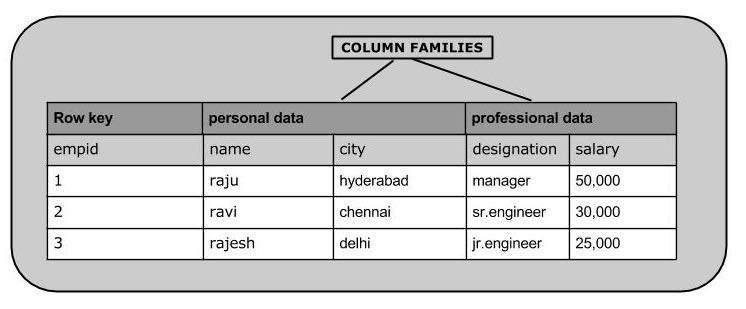
HBase
HBase is an open-source non-relational distributed database
Use Apache HBase when you need random, realtime read/write access to your Big Data. This project’s goal is the hosting of very large tables – billions of rows X millions of columns – atop clusters of commodity hardware.
Apache HBase is an open-source, NoSQL, distributed big data store. It enables random, strictly consistent, real-time access to petabytes of data.
HBase is a column-oriented, non-relational database. This means that data is stored in individual columns, and indexed by a unique row key.
...