Online Transaction Processing
Online transaction processing (OLTP) is a type of database system used in transaction-oriented applications, such as many operational systems. “Online” refers to that such systems are expected to respond to user requests and process them in real-time (process transactions). The term is contrasted with online analytical processing (OLAP) which instead focuses on data analysis (for example planning and management systems).
OLTP systems use a relational database that can do the following:
- Process a large number of relatively simple transactions — usually insertions, updates and deletions to data.
- Enable multi-user access to the same data, while ensuring data integrity.
- Support very rapid processing, with response times measured in milliseconds.
- Provide indexed data sets for rapid searching, retrieval and querying.
- Be available 24/7/365, with constant incremental backups.
Use
OLTP has also been used to refer to processing in which the system responds immediately to user requests. An automated teller machine (ATM) for a bank is an example of a commercial transaction processing application. Online transaction processing applications have high throughput and are insert- or update-intensive in database management. These applications are used concurrently by hundreds of users. The key goals of OLTP applications are availability, speed, concurrency and recoverability (durability).
Online Analytical Processing (OLAP)
OLAP, or online analytical processing, is technology for performing high-speed complex queries or multidimensional analysis on large volumes of data in a data warehouse, data lake or other data repository.
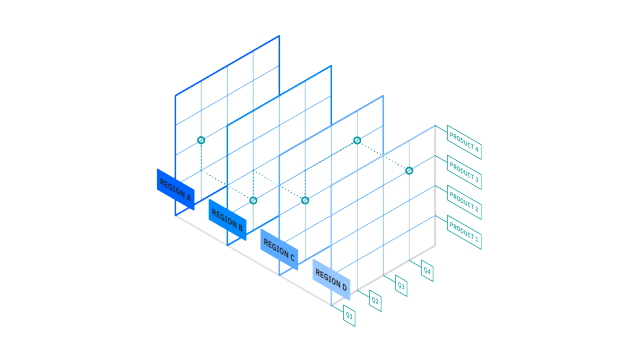
The core of most OLAP databases is the OLAP cube, which allows you to quickly query, report on and analyze multidimensional data. What’s a data dimension? It’s simply one element of a particular dataset. For example, sales figures might have several dimensions related to region, time of year, product models and more.
The OLAP cube extends the row-by-column format of a traditional relational database schema and adds layers for other data dimensions. For example, while the top layer of the cube might organize sales by region, data analysts can also “drill-down” into layers for sales by state/province, city and/or specific stores. This historical, aggregated data for OLAP is usually stored in a star schema or snowflake schema.
How OLAP systems work
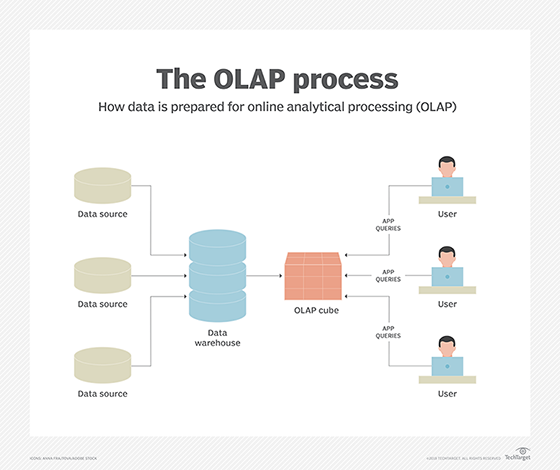
To facilitate this kind of analysis, data is collected from multiple sources and stored in data warehouses, then cleansed and organized into data cubes. Each OLAP cube contains data categorized by dimensions (such as customers, geographic sales region and time period) derived by dimensional tables in the data warehouses. Dimensions are then populated by members (such as customer names, countries and months) that are organized hierarchically.
Analysts can then perform five types of OLAP analytical operations against these multidimensional databases:
- Roll-up. Also known as consolidation, or drill-up, this operation summarizes the data along the dimension.
- Drill-down. This allows analysts to navigate deeper among the dimensions of data. For example, drilling down from “time period” to “years” and “months” to chart sales growth for a product.
- Slice. This enables an analyst to take one level of information for display, such as “sales in 2017.”
- Dice. This allows an analyst to select data from multiple dimensions to analyze, such as “sales of blue beach balls in Iowa in 2017.”
- Pivot. Analysts can gain a new view of data by rotating the data axes of the cube.
OLAP software locates the intersection of dimensions, such as all products sold in the Eastern region above a certain price during a certain time period, and displays them. The result is the measure; each OLAP cube has at least one to perhaps hundreds of measures, which derive from information stored in fact tables in the data warehouse.
OLAP vs. OLTP
Online transaction processing, or OLTP, refers to data-processing methods and software focused on transaction-oriented data and applications.
The main difference between OLAP and OLTP is in the name: OLAP is analytical in nature, and OLTP is transactional.
OLAP tools are designed for multidimensional analysis of data in a data warehouse, which contains both transactional and historical data. In fact, an OLAP server is typically the middle, analytical tier of a data warehousing solution. Common uses of OLAP include data mining and other business intelligence applications, complex analytical calculations, and predictive scenarios, as well as business reporting functions like financial analysis, budgeting, and forecast planning.
OLTP is designed to support transaction-oriented applications by processing recent transactions as quickly and accurately as possible. Common uses of OLTP include ATMs, e-commerce software, credit card payment processing, online bookings, reservation systems, and record-keeping tools.
In practice OLAP and OLTP are not viewed as binary categories, but more like a spectrum. Most real systems usually focus on one of them but provide some solutions or workarounds if the opposite kind of workload is also desired. This situation often forces businesses to operate multiple storage systems that are integrated. This might not be such a big deal, but having more systems increases maintenance costs, and as such the trend in recent years is towards HTAP (Hybrid Transactional/Analytical Processing) when both kinds of workload are handled equally well by a single database management system.
Even if a DBMS started out as a pure OLAP or pure OLTP, it is forced to move in the HTAP direction to keep up with the competition. ClickHouse is no exception. Initially, it has been designed as a fast-as-possible OLAP system and it still does not have full-fledged transaction support, but some features like consistent read/writes and mutations for updating/deleting data have been added.
The fundamental trade-off between OLAP and OLTP systems remains:
- To build analytical reports efficiently it’s crucial to be able to read columns separately, thus most OLAP databases are columnar,
- While storing columns separately increases costs of operations on rows, like append or in-place modification, proportionally to the number of columns (which can be huge if the systems try to collect all details of an event just in case). Thus, most OLTP systems store data arranged by rows.
Reference
- https://en.wikipedia.org/wiki/Online_transaction_processing
- https://en.wikipedia.org/wiki/Online_analytical_processing
- https://www.ibm.com/topics/olap
- https://www.ibm.com/think/topics/olap-vs-oltp
- https://aws.amazon.com/what-is/olap/
- https://aws.amazon.com/compare/the-difference-between-olap-and-oltp/