JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。
那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。
JavaScript的单线程模型
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
更准确地说,在Node中只有一个线程执行JavaScript代码,Event Loop中触发所有的回调函数也运行在这个线程中。在浏览器中,指的是 JavaScript执行线程与UI渲染共用的一个线程。
在浏览器中,由于浏览器中JavaScript与UI渲染共用一个线程,JavaScript长时间执行会导致UI的渲染和响应被中断。在Node中,长时间占用CPU的同步任务也会导致后续的同步任务不能被及时执行,已完成的异步I/O的回调函数也会得不到及时调用。
而且,在Node中,主线程与其余线程是无法共享任何状态的。单线程的最大好处是不用像多线程编程那样处处在意状态的同步问题,没有死锁的存在,也没有线程上下文交换所带来的性能上的开销。
一个需要强调的地方在于我们时常提到Node是单线程的, 这里的单线程仅仅只是 JavaScript执行在单线程中罢了(而不是指一个Node进程中永远都只有一个线程)。而事实上,Node进程自身其实是多线程的。无论是*nix还是Windows平台,内部完成I/O任务的另有线程池。
单线程的不足
同样,单线程也有它自身的不足。单线程的不足具体在以下三方面:
- 无法利用多核CPU。
- 错误会引起整个应用退出,应用的健壮性值得考验。
- 具体来说,Node.js 会在一个线程中处理大量请求,如果处理某个请求时,产生了一个没有被捕获到的异常,这将会导致整个Node进程的退出,已经接收到的其它连接全部都无法处理,对一个 Web 服务器来说,这绝对是致命的灾难
- 而在如Tomcat等基于per Thread per Request的模型中,每个 request 都在单独的线程中处理,即使某一个请求发生很严重的错误也不会影响到其它请求
- 大量计算占用CPU导致无法继续调用异步I/O。
一个体现Node单线程不足的例子
function fibonacci(n) {
if(n==0 || n == 1)
return n;
return fibonacci(n-1) + fibonacci(n-2);
}
var timeoutScheduled = Date.now();
var result=fibonacci(45);
const delay = Date.now() - timeoutScheduled;
console.log("finish fibonacci");
console.log(`${delay}ms fibonacci`);
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log('setTimeout');
console.log(`${delay}ms setTimeout`);
}, 5);
setImmediate(() => {
const delay = Date.now() - timeoutScheduled;
console.log('setImmediate1');
console.log(`${delay}ms setImmediate1`);
});
setImmediate(() => {
const delay = Date.now() - timeoutScheduled;
console.log('setImmediate2');
console.log(`${delay}ms setImmediate2`);
});
process.nextTick(() => {
const delay = Date.now() - timeoutScheduled;
console.log('process.nextTick');
console.log(`${delay}ms process.nextTick`);
});
输出:
$ node main.js
finish fibonacci
13010ms fibonacci
process.nextTick
13014ms process.nextTick
setImmediate1
13014ms setImmediate1
setImmediate2
13014ms setImmediate2
setTimeout
13018ms setTimeout
可以明显看到所有的异步操作(easy task)均被Fibonacci的计算(difficult task)阻塞了,如下图所示:
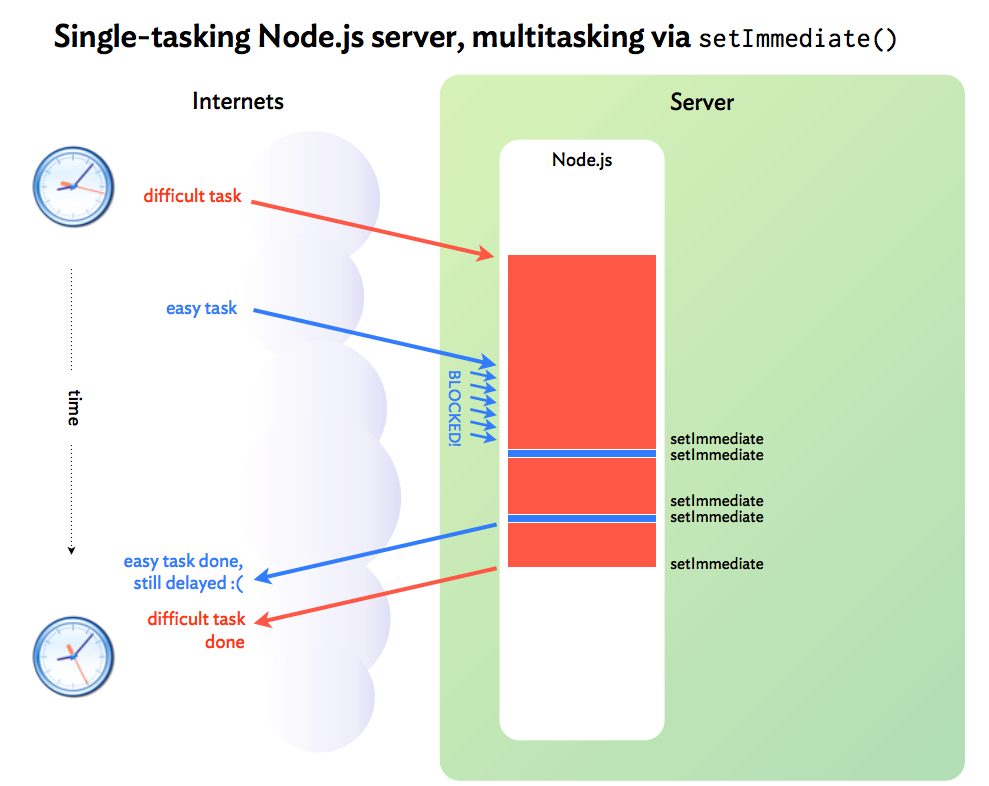
这是一个典型的CPU密集型(CPU intensive)场景,Node.js为了解决在CPU密集型应用中,异步回调被长期阻塞的问题,引入了多进程机制。
因此,我们通过总结Node 的两种不同应用场景来讨论解决方案。
Node 的应用场景
关于Node,探讨得较多的主要有I/O密集型和CPU密集型。
I/O密集型
Node擅长I/O密集型的应用场景基本上是没人反对的。Node面向网络且擅长并行I/O,能够有效地组织起更多的硬件资源,从而提供更多的服务。
I/O密集的优势主要在于Node利用事件循环(Event Loop)的处理能力,而不是启动每一个线程为每一个请求服务,资源占用极少。
CPU密集型
CPU密集型应用给Node 带来的挑战主要是:由于JavaScript单线程的原因,如果有长时间运行的计算(比如大循环),将会导致CPU时间片不能释放,使得后续I/O无法发起。
上面讨论的Fibonacci的例子,就是一个典型的CPU密集型场景。
然而,Node为我们提供了解决方案,即通过适当调整和分解大型运算任务为多个小任务,运算能够适时释放,从而不阻塞I/O调用的发起。这样既可同时享受到并行异步I/O的好处,又能充分利用CPU。
关于CPU密集型应用,Node的异步I/O已经解决了在单线程上CPU与I/O之间阻塞无法重叠利用的问题, I/O阻塞造成的性能浪费远比CPU的影响小。对于长时间运行的计算,如果它的耗时超过普通阻塞I/O的耗时,那么应用场景就需要重新评估,因为这类计算比阻塞I/O还影响效率,甚至说就是一个纯计算的场景,根本没有I/O。
此类应用场景可采用创建多进程或者编写C/C++扩展的方式进行解决。来实现充分利用CPU。
- 通过子进程的方式,将一部分Node进程当做常驻服务进程用于计算,然后利用进程间的消息来传递结果,将计算与I/O分离,这样还能充分利用多CPU。
- Node可以通过编写C/C++扩展的方式更高效地利用CPU,将一些V8不能做到性能极致的地方通过C/C++来实现。由上面的测试结果可以看到,通过C/C++扩展的方式实现斐波那契数列计算,速度比Java还快。
Node中创建多进程
由于Node基于单线程,当Node进行大量计算(CPU密集型计算)时,会因为已完成的异步I/O的回调函数会得不到及时执行,而导致应用在较长时间内无响应。同时,Node无法利用现代CPU的多个核。
child_process 模块 - 创建子进程
为了解决这个问题,Node采用了与HTML5 的Web Workers中相同的思路来解决因单线程设计而导致的不足。即允许使用子进程(child_process),Node 提供了 child_process 模块来创建子进程。
通过将计算分发到各个子进程,可以将大量计算分解掉,然后再通过进程之间的事件消息来传递结果(即消息传递的方式来传递运行结果),这可以很好地保持应用模型的简单和低依赖。通过Master-Worker的管理方式,也可以很好地管理各个工作进程,以达到更高的健壮性。
一个Demo
master.js
const fs = require('fs');
const child_process = require('child_process');
for(var i=0; i<3; i++) {
var workerProcess = child_process.exec('node support.js '+i, function (error, stdout, stderr) {
if (error) {
console.log(error.stack);
console.log('Error code: '+error.code);
console.log('Signal received: '+error.signal);
}
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
});
workerProcess.on('exit', function (code) {
console.log('子进程已退出,退出码 '+code);
});
}
support.js
console.log("进程 " + process.argv[2] + " 执行。" );
cluster 模块 - 创建子进程
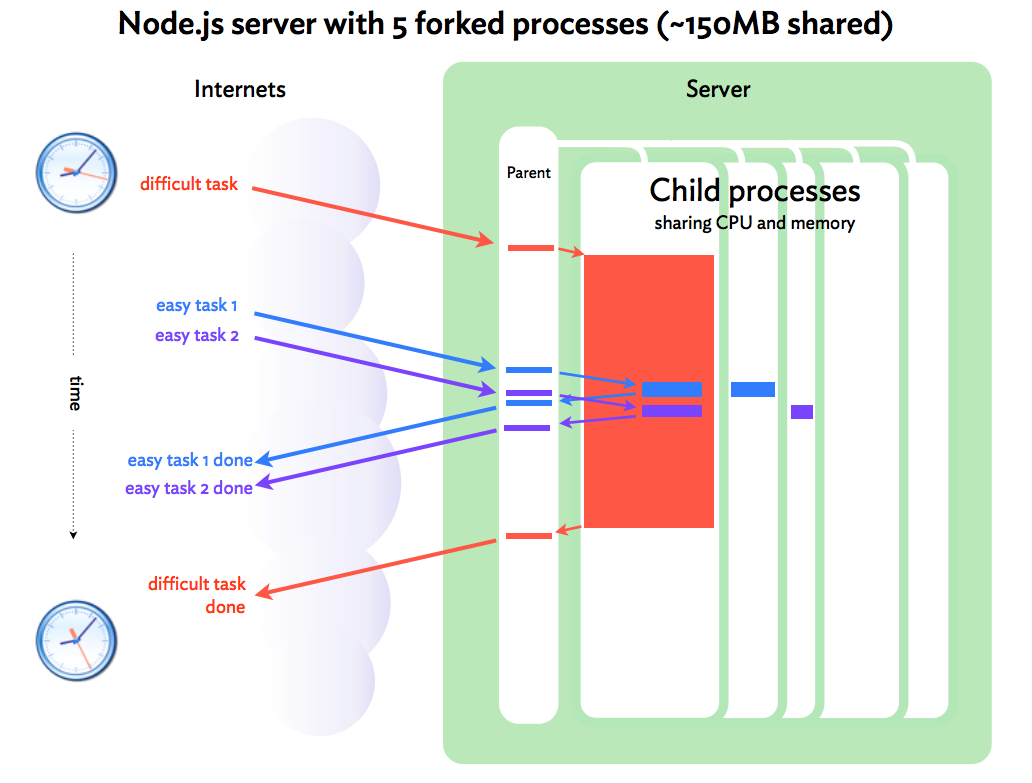
除此之外,还可以使用cluster 模块。cluster 模块对 child_process 模块提供了一层封装,可以说是为了发挥服务器多核优势而量身定做的。
cluster 模块的工作的结构很简单。我们创建一个主进程并且主进程衍生(fork)了一些工作进程(worker process),然后管理它们。每一个工作进程代理表了一个我们想要扩展的应用的一个实例。所有到来的请求都被主进程所处理,它决定着哪一个工作进程应该处理一个到来的请求。
简单的一个 fork方法,不需要开发者修改任何的应用代码便能够实现多进程部署。
cluster用起来更加简单便捷。虽然cluster模块繁衍线程实际上用的也是child_process.fork,但它对资源的管理要比我们自己直接用child_process.fork管理得更好。
fork 是 cluster 模块中非常重要的一个方法,底层是依赖*nix的 fork 函数来实现的。 多个子进程便是通过在master进程中不断的调用 cluster.fork 方法构造出来。
最初的 Node.js 多进程模型就是这样实现的,master 进程创建 socket,绑定到某个地址以及端口后,自身不调用 listen 来监听连接以及 accept 连接,而是将该 socket 的 fd 传递到 fork 出来的 worker 进程,worker 接收到 fd 后再调用 listen,accept 新的连接。但实际一个新到来的连接最终只能被某一个 worker 进程 accpet 再做处理,至于是哪个 worker 能够 accept 到,开发者完全无法预知以及干预。这势必就导致了当一个新连接到来时,多个 worker 进程会产生竞争,最终由胜出的 worker 获取连接。
var cluster = require('cluster'),
…
// heroku config compatible
var MAX_PROCESSES = process.env.MAX_PROCESSES || 5;
…
if (cluster.isMaster) {
// fork!
for (var i = 0; i < MAX_PROCESSES; i++) {
cluster.fork();
}
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
})
} else {
http.createServer(app).listen(app.get('port'), function(){
console.log("Express server listening on port " + app.get('port'));
});
}
线程池
Reference
- 《深入浅出Node.js》
- cluster 模块 - http://taobaofed.org/blog/2015/11/03/nodejs-cluster/
- CPU密集型任务 - http://www.infoq.com/cn/articles/nodejs-weakness-cpu-intensive-tasks
- 浅析 Node.js 在 CPU 密集型问题上应用 - https://www.ibm.com/developerworks/cn/opensource/os-cn-nodejscpu/index.html
- Running CPU Intensive task in Nodejs - https://medium.com/@badewakayode/running-cpu-intensive-task-in-nodejs-db4f995db310
- Overview of Blocking vs Non-Blocking - https://nodejs.org/en/docs/guides/blocking-vs-non-blocking/
- 当我们谈论 cluster 时我们在谈论什么(下)http://taobaofed.org/blog/2015/11/10/nodejs-cluster-2/
- https://neilk.net/projects/letterpwn/letterpwn-node-brigade.pdf
- http://taobaofed.org/blog/2015/11/03/nodejs-cluster/
- http://www.alloyteam.com/2015/08/nodejs-cluster-tutorial/
- https://zhuanlan.zhihu.com/p/36728299
- https://zhuanlan.zhihu.com/p/41118827
- https://cnodejs.org/topic/518b679763e9f8a5424406e9
- https://bjouhier.wordpress.com/2012/03/11/fibers-and-threads-in-node-js-what-for/