundancy.
Kafka keeps more than one copy of the same partition across multiple brokers. This redundant copy is called a replica. If a broker fails, Kafka can still serve consumers with the replicas of partitions that failed broker owned.
In-Sync Replica
What is the ISR?
The ISR is simply all the replicas of a partition that are “in-sync” with the leader. The definition of “in-sync” depends on the topic configuration, but by default, it means that a replica is or has been fully caught up with the leader in the last 10 seconds. The setting for this time period is: replica.lag.time.max.ms and has a server default which can be overridden on a per topic basis.
At a minimum the, ISR will consist of the leader replica and any additional follower replicas that are also considered in-sync. Followers replicate data from the leader to themselves by sending Fetch Requests periodically, by default every 500ms.
If a follower fails, then it will cease sending fetch requests and after the default, 10 seconds will be removed from the ISR. Likewise, if a follower slows down, perhaps a network related issue or constrained server resources, then as soon as it has been lagging behind the leader for more than 10 seconds it is removed from the ISR.
What is ISR for?
The ISR acts as a tradeoff between safety and latency. As a producer, if we really didn’t want to lose a message, we’d make sure that the message has been replicated to all replicas before receiving an acknowledgment. But this is problematic as the loss or slowdown of a single replica could cause a partition to become unavailable or add extremely high latencies. So the goal to be able to tolerate one or more replicas being lost or being very slow.
When a producer uses the “all” value for the acks setting. It is saying: only give me an acknowledgment once all in-sync replicas have the message. If a replica has failed or is being really slow, it will not be part of the ISR and will not cause unavailability or high latency, and we still, normally, get redundancy of our message.
So the ISR exists to balance safety with availability and latency. But it does have one surprising Achilles heel. If all followers are going slow, then the ISR might only consist of the leader. So an acks=all message might get acknowledged when only a single replica (the leader) has it. This leaves the message vulnerable to being lost. This is where the min-insync.replicas broker/topic configuration helps. If it is set it to 2 for example, then if the ISR does shrink to one replica, then the incoming messages are rejected. It acts as a safety measure for when we care deeply about avoiding message loss.
Minimum In-Sync Replica
The minimum number of in-sync replicas specify how many replicas that are needed to be available for the producer to successfully send records to a partition. The number of replicas in your topic is specified by you when creating the topic. The number of replicas specified can be changed in the future.
A high number of minimum in-sync replicas gives a higher persistence, but on the other hand, might reduce availability because the minimum number of replicas given must be available before a publish. If you have a 3 node cluster and the minimum in-sync replicas are set to 3, and one node goes down, the other two nodes will not able to receive any data. Only care about the minimum number of in-sync replicas when it comes to the availability of your cluster and reliability guarantees.
The minimum number of in-sync replicas has nothing to do with the throughput. Setting the minimum number of in-sync replicas to larger than 1 may ensure less or no data loss, but throughput varies depending on the ack value configuration.
Default minimum in-sync replicas are set to 1 by default in CloudKarafka. This means that the minimum number of in-sync replicas that must be available for the producer to successfully send records to a partition must be 1.
Leader failure
There are 3 cases of leader failure which should be considered -
- The leader crashes before writing the messages to its local log. In this case, the client will timeout and resend the message to the new leader.
- The leader crashes after writing the messages to its local log, but before sending the response back to the client
- Atomicity has to be guaranteed: Either all the replicas wrote the messages or none of them
- The client will retry sending the message. In this scenario, the system should ideally ensure that the messages are not written twice. Maybe, one of the replicas had written the message to its local log, committed it, and it gets elected as the new leader.
- The leader crashes after sending the response. In this case, a new leader will be elected and start receiving requests.
When this happens, we need to perform the following steps to elect a new leader.
- Each surviving replica in ISR registers itself in Zookeeper.
- The replica that registers first becomes the new leader. The new leader chooses its LEO as the new HW.
- Each replica registers a listener in Zookeeper so that it will be informed of any leader change. Everytime a replica is notified about a new leader:
- If the replica is not the new leader (it must be a follower), it truncates its log to its HW and then starts to catch up from the new leader.
- The leader waits until all surviving replicas in ISR have caught up or a configured time has passed. The leader writes the current ISR to Zookeeper and opens itself up for both reads and writes.
(Note, during the initial startup when ISR is empty, any replica can become the leader.)
Reference
- Kafka The definition Guide
- https://kafka.apache.org/documentation/
- https://www.cloudkarafka.com/blog/what-does-in-sync-in-apache-kafka-really-mean.html
- https://www.conduktor.io/kafka/kafka-topic-replication/