背景
线程模型
在现代计算机结构中,先后提出过两种线程模型:用户级线程(user-level threads)和内核级线程(kernel-level threads)。
用户级线程(user-level threads)
所谓**用户级线程(user-level threads)**是指,应用程序在操作系统提供的单个控制流的基础上,通过在某些控制点(比如系统调用)上分离出一些虚拟的控制流,从而模拟多个控制流的行为。由于应用程序对指令流的控制能力相对较弱,所以,用户级线程之间的切换往往受线程本身行为以及线程控制点选择的影响,线程是否能公平地获得处理器时间取决于这些线程的代码特征。
而且,支持用户级线程的应用程序代码很难做到跨平台移植,以及对于多线程模型的透明。用户级线程模型的优势是线程切换效率高,因为它不涉及系统内核模式和用户模式之间的切换;另一个好处是应用程序可以采用适合自己特点的线程选择算法,可以根据应用程序的逻辑来定义线程的优先级,当线程数量很大时,这一优势尤为明显。但是,这同样会增加应用程序代码的复杂性。有一些软件包(如POSIXThreads 或Pthreads 库)可以减轻程序员的负担。
内核级线程(kernel-level threads)
内核级线程往往指操作系统提供的线程语义,由于操作系统对指令流有完全的控制能力,甚至可以通过硬件中断来强迫一个进程或线程暂停执行,以便把处理器时间移交给其他的进程或线程,所以,内核级线程有可能应用各种算法来分配处理器时间。线程可以有优先级,高优先级的线程被优先执行,它们可以抢占正在执行的低优先级线程。在支持线程语义的操作系统中,处理器的时间通常是按线程而非进程来分配,
因此,系统有必要维护一个全局的线程表,在线程表中记录每个线程的寄存器、状态以及其他一些信息。然后,系统在适当的时候挂起一个正在执行的线程,选择一个新的线程在当前处理器上继续执行。这里“适当的时候”可以有多种可能,比如:当一个线程执行某些系统调用时,例如像 sleep 这样的放弃执行权的系统函数,或者像 wait 或 select 这样的阻塞函数;硬中断(interrupt)或异常(exception);线程终止时,等等。由于这些时间点的执行代码可能分布在操作系统的不同位置,所以,在现代操作系统中,线程调度(thread scheduling)往往比较复杂,其代码通常分布在内核模块的各处。
内核级线程的好处是,应用程序无须考虑是否要在适当的时候把控制权交给其他的线程,不必担心自己霸占处理器而导致其他线程得不到处理器时间。应用线程只要按照正常的指令流来实现自己的逻辑即可,内核会妥善地处理好线程之间共享处理器的资源分配问题。然而,这种对应用程序的便利也是有代价的,即,所有的线程切换都是在内核模式下完成的,因此,对于在用户模式下运行的线程来说,一个线程被切换出去,以及下次轮到它的时候再被切换进来,要涉及两次模式切换:从用户模式切换到内核模式,再从内核模式切换回用户模式。在 Intel 的处理器上,这种模式切换大致需要几百个甚至上千个处理器指令周期。但是,随着处理器的硬件速度不断加快,模式切换的开销相对于现代操作系统的线程调度周期(通常几十毫秒)的比例正在减小,所以,这部分开销是完全可以接受的。
除了线程切换的开销是一个考虑因素以外,线程的创建和删除也是一个重要的考虑指标。当线程的数量较多时,这部分开销是相当可观的。虽然线程的创建和删除比起进程要轻量得多,但是,在一个进程内建立起一个线程的执行环境,例如,分配线程本身的数据结构和它的调用栈,完成这些数据结构的初始化工作,以及完成与系统环境相关的一些初始化工作,这些负担是不可避免的。另外,当线程数量较多时,伴随而来的线程切换开销也必然随之增加。所以,当应用程序或系统进程需要的线程数量可能比较多时,通常可采用线程池技术作为一种优化措施,以降低创建和删除线程以及线程频繁切换而带来的开销。
在支持内核级线程的系统环境中,进程可以容纳多个线程,这导致了多线程程序设计(multithreaded programming)模型。由于多个线程在同一个进程环境中,它们共享了几乎所有的资源,所以,线程之间的通信要方便和高效得多,这往往是进程间通信(IPC,Inter-Process Communication)所无法比拟的,但是,这种便利性也很容易使线程之间因同步不正确而导致数据被破坏,而且,这种错误存在不确定性,因而相对来说难以发现和调试。
什么是协程(Coroutines)
**协程(Coroutines)**是一种用户态的轻量级线程,协程比线程更加轻量级。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
协程通过协作而不是抢占来进行切换。相对于进程或者线程,协程所有的操作都可以在用户态完成,创建和切换的消耗更低。总的来说,协程为协同任务提供了一种运行时抽象,这种抽象非常适合于协同多任务调度和数据流处理。在现代操作系统和编程语言中,因为用户态线程切换代价比内核态线程小,协程成为了一种轻量级的多任务模型。
从编程角度上看,协程的思想本质上就是控制流的主动让出(yield)和恢复(resume)机制,迭代器常被用来实现协程,所以大部分的语言实现的协程中都有 yield 关键字,比如 Python、PHP、Lua。但也有特殊比如 Go 就使用的是通道来通信。
协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
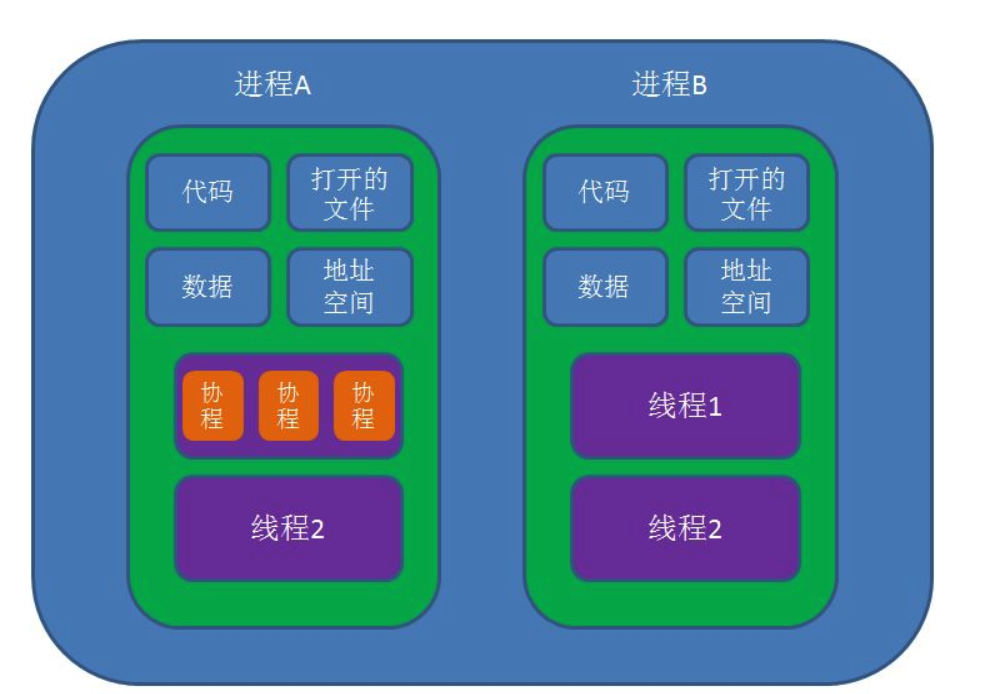
最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
既然协程这么好,它到底是怎么来使用的呢?
由于 Java 的原生语法中并没有实现协程(某些开源框架实现了协程,但是很少被使用),所以我们来看一看 python 当中对协程的实现案例,同样以生产者消费者模式为例:
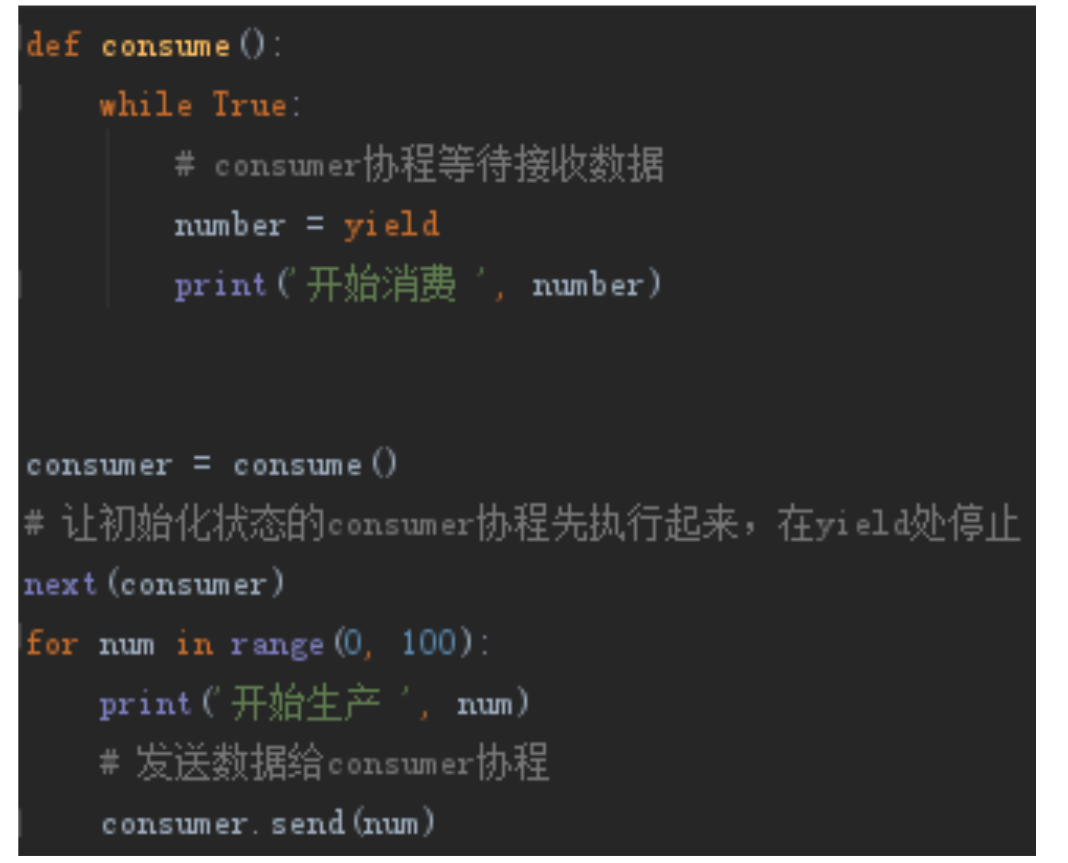
这段代码十分简单,即使没用过python的小伙伴应该也能基本看懂。
代码中创建了一个叫做consumer的协程,并且在主线程中生产数据,协程中消费数据。
其中 yield 是python当中的语法。当协程执行到yield关键字时,会暂停在那一行,等到主线程调用send方法发送了数据,协程才会接到数据继续执行。
但是,yield让协程暂停,和线程的阻塞是有本质区别的。协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进行切换。
因此,协程的开销远远小于线程的开销。
协程的应用
有哪些编程语言应用到了协程呢?我们举几个栗子:
Lua语言
Lua从5.0版本开始使用协程,通过扩展库coroutine来实现。
Python语言
正如刚才所写的代码示例,python可以通过 yield/send 的方式实现协程。在python 3.5以后, async/await 成为了更好的替代方案。
ref https://swsmile.info/post/python-coroutine/
Go语言
Go语言对协程的实现非常强大而简洁,可以轻松创建成百上千个协程并发执行。
Java语言
如上文所说,Java语言并没有对协程的原生支持,但是某些开源框架模拟出了协程的功能,有兴趣的小伙伴可以看一看Kilim框架的源码:
https://github.com/kilim/kilim
Reference
- 漫画:什么是协程? - IT程序猿 - https://www.itcodemonkey.com/article/4620.html
- 协程 - http://www.syyong.com/Basis-of-computer/Coroutine.html