Partition
A topic could have multiple partitions.
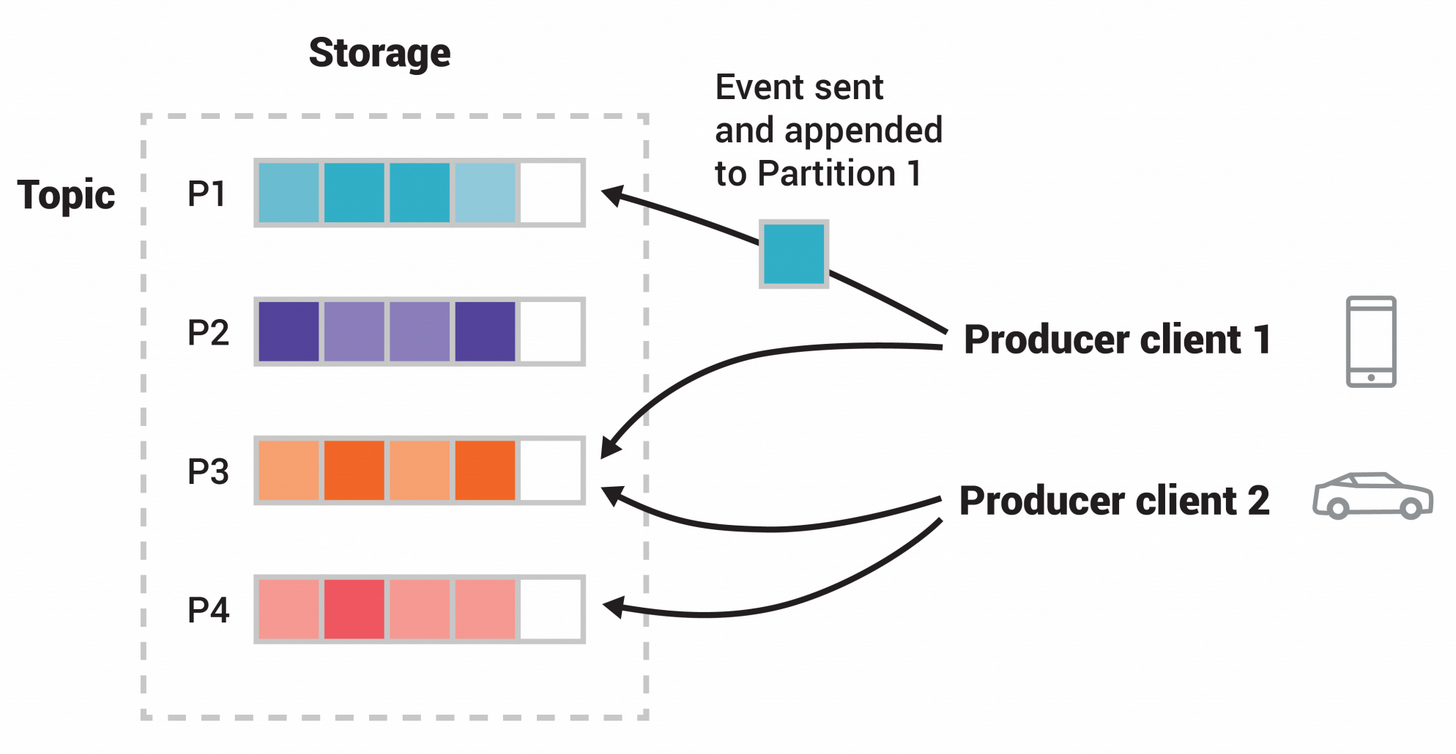
Topics are partitioned, meaning a topic is spread over a number of “buckets” located on different Kafka brokers. This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time. When a new event is published to a topic, it is actually appended to one of the topic’s partitions.
Events with the same event key (e.g., a customer or vehicle ID) are written to the same partition, and Kafka guarantees that any consumer of a given topic-partition will always read that partition’s events in exactly the same order as they were written.
How to decide Partitions
Writing records to partitions
A producer can use a partition key to direct messages to a specific partition. A partition key can be any value that can be derived from the application context. A unique device ID or a user ID will make a good partition key.
By default, the partition key is passed through a hashing function, which creates the partition assignment. That assures that all records produced with the same key will arrive at the same partition. Specifying a partition key enables keeping related events together in the same partition and in the exact order in which they were sent.

Messages with the same partition key will end up at the same partition
Key based partition assignment can lead to broker skew if keys aren’t well distributed.
For example, when customer ID is used as the partition key, and one customer generates 90% of traffic, then one partition will be getting 90% of the traffic most of the time. On small topics, this is negligible, on larger ones, it can sometime take a broker down.
When choosing a partition key, ensure that they are well distributed.
Allowing Kafka to decide the partition
If a producer doesn’t specify a partition key when producing a record, Kafka will use a round-robin partition assignment. Those records will be written evenly across all partitions of a particular topic.
However, if no partition key is used, the ordering of records can not be guaranteed within a given partition.
The key takeaway is to use a partition key to put related events together in the same partition in the exact order in which they were sent.
Writing a custom partitioner
In some situations, a producer can use its own partitioner implementation that uses other business rules to do the partition assignment.
How to decide Partition Num

Consumer groups enable consumers to parallelize and process messages at very high throughputs. However, the maximum parallelism of a group will be equal to the number of partitions of that topic.
For example, if you have N + 1 consumers for a topic with N partitions, then the first N consumers will be assigned a partition, and the remaining consumer will be idle, unless one of the N consumers fails, then the waiting consumer will be assigned its partition. This is a good strategy to implement a hot failover.
The figure below illustrates this.

The key takeaway is that number of consumers don’t govern the degree of parallelism of a topic. It’s the number of partitions.
Analysis
There are several factors to consider when choosing the number of partitions:
- What is the throughput you expect to achieve for the topic? For example, do you expect to write 100 KBps or 1 GBps?
- What is the maximum throughput you expect to achieve when consuming from a single partition? A partition will always be consumed completely by a single consumer (even when not using consumer groups, the consumer must read all messages in the partition). If you know that your slower consumer writes the data to a database and this database never handles more than 50 MBps from each thread writing to it, then you know you are limited to 50 MBps throughput when consuming from a partition.
- You can go through the same exercise to estimate the maximum throughput per producer for a single partition, but since producers are typically much faster than consumers, it is usually safe to skip this.
- If you are sending messages to partitions based on keys, adding partitions later can be very challenging, so calculate throughput based on your expected future usage, not the current usage.
- Consider the number of partitions you will place on each broker and available diskspace and network bandwidth per broker.
- Avoid overestimating, as each partition uses memory and other resources on the broker and will increase the time for metadata updates and leadership transfers.
- Will you be mirroring data? You may need to consider the throughput of your mirroring configuration as well. Large partitions can become a bottleneck in many mirroring configurations.
- If you are using cloud services, do you have IOPS (input/output operations per second) limitations on your VMs or disks? There may be hard caps on the number of IOPS allowed depending on your cloud service and VM configuration that will cause you to hit quotas. Having too many partitions can have the side effect of increasing the amount of IOPS due to the parallelism involved.
With all this in mind, it’s clear that you want many partitions, but not too many. If you have some estimate regarding the target throughput of the topic and the expected throughput of the consumers, you can divide the target throughput by the expected consumer throughput and derive the number of partitions this way. So if we want to be able to write and read 1 GBps from a topic, and we know each consumer can only process 50 MBps, then we know we need at least 20 partitions. This way, we can have 20 consumers reading from the topic and achieve 1 GBps.
If you don’t have this detailed information, our experience suggests that limiting the size of the partition on the disk to less than 6 GB per day of retention often gives satisfactory results. Starting small and expanding as needed is easier than starting too large.
Reference
- Kafka The definition Guide
- https://kafka.apache.org/documentation/