select
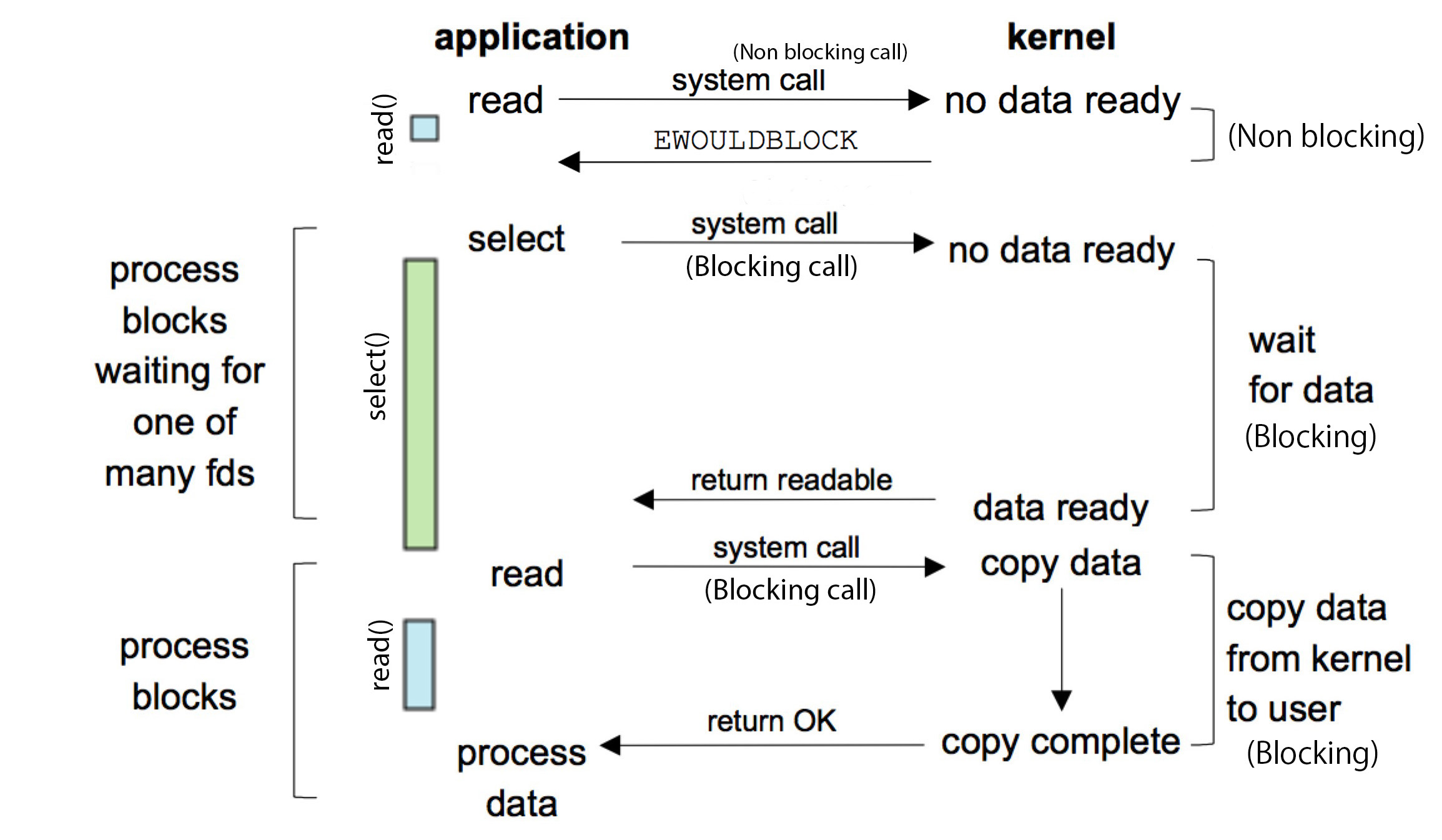
select是基于I/O多路复用模型。select 可以让内核在"多个 fd 对应的I/O操作中任何一个“就绪"(指数据已经被拷贝到kernel space)或"经过指定时间后",唤醒(wake)并通知用户线程(在唤醒之前,用户线程因为被阻塞而处于sleep状态)。比如:
- 当1、4或5中任何一个 fd 的状态为可读时
- 或当4、7中任何一个 fd 的状态为可写时
- 或当6、8中任何一个 fd 的处理过程中抛出异常时
- 或经过10.2秒后
注意,select仅仅负责轮询工作:
- 在调用
select()之前,需要调用read()以发起一个读取I/O操作(此后才需要轮询操作); - 在调用
select()之后,需要再次调用read()以将数据从内核空间读取到用户空间,并最终将数据返回给用户线程
#include <sys/select.h>
int select (int n,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
FD_CLR(int fd, fd_set *set);
FD_ISSET(int fd, fd_set *set);
FD_SET(int fd, fd_set *set);
FD_ZERO(fd_set *set);
n是一个int类型,为值最大的 fd 的数值。比如我想监控1、3、8、10这四个 fd ,则n为10。
总结
- 它是在
read的基础上改进的一种方案,通过对 fd 上的事件状态来进行判断; - 以同步的方式实现了I/O多路复用;
- 调用
select()时,需要指定三组期望被观察的 fd 集合(readfds、writefds和exceptfds)。
解释
- 期望被观察的 fd 分为三组,对于
readfds,被包含在readfds集合中 fd 会被内核观察,当任何一个 fd 的状态变化为数据可读时,select()函数被返回;类似地,对于writefds,当这个集合中任何一个 fd 的状态变化为数据可写时,select()函数被返回;对于exceptfds,当其中的任何一个 fd 的处理抛出异常时; - 当
select()函数被返回时,三组 fd 集合会被修改,即**只包含那些对应数据已经准备完成的 fd **。比如,readfdsfd 集合中包含7和9两个 fd ,当select()函数被返回时,只有 fd 7包含在新的readfdsfd 集合中(因为,此时只有 fd 7对应的I/O操作完成了,即数据可用)。 select()会返回在三组期望被观察的 fd 集合(readfds、writefds和exceptfds)中,已经准备就绪的 fd 的数量的总和。如果发生错误,则返回-1。- 在
select()中,如果仅仅检测一个值为900的 fd 时,内核需要从0开始扫描各个 fd ,直到第900个(在调用select()时,需要传入值最大的 fd 的数字)
更多细节请查询《Linux System Programming Talking Directly to the Kernel and C Library》P53。
Select 的缺点
- 每次调用 select,都需要把待监听的 fd 集合从用户态拷贝到内核态,这个开销在 fd 很多时会非常大
- 每次调用select时 kernel 都需要线性扫描整个 fd_set,所以随着监控的描述符 fd 数量增长,其 I/O 性能会线性下降
poll 的实现和 select 非常相似,只是描述 fd 集合的方式不同,poll 使用 pollfd 结构而不是 select 的 fd_set 结构,poll 解决了最大文件描述符数量限制的问题,但是同样需要从用户态拷贝所有的 fd 到内核态,也需要线性遍历所有的 fd 集合,所以它和 select 只是实现细节上的区分,并没有本质上的区别。
Reference
FEATURED TAGS
algorithm
algorithmproblem
architecturalpattern
architecture
aws
blockchain
c#
cachesystem
codis
compile
concurrentcontrol
database
dataformat
datastructure
debug
design
designpattern
distributedsystem
django
docker
domain
engineering
freebsd
git
golang
grafana
hackintosh
hadoop
hardware
hexo
http
hugo
ios
iot
java
javaee
javascript
kafka
kubernetes
linux
linuxcommand
linuxio
lock
macos
markdown
microservices
mysql
nas
network
networkprogramming
nginx
node.js
npm
oop
openwrt
operatingsystem
padavan
performance
programming
prometheus
protobuf
python
redis
router
security
shell
software testing
spring
sql
systemdesign
truenas
ubuntu
vmware
vpn
windows
wmware
wordpress
xml
zookeeper