Pre-envolution
Consider the world’s simplest database, implemented as two Bash functions:
#!/bin/bash
db_set () { echo "$1,$2" >> database }
db_get () { grep "^$1," database | sed -e "s/^$1,//" | tail -n 1 }
These two functions implement a key-value store. You can call db_set key value, which will store key and value in the database. The key and value can be (almost) anything you like—for example, the value could be a JSON document. You can then call db_get key, which looks up the most recent value associated with that particular key and returns it.
And it works:
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}'
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
The underlying storage format is very simple: a text file where each line contains a key-value pair, separated by a comma (roughly like a CSV file, ignoring escaping issues). Every call to db_set appends to the end of the file, so if you update a key several times, the old versions of the value are not overwritten—you need to look at the last occurrence of a key in a file to find the latest value (hence the tail -n 1 in db_get):
$ db_set 42
'{"name":"San Francisco","attractions":["Exploratorium"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Exploratorium"]}
$ cat database
123456,{"name":"London","attractions":["Big Ben","London Eye"]} 42,{"name":"San Francisco","attractions":["Golden Gate Bridge"]} 42,{"name":"San Francisco","attractions":["Exploratorium"]}
Our db_set function actually has pretty good performance for something that is so simple, because appending to a file is generally very efficient. Similarly to what db_set does, many databases internally use a log, which is an append-only data file. Real databases have more issues to deal with (such as concurrency control, reclaiming disk space so that the log doesn’t grow forever, and handling errors and partially written records), but the basic principle is the same.
On the other hand, our db_get function has terrible performance if you have a large number of records in your database. Every time you want to look up a key, db_get has to scan the entire database file from beginning to end, looking for occurrences of the key. In algorithmic terms, the cost of a lookup is O(n): if you double the number of records n in your database, a lookup takes twice as long. That’s not good.
In order to efficiently find the value for a particular key in the database, we need a different data structure: an index. We will look at a range of indexing structures and see how they compare; the general idea behind them is to keep some additional metadata on the side, which acts as a signpost and helps you to locate the data you want. If you want to search the same data in several different ways, you may need several different indexes on different parts of the data.
An index is an additional structure that is derived from the primary data. Many databases allow you to add and remove indexes, and this doesn’t affect the contents of the database; it only affects the performance of queries. Maintaining additional structures incurs overhead, especially on writes. For writes, it’s hard to beat the performance of simply appending to a file, because that’s the simplest possible write operation. Any kind of index usually slows down writes, because the index also needs to be updated every time data is written.
This is an important trade-off in storage systems: well-chosen indexes speed up read queries, but every index slows down writes. For this reason, databases don’t usually index everything by default, but require you—the application developer or database administrator—to choose indexes manually, using your knowledge of the application’s typical query patterns. You can then choose the indexes that give your application the greatest benefit, without introducing more overhead than necessary.
Hash Indexes
Let’s say our data storage consists only of appending to a file, as in the preceding example. Then the simplest possible indexing strategy is this: keep an in-memory hash map where every key is mapped to a byte offset in the data file—the location at which the value can be found, as illustrated below. Whenever you append a new key-value pair to the file, you also update the hash map to reflect the offset of the data you just wrote (this works both for inserting new keys and for updating existing keys). When you want to look up a value, use the hash map to find the offset in the data file, seek to that location, and read the value.
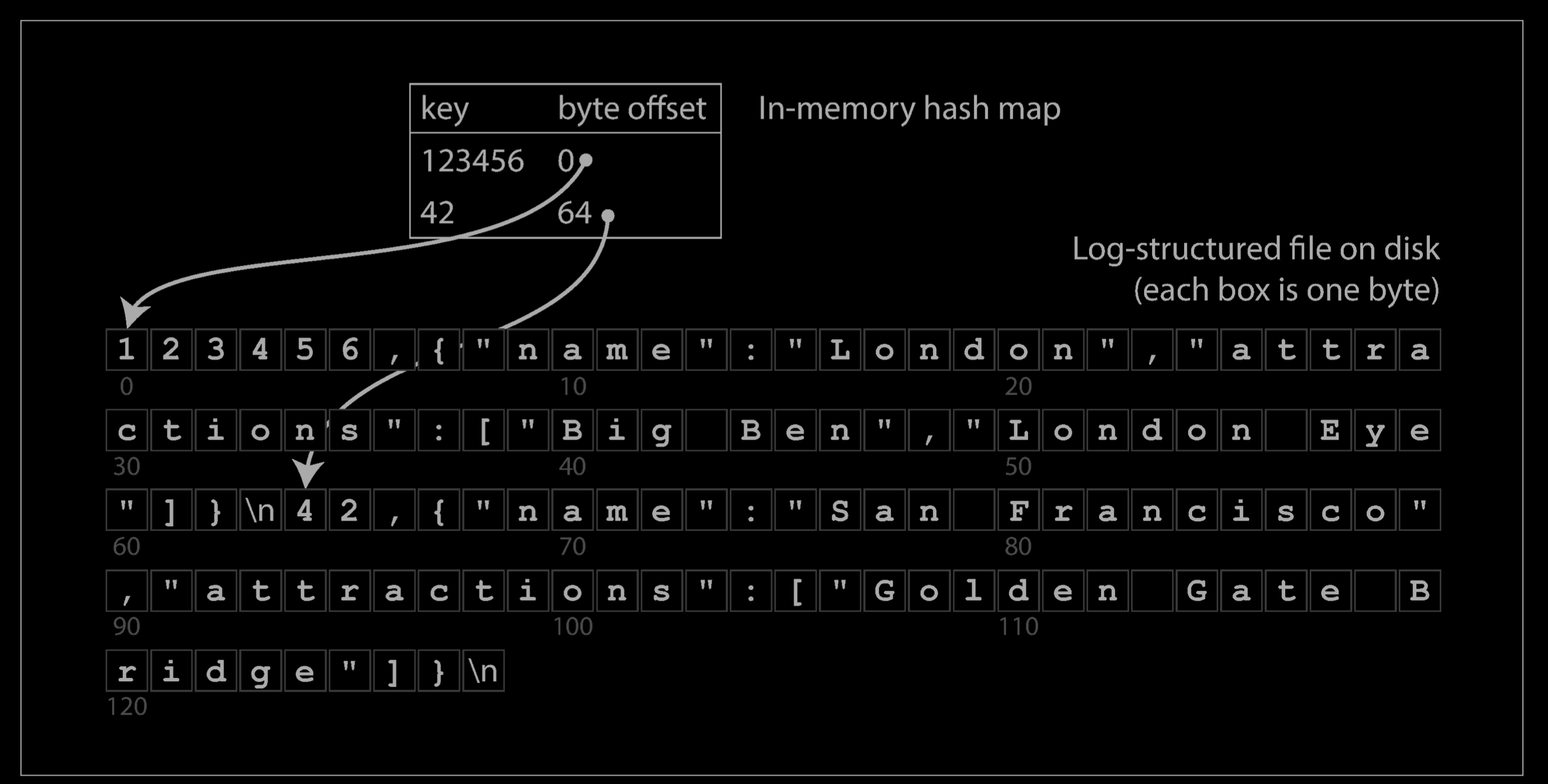
This may sound simplistic, but it is a viable approach. In fact, this is essentially what Bitcask (the default storage engine in Riak) does. Bitcask offers high-performance reads and writes, subject to the requirement that all the keys fit in the available RAM, since the hash map is kept completely in memory. The values can use more space than there is available memory, since they can be loaded from disk with just one disk seek. If that part of the data file is already in the filesystem cache, a read doesn’t require any disk I/O at all.
A storage engine like Bitcask is well suited to situations where the value for each key is updated frequently. For example, the key might be the URL of a cat video, and the value might be the number of times it has been played (incremented every time someone hits the play button). In this kind of workload, there are a lot of writes, but there are not too many distinct keys—you have a large number of writes per key, but it’s feasible to keep all keys in memory.
As described so far, we only ever append to a file—so how do we avoid eventually running out of disk space? A good solution is to break the log into segments of a certain size by closing a segment file when it reaches a certain size, and making subsequent writes to a new segment file. We can then perform compaction on these segments, as illustrated below Compaction means throwing away duplicate keys in the log, and keeping only the most recent update for each key.
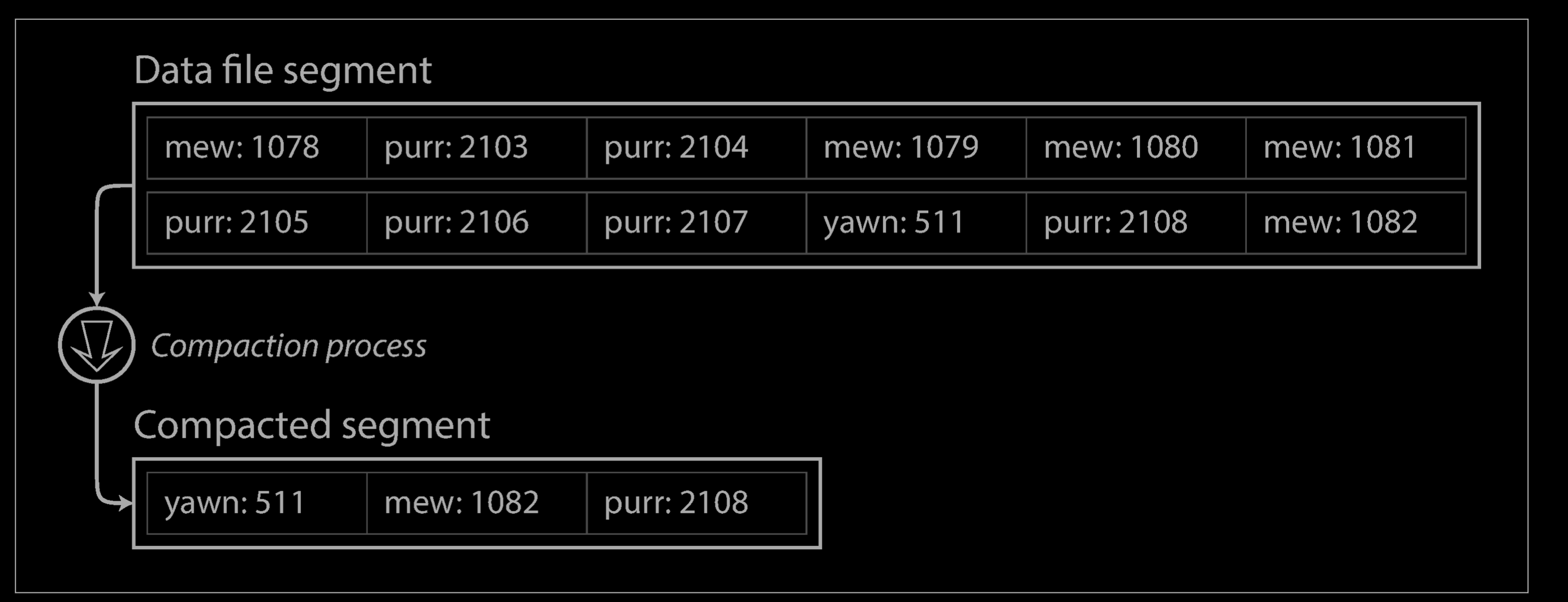
Moreover, since compaction often makes segments much smaller (assuming that a key is overwritten several times on average within one segment), we can also merge several segments together at the same time as performing the compaction, as shown below. Segments are never modified after they have been written, so the merged segment is written to a new file. The merging and compaction of frozen segments can be done in a background thread, and while it is going on, we can still continue to serve read and write requests as normal, using the old segment files. After the merging process is complete, we switch read requests to using the new merged segment instead of the old segments—and then the old segment files can simply be deleted.

Each segment now has its own in-memory hash table, mapping keys to file offsets. In order to find the value for a key, we first check the most recent segment’s hash map; if the key is not present we check the second-most-recent segment, and so on. The merging process keeps the number of segments small, so lookups don’t need to check many hash maps.
Lots of detail goes into making this simple idea work in practice. Briefly, some of the issues that are important in a real implementation are:
- File format: CSV is not the best format for a log. It’s faster and simpler to use a binary format that first encodes the length of a string in bytes, followed by the raw string (without need for escaping).
- Deleting records: If you want to delete a key and its associated value, you have to append a special deletion record to the data file (sometimes called a tombstone). When log segments are merged, the tombstone tells the merging process to discard any previous values for the deleted key.
- Crash recovery: If the database is restarted, the in-memory hash maps are lost. In principle, you can restore each segment’s hash map by reading the entire segment file from beginning to end and noting the offset of the most recent value for every key as you go along. However, that might take a long time if the segment files are large, which would make server restarts painful. Bitcask speeds up recovery by storing a snapshot of each segment’s hash map on disk, which can be loaded into memory more quickly.
- Partially written records: The database may crash at any time, including halfway through appending a record to the log. Bitcask files include checksums, allowing such corrupted parts of the log to be detected and ignored.
- Concurrency control: As writes are appended to the log in a strictly sequential order, a common implementation choice is to have only one writer thread. Data file segments are append-only and otherwise immutable, so they can be read concurrently by multiple threads.
An append-only log seems wasteful at first glance: why don’t you update the file in place, overwriting the old value with the new value? But an append-only design turns out to be good for several reasons:
- Appending and segment merging are sequential write operations, which are generally much faster than random writes, especially on magnetic spinning-disk hard drives. To some extent sequential writes are also preferable on flash-based solid state drives (SSDs).
- Concurrency and crash recovery are much simpler if segment files are appendonly or immutable. For example, you don’t have to worry about the case where a crash happened while a value was being overwritten, leaving you with a file containing part of the old and part of the new value spliced together.
- Merging old segments avoids the problem of data files getting fragmented over time.
However, the hash table index also has limitations:
- The hash table must fit in memory, so if you have a very large number of keys, you’re out of luck. In principle, you could maintain a hash map on disk, but unfortunately it is difficult to make an on-disk hash map perform well. It requires a lot of random access I/O, it is expensive to grow when it becomes full, and hash collisions require fiddly logic.
- Range queries are not efficient. For example, you cannot easily scan over all keys between kitty00000 and kitty99999—you’d have to look up each key individually in the hash maps.
In the next section we will look at an indexing structure that doesn’t have those limitations.
Background
During the 1990s, disk bandwidth, processor speed and main memory capacity were increasing at a rapid rate.
With increase in memory capacity, more items could now be cached in memory for reads. As a result, read workloads were mostly absorbed by the operating system page cache. However, disk seek times were still high due to the seek and rotational latency of physical R/W head in a spinning disk. A spinning disk needs to move to a given track and sector to write the data. In the case of random I/O, with frequent read and write operations, the movement of physical disk head becomes more than the time it takes to write the data. From the LFS paper, traditional file systems utilizing a spinning disk, spends only 5-10% of disk’s raw bandwidth whereas LFS permits about 65-75% in writing a new data (rest is for compaction). Traditional file systems write data at multiple places: the data block, recovery log and in-place updates to any metadata. The only bottleneck in file systems now, were during writes. As a result, there was a need to reduce writes and do less random I/O in file systems. LFS came with the idea that why not write everythng in a single log (even the metadata) and treat that as a single source of truth.
Log structured file systems treat your whole disk as a log. Data blocks are written to disk in an append only manner along with their metadata (inodes). Before appending them to disk, the writes are buffered in memory to reduce the overhead of disk seeks on every write. On reaching a certain size, they are then appended to disk as a segment (64kB-1MB). A segment contains data blocks containing changes to multitude of files along with their inodes. At the same time on every write, an inode map (imap) is also updated to point to the newly written inode number. The imap is also then appended to the log on every such write so it’s a just single seek away.
We’re not going too deep on LFS, but you get the idea. LSM Tree steals the idea of append only style updates in a log file and write buffering and has been adopted for use as a storage backend for a lot of write intensive key value database systems. Now that we know of their existence, let’s look at them more closely.
Log-structured merge-trees (LSM trees)
A log-structured merge-tree (LSM tree) is a data structure typically used when dealing with write-heavy workloads. The write path is optimized by only performing sequential writes.
- LSM trees are the core data structure behind many modern NoSQL Databases e.g. BigTable, Cassandra, HBase, RocksDB, and DynamoDB.
- LSM trees are used in data stores such as Apache AsterixDB, Bigtable, HBase, LevelDB, Apache Accumulo, SQLite4 Tarantool, RocksDB, WiredTiger, Apache Cassandra, InfluxDB and ScyllaDB.
...